
0. Import
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings(action='ignore')
plt.rc('font', family='Malgun Gothic')시각화나 계산에 필요한 라이브러리를 호출했다.
가끔 가다가 폰트 인식 오류, 버전 관리 주의, 함수 삭제 등등의 '주의(warning)' 구문이 나온다.
jupyter notebook 환경에서 실행하였고, 이는 filterwarnings으로 주의 메시지를 무시할 수 있다.
또한 plt에서 한글 폰트를 인식하지 못하는 오류로, 직접 폰트를 지정해주었다.
해당 프로젝트에서 사용하는 한글 폰트는 '맑은 고딕'이다.
쓸모없는 꺽새나 문양 없이 깔끔한 고딕체이기에 사용했다.츄
1. Checking columns info

작성한 mariokart 데이터를 csv로 변환 후 데이터프레임의 정보를 확인했다.
컬럼들의 전체 크기(개수)가 동일한지, 의도한 대로 data type이 들어갔는지 확인하기 위함이다.
의도한 바로는 특이사항(significant) 같은 컬럼을 제외하고는 전부 int나 float여야 하는데 아니다.
또한 null 데이터, 즉 결측치 때문에 데이터 개수도 일정하지 않다.
데이터 전처리를 하면서 유심히 확인해보도록 하자.
2. Preprocessing - game_count

전처리 하기 직전의 game_count 컬럼의 데이터 분포다.
under 3와 under 4 데이터 때문에 object 타입으로 들어간 모습이다.
under N이라는 것은 결국 N등 이내로 들어와야 한다는 말과 같다.
따라서 under가 있는 경우 under를 제거하는 방향으로 전처리를 진행했다.
astype으로 형변환하는 것도 잊지 말자.
전체적으로 데이터를 살펴보면서 발견한 문제점이 있다.
데이터 불균형이 극심하다는 것이다.
대부분의 놀이터가 그러하듯... 역배가 계속해서 터지면 그건 역배라고 부르지 않는다.
이 점을 유의하면서 우선 데이터를 계속해서 전처리 해보자.
3. Preprocessing - game_goal

game_goal도 데이터 불균형이 상당히 크다.
거의 대부분의 상황에 '3판 합계 15등 이내'라는 놀이터가 열린다.
또한 마찬가지로 int를 예상했지만, object의 타입을 가진 game_goal 컬럼이다.
under와 유사하게 fix라는 데이터가 있었던 것을 까먹었다.
fix(N)의 경우 N등을 정확하게 맞추는 놀이터가 열린 경우다.
물론 방향성이 아주 조금 다른 느낌이기는 하다만...
해당 프로젝트의 목적은 '성공/실패를 판단하는 이진분류기'에 가깝다.
따라서 정확한 N등에 대한 정보는 필요 없어 drop 해주었다.
정확한 등수 예측 기능도 추가하긴 할 거다만, fix는 선택지가 3개 이상이기에 drop이 맞다고 판단했다.
해당 프로젝트에서 필요한 데이터는 성공/실패라는 2개의 선택지다.
내 예상과 다르게 흘러가는 게 상당히 마음에 들었다.
이래야 진짜 실전처럼 데이터를 전처리하고 다룰 수 있기 때문이다.
오히려 좋아.
4. Preprocessing - win_odds, lose_odds

