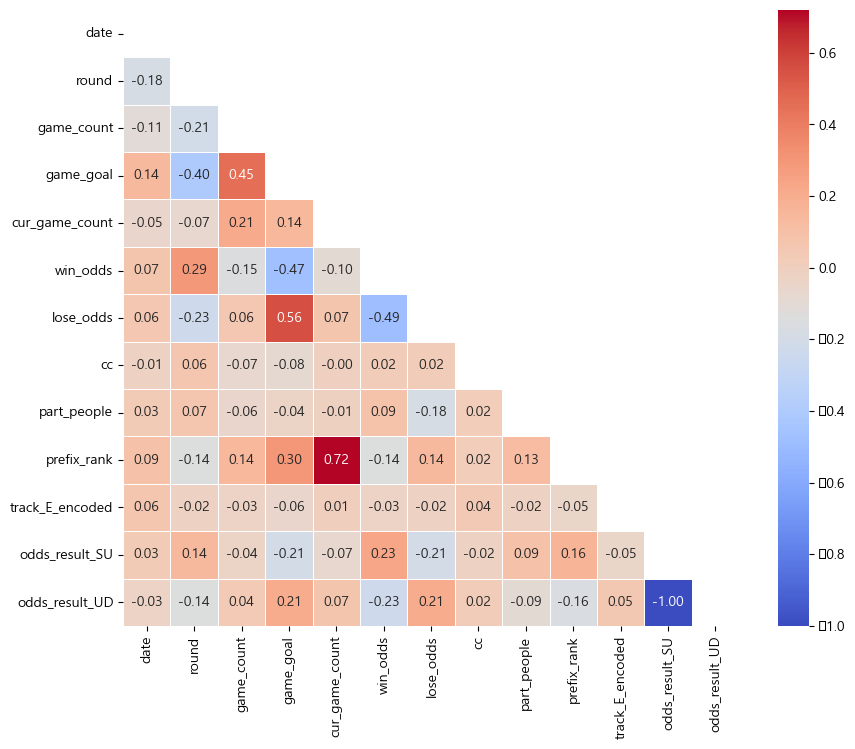
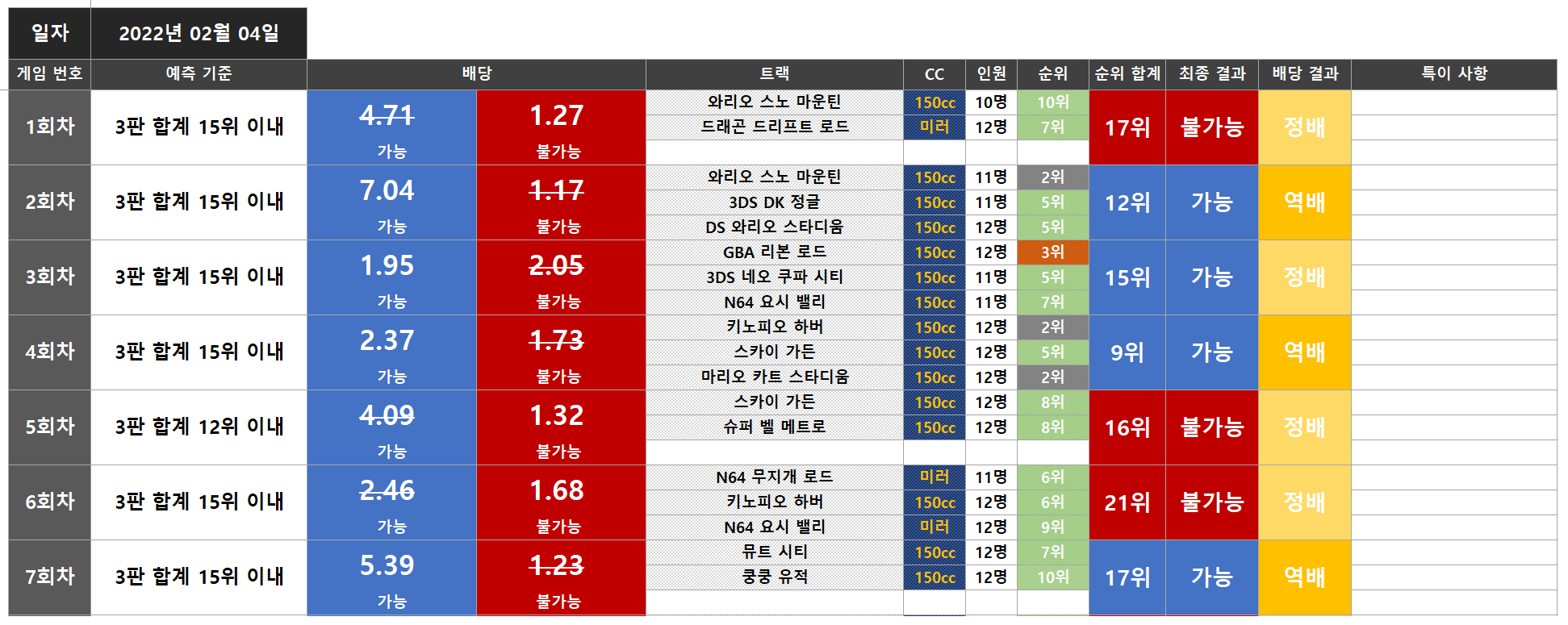
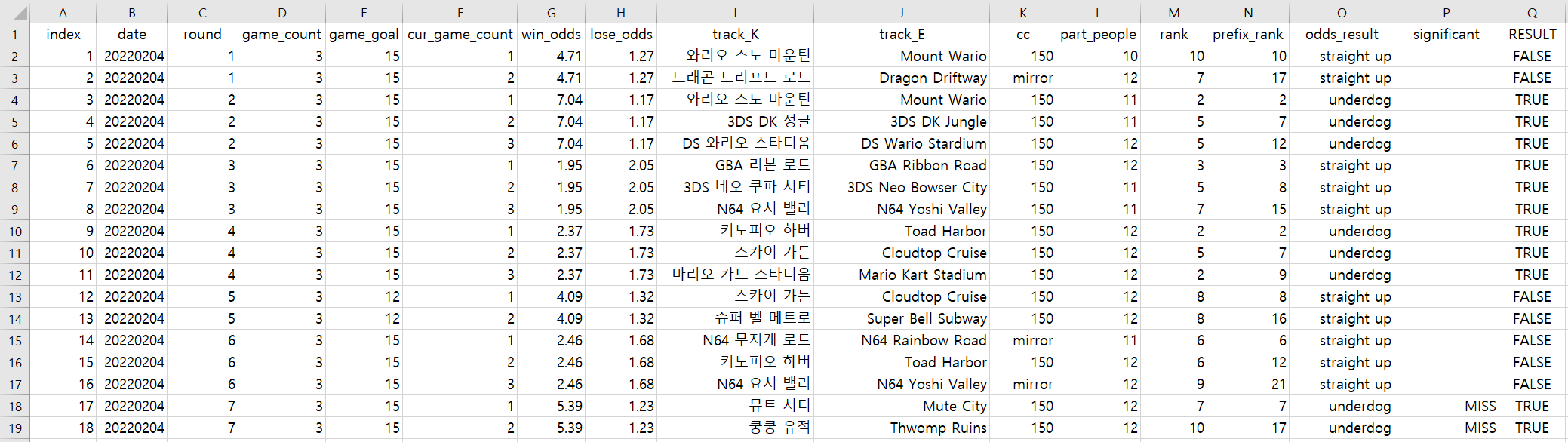
구현 사항 - 좌측 frame에 24 * 4만큼 버튼 삽입 성공 - 버튼마다 이미지를 설정하고 center로 위치 조절 성공 - garbage collector가 이미지를 지우던 문제 사항 해결
추가 예정 - separtor를 기준으로 좌측 frame에는 맵 코스를, 우측 frame에는 예측 기능을 추가할 예정 - 스크롤뷰로 마리오카트 코스 볼 수 있게 구현해야 함 - 좌측 frame에 여백 없애야 함 - 상단에서 검색 기능 추가해야 함 - 내부 코드 깔끔하게 만들기(현재는 extract.py 파일에서 하나로 관리 중)
2024.05.27(월)
구현 사항 - 전체적인 기하 관리(rowconfigure, columnconfigure) 완료 - 좌측 frame에서 상단 부분에 Filters로 맵 검색 프레임 추가 완료 - 이미지 버튼들을 하나의 Course frame에서 관리하도록 변경 - Course Frame을 스크롤 뷰로 볼 수 있게끔 변경
추가 예정 - 맵 검색 기능은 미구현, trie 자료구조를 활용하여 이미지 버튼 보이는 기능 추가하기 - 이미지 버튼 아래에 맵 이름에 해당하는 label 추가하기 - 우측 frame에서 예측할 수 있는 frame 구조 설계하기
2024.05.29(수)
구현 사항
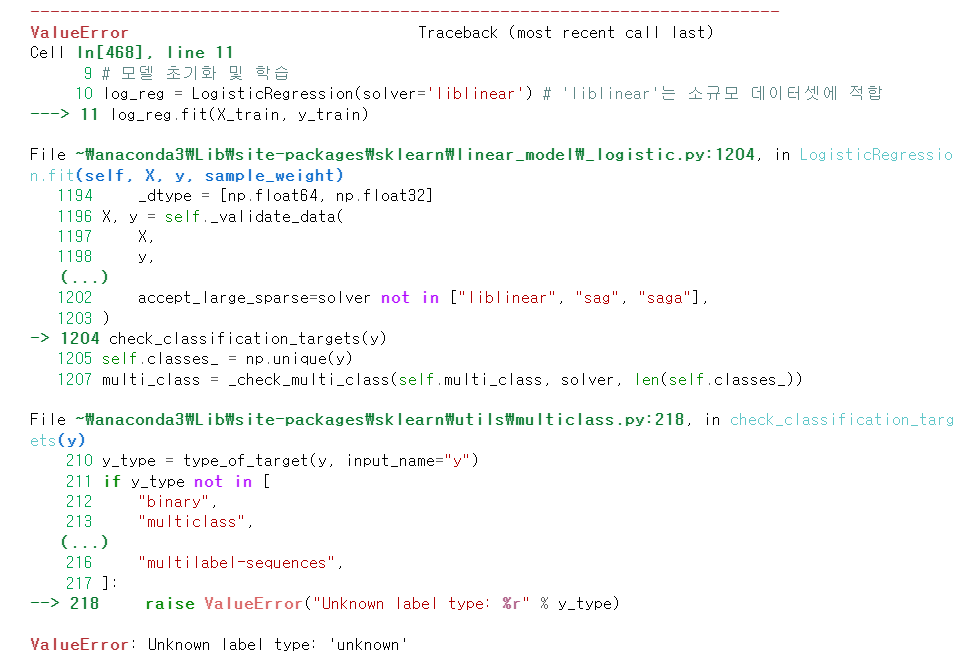
- ConsoleWindow가 프로그램에 나오지 않던 문제를 해결
- PlaygroundUI의 Config 값을 잘못 던져주어 ValueError가 ConsoleWindow에 나오던 문제를 해결
- 우측 부분에 예측에 사용할 Prediciton frame과 결과에 사용할 Reuslt frame 추가 완료
- 버튼을 눌렀을 때, 맵 이름 Entry에 맵 번호가 들어가도록 command=launch 기능 추가 완료
추가 예정
- 맵 검색 기능은 미구현, trie 자료구조를 활용하여 이미지 버튼 보이는 기능 추가하기 - 이미지 버튼 아래에 맵 이름에 해당하는 label 추가하기
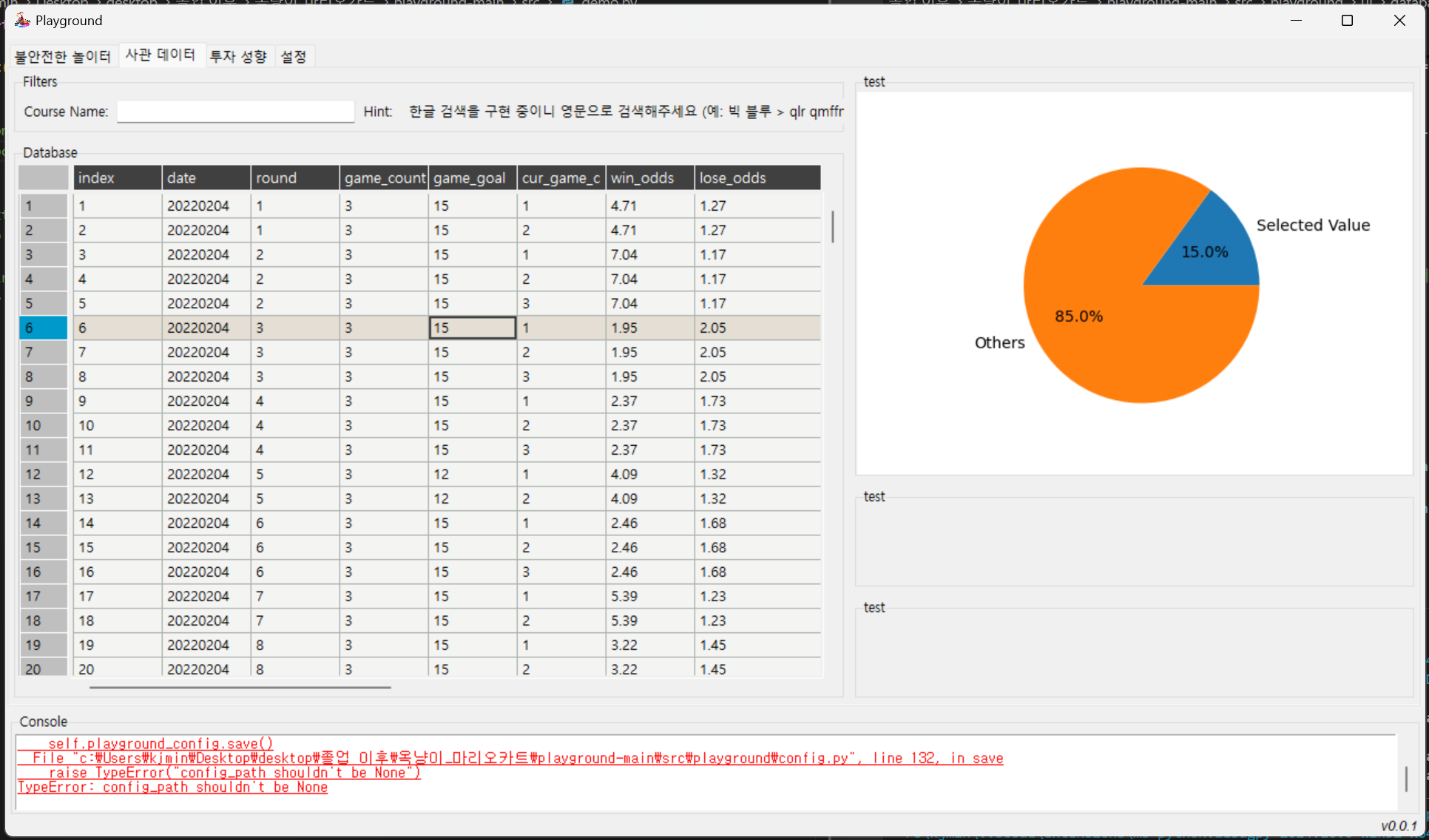
- ConsoleWindow에 현재 발생하는 에러 해결하기
└ config_path 문제인데, 이는 cli.py에서 PlaygroundUI를 시작할 때 값을 주어야 함. 최종 부분에서 해결해야 하는 상황
- Prediction과 Result frame이 현재 play.py에 모여있는데, SRP에 따라 코드 쪼개기
- 맵 번호에 따른 입력값 자동으로 넣을 수 있게 추가하기
- 불안전한 놀이터! button의 기능(command) 추가하기
- 데이터베이스 추가하기
2024.06.05(수)
구현 사항
- Entry 텍스트 입력에 따른 이미지 버튼 filtering 기능 추가 완료
- 이미지 버튼을 filtering함에 따라 grid를 재배치하도록 작성(공백없이 왼쪽 위에서부터 채움)
- Course frame과 Prediction frame과 Result frame을 각각 다른 파일로 분리 완료
추가 예정
- 이미지 버튼 filtering 키워드 다양화하기
└ 경기장 이름 국문/영문, 그랑프리 종류 국문/영문, 컵 종류 국문/영문
└ 국문 검색 방법은 unicode 변환, kmp 알고리즘, trie 자료구조를 복합적으로 응용할 예정
- 이미지 버튼 이름(넘버링)을 filtering 키워드로 해싱하기
- Entry에서 텍스트를 입력할 때 IME 문제로 한글 하나 입력이 아닌 한 글자 단위로 입력되는 현상 해결
└ <<CompositionEnd>> 이벤트에 대해서 알아보기 - 이미지 버튼 아래에 맵 이름에 해당하는 label 추가하기
- ConsoleWindow에 현재 발생하는 에러 해결하기
└ config_path 문제와 packs_frame(render_frame) 함수 문제
- 불안전한 놀이터! button의 기능(command) 추가하기
- 데이터베이스 추가하기
2024.06.06(목)
실제 이미지(X), 그림판으로 그려본 예상 도안(O)
예시 도안
- 옥냥이의 마리오카트 그동안의 기록을 확인할 수 있는 데이터베이스 탭
- 검색 탭에서는 Playground와 같은 검색 알고리즘 도입
추가 예정
- 이미지 버튼 filtering 키워드 다양화하기
└ 경기장 이름 국문/영문, 그랑프리 종류 국문/영문, 컵 종류 국문/영문
└ 국문 검색 방법은 unicode 변환, kmp 알고리즘, trie 자료구조를 복합적으로 응용할 예정