columns info에서 win_odds와 lose_odds만 631개로 데이터가 1개? 2개? 적었던 것을 확인했다.
이를 근거로 어딘가에 결측치가 있으리라고 판단하여, isna()로 결측치 개수를 세주었다.
아니나 다를까 win_odds와 lose_odds에서 각각 1개의 결측치를 확인했다.
실제로 위의 1개의 결측치는 옥냥이가 유튜브에 올리지 않은 새벽에 달린 놀이터였다.
하지만 나는 그때 생방송을 보지 않고 있었고, 사관님께서도 방송 도중 놓쳐 생겨버린 결측치다.
배당에 의해 성공/실패 여부를 판가름하는 게 아닌,
성공/실패에 따라서 사람들의 투표가 몰려 배당이 정해진다고 생각한다.
즉 배당은 독립변수라고 판단하여, fill하지 않고, row를 제거하는 방향으로 처리했다.
X['win_odds'] = X['win_odds'].str.replace("..", "." , regex=False)win_odds에서는 EDA 할 때 발견했던 missing value가 하나 있다.
실제 csv 파일을 만들 때, 12.20이 아니라 온점(.)을 2번 눌러버려서 12..20이라는 데이터가 생겼다.
이 떄문에 float로 형변환을 하지 못 하고 계속 에러가 떴었다.
이런 실수는 환영이다. 실제 데이터 오류이지 않은가? 이 또한 연습이다.
replace를 사용하여 문자열을 대체했다.
하지만 replace의 문자열 대체는 정규표현식(RegEx)을 따라 동작한다.
정규표현식에서 온점(.)은 '어떤 문자든 상관없다'는 의미로써 사용한다.
즉 \.\.로 온점을 온점으로 사용하든지, regex=False로 정규표현식이 아님을 명시해야 한다.
X['win_odds'] = X['win_odds'].astype(float)
X['lose_odds'] = X['lose_odds'].astype(float)win_odds와 lose_odds도 info에서 object임을 확인했었다.
이에 object 자료형을 float로 변경하는 것이 필요하다.
처음에 다른 컬럼들이 전부 int이니 int로 처리했는데, 이 컬럼은 소수 데이터가 있는 float다.
사소한 점 하나하나 주의하자.
5. Preprocessing - track_K, track_E
X = X.drop(["track_K"], axis=1)track_K는 track_E가 있기에 크게 필요없는 컬럼이다.
따라서 지금 drop하든 나중에 feature_to_drop 과정에서 drop하든 상관이 없다.
사용자에 따라 처리하되, drop 해야 한다는 것만 잊지 말자.
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
encoded = label_encoder.fit_transform(X['track_E'])
X['track_E_encoded'] = encodedtrack_E 데이터는 LabelEncoder를 사용하여 전처리했다.
track_E_encoded에 인코딩한 데이터를 넣고, 나중에 track_K와 함께 drop하기로 했다.
track_E 데이터를 살려놓은 이유는 두 가지이다.
1. 어떤 문제나 변경점이 생길지 모르기에, 원본 데이터를 살려놓을 필요가 있다고 생각했다.
2. LabelEncoder로 인코딩 해버리면 숫자만이 남는데, 숫자로는 어떤 맵인지 즉각 알 수 없다.
encoder.classes_로 살펴볼 수 있지만, 데이터프레임에서 직접 눈으로 보는 게 더 와닿아 살려두었다.

track_E_encoded 컬럼에 대한 데이터 분포를 시각화했다.
다른 컬럼들에 비해서 의외로 데이터 불균형은 적어보인다는 느낌이 들었다.
동시에 뭔가 고르게 나온다..? 그래프가 계단 형태를 띄는데 계단의 폭이 어느 정도 일정하다는 느낌이 있다.
이런 데이터는 불균형이 있다고 봐야하는지 없다 봐야하는지 아직은 잘 모르겠다.
데이터 불균형보다 실은 더 문제는 따로 있다.
문자열의 경기장 데이터를 숫자로 바꾸는 순간, 숫자들 간의 상관관계가 생길 우려가 있다.
우선 진행을 해보고, 문제가 생긴다면 다른 방법으로 처리하는 것도 고려해야 한다.
track_2_num = dict()
num_2_track = dict()
for num, track in enumerate(label_encoder.classes_):
track_2_num[track] = num
num_2_track[num] = track위에서 언급한 대로 숫자만을 보고 어떤 경기장인지,
반대로 경기장 이름만을 보고 어떤 숫자인지 바로바로 나오기 어렵다.
따라서 dictionary로 찾을 수 있게끔 값을 저장해주었다.
6. Preprocessing - cc

실제로 cc는 자동차의 배기량을 뜻하는 단위이다.
마리오 카트에서도 cc로 맵의 빠르기를 구분짓고 있다.
mirror는 Nintendo Switch 플랫폼의 mario kart 8 deluxe 기준으로 150cc 고정이다.
정확하게는 실제 인게임에서 맵 대칭만 적용이고, 속도만 150cc으로 동일하다.
따라서 mirror 데이터는 전부 150으로 전처리해주었다.
이번 컬럼이 아마 데이터 불균형이 정말 큰 경우가 아닐까...하는 생각이 든다.
7. Preprocessing - odds_result

win_odds, lose_odds 전처리 할 때 찾은 4개의 NaN 데이터가 있다.