- 이미지 버튼 이름(넘버링)을 filtering 키워드로 해싱하기
- Entry에서 텍스트를 입력할 때 IME 문제로 한글 하나 입력이 아닌 한 글자 단위로 입력되는 현상 해결
└ <<CompositionEnd>> 이벤트에 대해서 알아보기 - 이미지 버튼 아래에 맵 이름에 해당하는 label 추가하기
- ConsoleWindow에 현재 발생하는 에러 해결하기
└ config_path 문제와 packs_frame(render_frame) 함수 문제
- 불안전한 놀이터! button의 기능(command) 추가하기
- 데이터베이스 추가하기
2024.06.07(금)
구현 사항
- 예시 도안에 따른 Database Tab의 Frame 구축
- SRP에 따라 Filter Frame, Database Frame, test Frame으로 분해하여 생성
추가 예정
- 이미지 버튼 filtering 키워드 다양화하기
└ 경기장 이름 국문/영문, 그랑프리 종류 국문/영문, 컵 종류 국문/영문
└ 국문 검색 방법은 unicode 변환, kmp 알고리즘, trie 자료구조를 복합적으로 응용할 예정
- 이미지 버튼 이름(넘버링)을 filtering 키워드로 해싱하기
- Entry에서 텍스트를 입력할 때 IME 문제로 한글 하나 입력이 아닌 한 글자 단위로 입력되는 현상 해결
└ <<CompositionEnd>> 이벤트에 대해서 알아보기 - 이미지 버튼 아래에 맵 이름에 해당하는 label 추가하기
- ConsoleWindow에 현재 발생하는 에러 해결하기
└ config_path 문제와 packs_frame(render_frame) 함수 문제
- 불안전한 놀이터! button의 기능(command) 추가하기
- 데이터베이스 추가하기
2024.06.11(화)
구현 사항
- 영문 검색 기능 추가
2024.06.12(수)
구현 사항
- 이미지 버튼 label 추가
- korean exp-reg 구현 중
2024.06.17(월)
구현 사항
- korean exp-reg 구현 완료
- 초성 검색(initial_search), 유사 검색(fuzzy), 영문 검색(_eng_to_kor) 기능 포함
- PyQt5의 QLineEdit에서 event(type: QInputMethodEvent)를 이용하면 event.preeditString()으로는 구현 가능
- tkinter(mainloop)와 PyQt5()의 이벤트 루프가 달라 혼용이 어려움
- 도저히 방법을 못 찾고 생각이 안 나서 discuss.python에 질문을 올려둔 상태
다음 개발 사항
1. Classification과 Regression 인공지능 모델 개발 완료 후 pkl로 프로그램에 탑재하기
2. Database 탭에서 그간 옥냥이가 한 마리오 카트 결과 삽입하기
2024.06.20(목)
구현 사항
- discuss.python에서도 답변을 듣지 못해, 현재 귀도 반 로섬에게 메일을 보내놓음
- 임시방편으로 eng_to_kor 함수를 사용하여 '영문 입력 > 국문 검색' 방법으로 검색 기능 구현 완료
구현 사항
- github api releases 이후 version.py에서 버전 및 업데이트 관리가 가능하도록 해당 링크 추가
2024.06.27(목)
Track 1 Frame 제작
Track 2 Frame 제작
Result 제작
2024.07.02(화)
테스트용 pkl 예측 모델 탑재
2024.08.10(토)
일부 한글화 진행
database 추가 완료
초기화 버튼 추가 완료
2024.08.13(화)
Tab name 변경
CustomTable 클래스 구현
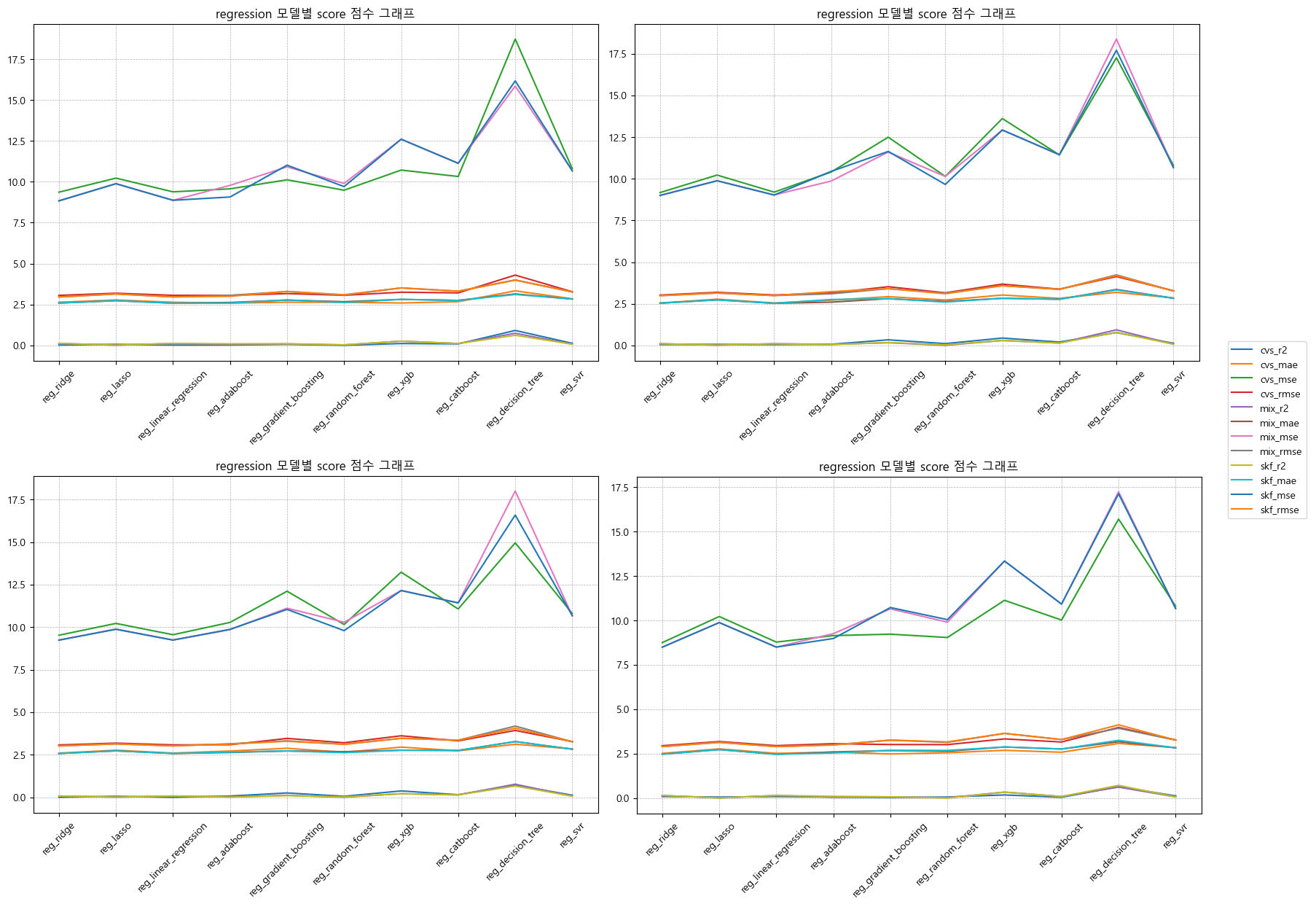
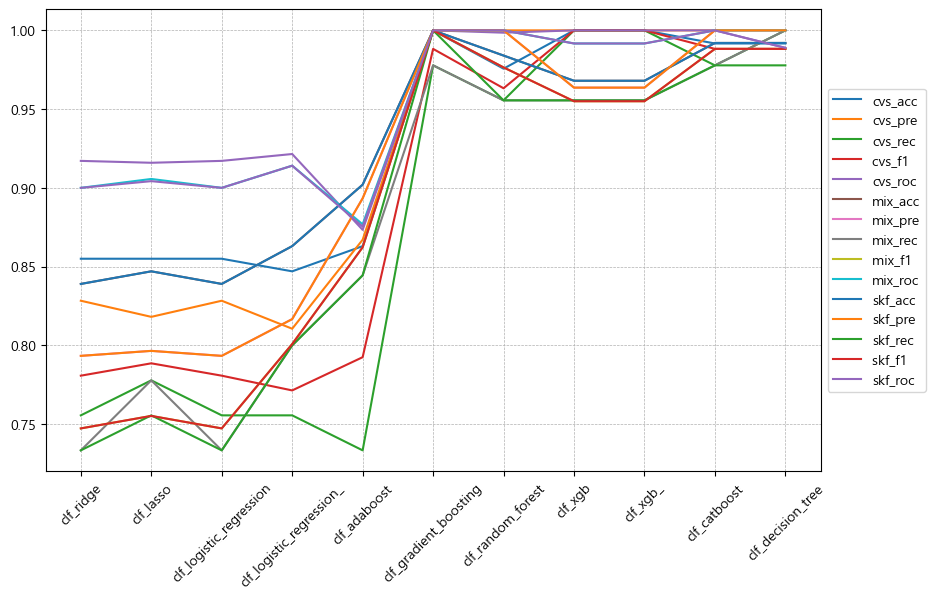
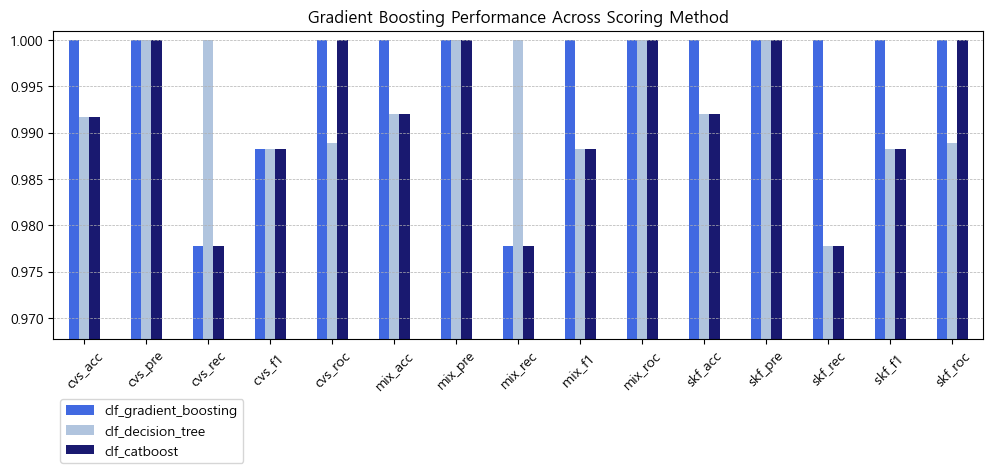
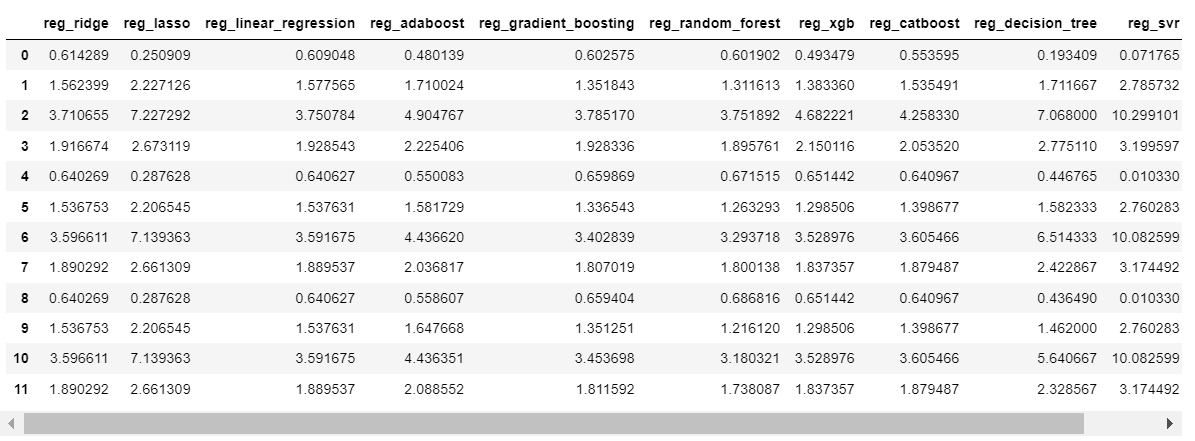
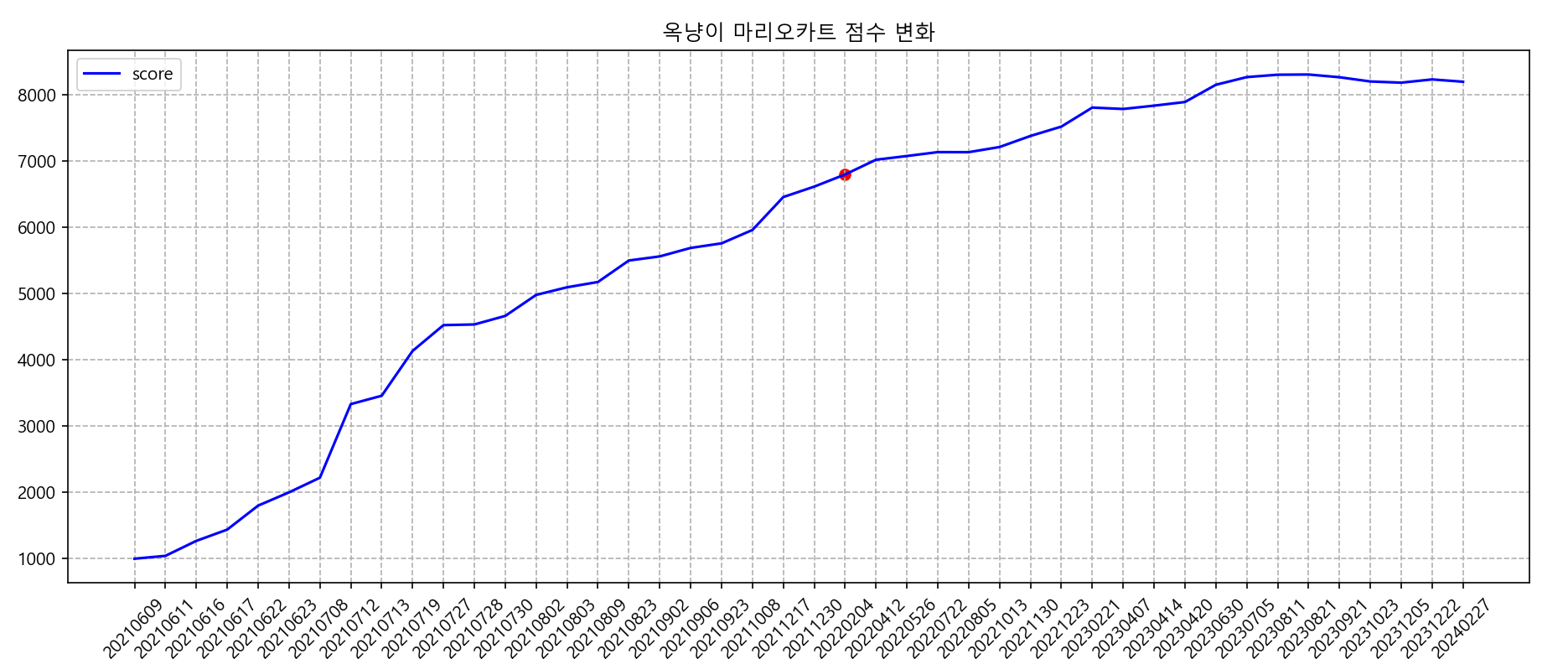
key bind으로 데이터 셀 클릭 시 우측에 그래프 그리기 구현
어떤 그래프를 그릴지 명확하게 알려주기
그래프 사이즈 커지지 않게 조절하기
2024.08.18(일)
전체적인 프로그램 흐름 및 방향성 잡기
tab은 총 다섯 개(토토 예측, 옥냥이 기록, 개인 토토 기록, 개인 토토 기록으로 성향 파악하기, 설정)
토토 예측 - tkinter GUI 익히기, AI 모델에 대한 전반적인 이해도 높이기 및 구현하기
옥냥이 기록 - 데이터 관리 및 SQL, pandas 문법 익히기, 데이터 시각화 익히기
성향 파악 - 금융권 도메인 지식 이해하기, 데이터 시각화 및 정리하기