뭔지 직접 찾아보니 실제 데이터에서는 ACC, CANCEL, NOT OPEN에서 결측치가 발생했다.
그 중 ACC 데이터는 정확하게 맞추는 fix 전처리, 즉 game_coal에서 이미 걸러졌다.
따라서 본래는 9개였지만, CANCEL, NOT OPEN의 4개만 남은 상황이었다.
X = X.loc[~X['odds_result'].isna()]배당 결과가 없다는 의미는 토토가 무산되었다는 말이다.
이런 경우는 넣은 포인트를 그대로 돌려받아 회수가 가능하다.
따라서 해당 row는 drop하여 처리한다.
from sklearn.preprocessing import OneHotEncoder
X['odds_result'] = X['odds_result'].replace("straight up", "SU").replace("underdog", "UD")
encoder = OneHotEncoder(sparse=False)
encoded = encoder.fit_transform(X[['odds_result']])
df_encoded = pd.DataFrame(encoded.astype(int), columns=encoder.get_feature_names_out())
X = pd.concat([X.reset_index(), df_encoded], axis=1)
전처리 이후 정배/역배를 적은 데이터는 OneHotEncoding으로 처리한다.
정배는 straight up을 줄여서 SU로, 역배는 under the dog를 줄여서 UD로 많이 쓴다.
OneHotEncoding을 해서 컬럼명이 길어지는 것을 방지하기 위해 2글자 약어로 바꿔주었다.
SU와 UD는 단 두 가지의 데이터이기 때문에 OneHotEncoding이어도 차원이 크게 늘어나지 않는다.
따라서 숫자와 상관관계가 생길 수 있는 LabelEncoding이 아닌 OneHotEncoding으로 처리했다.

이제는 빠지면 섭한 데이터 불균형이다.
그래도 불균형이 심한 편은 아니라고 생각한다.
8. Preprocessing - significant
X = X.loc[X['significant'].isna()]significant의 특이사항들(CANCEL, MISS, NOT OPEN 등)을 제외한다.
isna()로 공백이 있는(특이사항이 없는) 데이터들만 추려낸다.
9. Preprocessing - RESULT

최종적으로 확인한 True/False 데이터 분포이다.
데이터 불균형 정도는 odds_result와 유사하다.
10. Checking corr and VIF
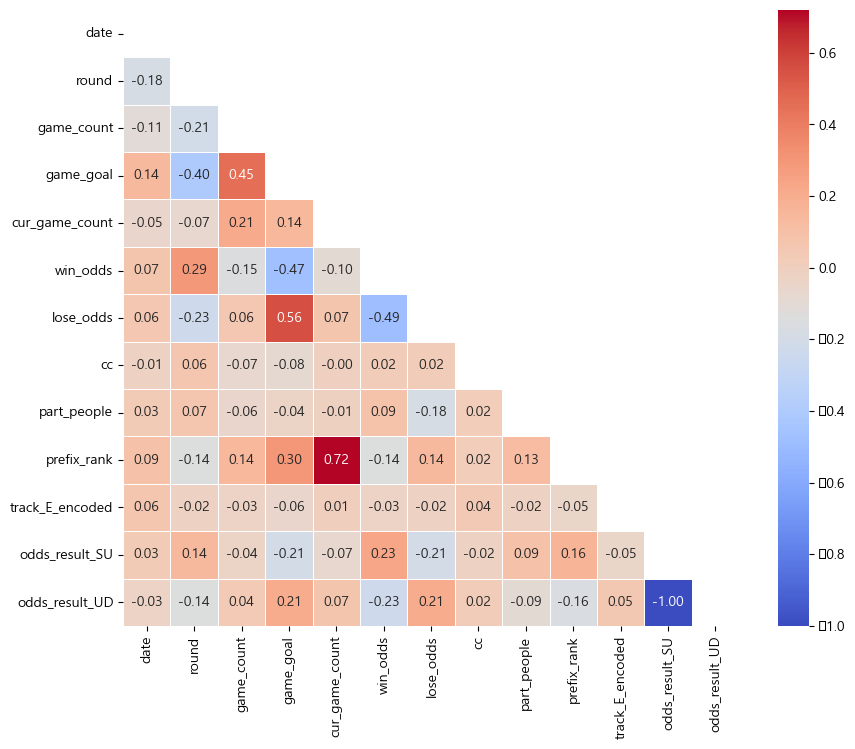
일반적인 Pearson 상관계수로 두 변수 간의 선형 관계의 강도를 측정한다.
가장 많이 사용하는 상관계수 방법이지만, 이상치에 민감하다.
그래서 데이터가 정규 분포를 따르지 않는다면 해석을 잘못할 가능성이 존재한다.