개인 토토 기록,설정, 전체 - Python OOP에 대한 공부 및 구현 익히기
Track 1과 Track 2 프레임을 하나로 통합(필수, 선택을 골라서 그에 맞는 모델을 골라서 결과 예측)
Result Save 프레임을 추가하여 본인이 행한 결과를 저장하게끔 구현 예정
'불안전한 놀이터' tab과 '개인 투자 기록' tab 연동 성공
2024.08.19(월)
'투자 성향' 파악하기 탭 frame 작성
cli.py, pyinstaller-cli.py, build-exe.py, config.py 파일 수정 및 제작
(exe 파일을 만들기 위해 필요한 파일들)
해당 파일에서는 API 서버와 통신을 위한 비동기 라이브러리 async, hypercorn 사용, 공부 중
5690 INFO: Copying bootloader EXE to C:\Users\kjmin\Desktop\desktop\졸업 이후\옥냥이_마리오카트\playground-main\build\playground\playground.exe
5764 INFO: Copying icon to EXE
Traceback (most recent call last):
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\win32ctypes\pywin32\pywintypes.py", line 33, in pywin32error
yield
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\win32ctypes\pywin32\win32api.py", line 209, in BeginUpdateResource
return _resource._BeginUpdateResource(filename, delete)
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\win32ctypes\core\ctypes\_util.py", line 39, in check_null
raise make_error(function, function_name)
OSError: [WinError 225] 파일에 바이러스 또는 기타 사용자 동의 없이 설치된 소프트웨어가 있기 때문에 작업이 완료되지 않았습니다.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\Scripts\pyinstaller.exe\__main__.py", line 7, in <module>