그래서 추가로 Spearman 상관계수와 Kendall 상관계수를 이용한 상관관계를 살펴보았다.
Spearman 상관 계수는, 비선형 관계를 포함해 두 변수 간의 순위 기반의 연관성을 측정한다.
이상치의 영향을 덜 받으며, 데이터가 비정규 분포일 때 유용한 상관 계수이다.
Kendall 상관 계수는, spearman 상관 계수와 유사하게 순위 기반의 상관관계를 측정한다.
데이터 셋이 작을 때나 불균형한 데이터셋에 적합하며, 이상치에 강건하다.
수집한 데이터는 비선형이면서 데이터 불균형이 높고 데이터 셋이 작아, Kendall 계수가 가장 적합하다고 생각한다.
Kendall 계수의 상관 관계 점수에 기반하여 관련 있는 컬럼들을 확인한다.
또한 Kendall 외에 나머지 두 상관 계수에서도 드러나는 높은 연관성들이 있다.
다중공선성(VIF)을 고려해서 추후 특정 컬럼은 drop하는 걸 고려해야 한다.
1. (win_odds, round)
2. (lose_odds, game_goal)
3. (prefix_rank, cur_game_count)
4. (prefix_rank, rank)
5. (odds_result_UD, RESULT)
11. Modeling - Data subset
X, y = X.drop('RESULT', axis=1), X['RESULT']개략을 알기 위해 간단한 모델링 후 결과를 살펴보려고 한다.
학습을 위한 X와 결과 예측을 위한 y로 데이터셋을 분리해주었다.
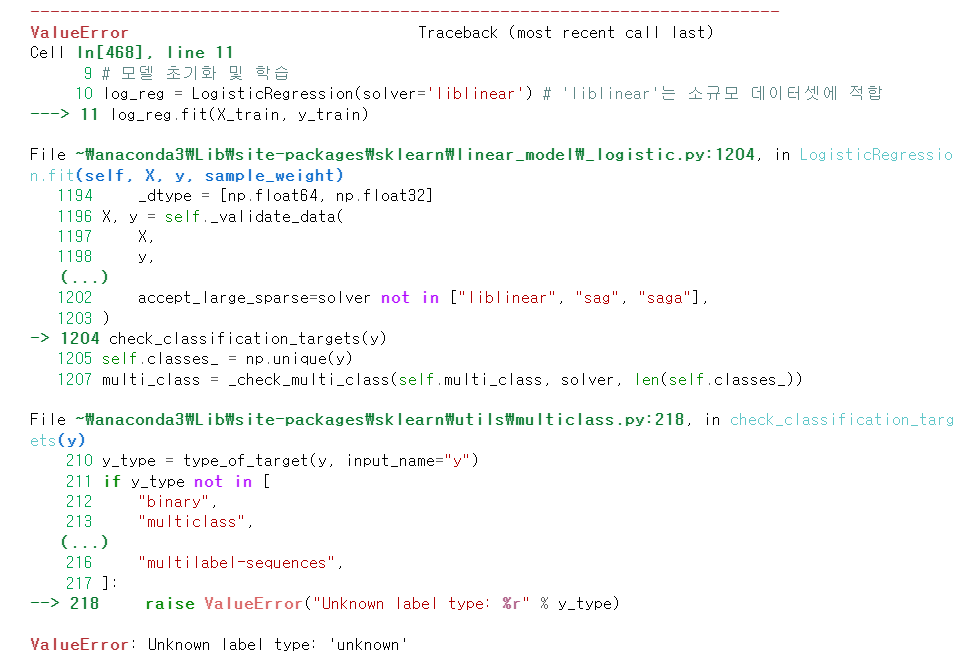
테스트 하다가 에러가 발생했다.
RESULT에 TRUE와 FALSE만 넣어주어 bool 타입이라고 생각했는데 아니었다.
"TRUE"와 "FALSE" 데이터로 들어가 object 타입이 된 것이다.
이럴 때 발생하는 에러여서 astype으로 형변환을 진행했다.

타입 해결 후 LogisticRegression으로 학습하여 테스트했다.
이때 new_data를 임의로 넣어주었는데 데이터프레임이 아니라 1차원 리스트로 넣어주었다.
이떄 차원이 맞지 않는다는 에러가 발생했다. 즉 1차원을 2차원으로 변형해야 한다.
그 후 predict_proba의 shape가 np.array(1, 2)라서 다시 1차원으로 변형했다.

차원을 변경하는 게 익숙치 않아, 관련 함수를 찾아보았다.
2차원 데이터 프레임(2차원의 np.array)을 1차원으로 바꾸는 함수는 2가지가 있다.
flatten()과 ravel()인데 이게 느낌이 약간 sorted()와 sort()의 차이 같은 느낌이다.
flatten()이 sorted()고, ravel()이 sort()에 해당한다.
둘 다 1차원으로 평탄화 해주지만, flatten()은 기존 값은 유지한 채 새로운 값을 반환한다.
ravel()은 기존 값을 바꾼다. 그렇다고 반환 값이 없는 건 아니고 id(주소)가 같은 배열을 반환한다.