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\__main__.py", line 228, in _console_script_run
run()
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\__main__.py", line 212, in run
run_build(pyi_config, spec_file, **vars(args))
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\__main__.py", line 69, in run_build
PyInstaller.building.build_main.main(pyi_config, spec_file, **kwargs)
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\building\build_main.py", line 1186, in main
build(specfile, distpath, workpath, clean_build)
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\building\build_main.py", line 1126, in build
exec(code, spec_namespace)
File "C:\Users\kjmin\Desktop\desktop\졸업 이후\옥냥이_마리오카트\playground-main\playground.spec", line 19, in <module>
exe = EXE(
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\building\api.py", line 643, in __init__
self.__postinit__()
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\building\datastruct.py", line 184, in __postinit__
self.assemble()
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\building\api.py", line 756, in assemble
self._retry_operation(icon.CopyIcons, build_name, self.icon)
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\building\api.py", line 1018, in _retry_operation
return func(*args)
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\utils\win32\icon.py", line 212, in CopyIcons
return CopyIcons_FromIco(dstpath, [srcpath])
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\PyInstaller\utils\win32\icon.py", line 144, in CopyIcons_FromIco
hdst = win32api.BeginUpdateResource(dstpath, 0)
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\win32ctypes\pywin32\win32api.py", line 208, in BeginUpdateResource
with _pywin32error():
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\contextlib.py", line 153, in __exit__
self.gen.throw(typ, value, traceback)
File "C:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\site-packages\win32ctypes\pywin32\pywintypes.py", line 37, in pywin32error
raise error(exception.winerror, exception.function, exception.strerror)
win32ctypes.pywin32.pywintypes.error: (225, 'BeginUpdateResourceW', '파일에 바이러스 또는 기타 사용자 동 의 없이 설치된 소프트웨어가 있기 때문에 작업이 완료되지 않았습니다.')
Traceback (most recent call last):
File "c:\Users\kjmin\Desktop\desktop\졸업 이후\옥냥이_마리오카트\playground-main\build-exe.py", line 81, in <module>
main()
File "c:\Users\kjmin\Desktop\desktop\졸업 이후\옥냥이_마리오카트\playground-main\build-exe.py", line 69, in main
run_pyinstaller(args.debug)
File "c:\Users\kjmin\Desktop\desktop\졸업 이후\옥냥이_마리오카트\playground-main\build-exe.py", line 46, in run_pyinstaller
subprocess.check_call(pyinstaller_args)
File "c:\Users\kjmin\AppData\Local\Programs\Python\Python310\lib\subprocess.py", line 369, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['pyinstaller.exe', 'C:\\Users\\kjmin\\Desktop\\desktop\\졸업 이 후\\옥냥이_마리오카트\\playground-main\\pyinstaller-cli.py',
'--add-data', 'src/playground/VERSION;.', '--add-data', 'src/playground/static;static', '--name=playground',
'--icon=C:\\Users\\kjmin\\Desktop\\desktop\\졸업 이후\\옥냥이_마리오카트\\playground-main\\src\\playground\\static\\images\\icon.ico', '--clean', '--onedir', '--noconfirm', '--noconsole']'
returned non-zero exit status 1.
build-exe.py로 exe 파일 생성 시 발생하는 오류
원인 예측 1. OSError [WinError 225] 바이러스 취급 및 사용자 권한 부족
원인 예측 2. win32ctypes.pywin32.pywintypes.error 파일 리소스 업데이트 시도 실패
# Correct
import os
import sys
# Wrong
import os, sys
# okay to say this though
from subprocess import Popen, PIPE
import하는 라이브러리는 줄을 구분해야 한다.
하지만 하나의 라이브러리에서 다른 패키지나 모듈을 적는 것은 허용한다.
# Standard library imports
import os
import sys
# Related third party imports
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Local application/library specific imports
from local_module import local_class
from local_package import local_function
import는 모듈의 주석이나 docstring 뒤, 최상단에 위치해야 한다.
import는 standard - third party - local 순서대로 그룹화 해야한다.
# Absolute imports
import mypkg.sibling
from mypkg import sibling
from mypkg.sibling import example
# Relative imports
from . import sibling
from .sibling import example
절대 경로를 사용하여 import하는 것을 권장한다.
가독성이 증가하고, 에러 발생 시 에러 메시지의 형태가 좋아지기 때문이다.
단, 절대 경로가 복잡해지면 상대 경로를 사용하는 것이 가능하다.
보통 표준 라이브러리 코드는 복잡한 경로를 피하고 절대 경로를 사용하는 것을 따른다.
# local name clashes
from myclass import MyClass
from foo.bar.yourclass import MyClass
# class-containing module
import myclass
import foo.bar.yourclass
mc = myclass.MyClass
yr = foo.bar.yourclass.MyClass
클래스를 포함한 모듈에서 클래스를 가져올 때, from 모듈 import 클래스의 형태를 따른다.
이때 클래스명 충돌이 발생한다면, import만을 사용하여 모듈.클래스명의 형태로 명시하여 사용한다.
Wildcard imports(*)는 정확하게 무엇을 사용할지 헷갈리기 때문에, 사용하지 않아야 한다.
# ---------- Import ----------
from sys import stdin
input = stdin.readline
# ---------- Function ----------
def mulMatrix(A: list, B: list) -> list:
N = 2
result = [[0]*N for _ in range(N)]
for m in range(N):
for n in range(N):
for k in range(N):
result[m][n] += A[m][k] * B[k][n]
result[m][n] %= MOD
return result
def power(base, exponent):
if exponent == 1:
return base
tmp = power(base, exponent // 2)
if exponent % 2:
return mulMatrix(mulMatrix(tmp, tmp), base)
else:
return mulMatrix(tmp, tmp)
def fibonacci(N):
result = power([[1, 1], [1, 0]], N)
return mulMatrix(result, [[1, 0],[0, 0]])[1][0] % MOD
# ---------- Main ----------
small, big = map(int, input().split())
MOD = 1_000_000_000
big = fibonacci(big+2)
small = fibonacci(small+1)
print((big - small) % MOD)
# ---------- Comment ----------
# big = fibonacci(big+2) - 1
# small = fibonacci(small+1) - 1
# big - small = fibonacci(big+2) - 1 - (fibonacci(small+1) - 1)
# = fibonacci(big+2) - fibonacci(small+1)
# so can skip intercept