그리하여 최종적으로 테스트를 해주었더니 결과가 이상하다...
(중간에 RESULT 외에 등수 예측도 필요하다고 생각하여 rank 컬럼도 따로 빼주었다.)
생각해보니 rank는 1위부터 12위까지 존재하는 회귀(regression) 문제다.
LogisticRegression은 분류(classifier) 문제라서 학습이 안 되는 문제가 발생했다.
처음 배울 때도 그랬는데 이름에 Regression이 들어가서 종종 회귀 모델로 착각하는 경우가 있다.
또한 RESULT는 중간에 변수가 꼬여서 accuracy가 0으로 뜨는 문제가 발생했다.
다시 깔끔하게 리모델링을 진행하기로 했다.
12. reModeling - Data subset
X, y_rank, y_result = X.drop(['rank', 'RESULT'], axis=1), X['rank'], X['RESULT'].astype(bool)데이터 셋을 X와 y 2개로 나누어준다.
y_rank는 등수 예측에 사용할 회귀(regression) 모델용 데이터,
y_result는 결과 예측에 사용할 분류(classifier) 모델용 데이터로 넣는다.
y_result에는 결괏값 자료형 때문에 오류가 발생하지 않도록 astype을 한다.
13. reModeling - rank column

특별한 파이프라인 설정 없이 LinearRegression으로 진행했다.
LogisticRegression이 아니다. 헷갈리지 말자.
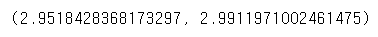
학습 후 train 데이터셋과 test 데이터셋에 대한 RMSE 점수 측정했다.
회귀(regression) 모델에서 손실 함수로 MSE를, 평가 함수로 MAE를 보통 사용한다.
그래서 MAE를 하려고 했지만, 손실 함수를 평가 함수로써 사용하면 어떻게 될까?라는 생각에 MSE로 진행했다.
이때 MSE는 점수가 너무 커져서 RMSE로 진행했다.
R2, MAE, MSE, RMSE에 대한 비교와 특징 설명은 링크를 참고하면 좋다.
14. reModeling - rank prediction

예측한 결과 예시 사진이다.
'1판 이내 12등 이내'라는 토토가 열렸고, 150cc 71번 맵에 12명이 참가했다.
이 경우에 옥냥이는 6등을 할 거라는 결괏값이다.
15. reModeling - RESULT column

특별한 파이프라인 설정 없이 LogisticRegression으로 진행했다.
소규모 데이터셋에 적합한 매개변수로 solver에 liblinear를 설정했다.

학습 후 train 데이터셋과 test 데이터셋에 대한 accuracy_score 점수 측정
여기서는 간단하게 어떤 느낌으로 나오는지 확인하기 위해 acc 점수만 확인했다.
마치 신뢰 수준을 95%로 설정한 것처럼, 다른 prediction, recall 등의 점수는 우선 보류한다.
16. reModeling - RESULT prediction

위에서와 마찬가지로 '1판 이내 12등 이내'라는 토토가 열렸고, 150cc 71번 맵에 12명이 참가했다고 가정한다.
문제점이 발생했다. 마리오 카트에서는 12등이 꼴지다.
즉 1판 이내 12등 이내는 무조건 성공인데, True 확률이 57%밖에 안 된다.

이상함을 느껴 model의 coef(feature importances)를 확인해봤는데 너무 치우쳐져있다.
이 부분은 모델링을 할 때 주의깊게 살펴보고 고쳐야 할 듯하다.
17. 추후 방향
- track_E 숫자, 정도의 차이를 학습하지 않는 방법 모색
- 첫 판은 rank 데이터 정보가 없지만, 두 번째 판부터는 rank 데이터가 있다.
- 따라서 같은 가중치(weight)를 기반으로 2가지 모델을 만든다?
- 그래서 다른 모델로, 결과를 따로 구하는 방법으로 가야 할 듯
- 회귀와 분류의 2가지 방안에서 고려해야 함
- 데이터셋이 적기 때문에, 이에 특화된 모델을 골라서 학습해야 할 듯하다
- 회귀 측면) LinearRegression, Ridge & Lasso Regression, ElasticNet, SVR
- 분류 측면) LogisticRegression, DecisionTree, SVM
- 문제점) 데이터 불균형이 꽤 높다.
- catboost를 사용해야 할지도?
- 우선 가중치나 micro tunning 없이, 가장 단순한 형태로 전처리를 진행
- 그 후 각 모델에 대해서 학습하여 cross validation 진행
- cross validation으로 가장 높은 모델 평가 후 선정
- pyinstaller로 exe 파일을 만들어야 하기 때문에, 이 기간도 고려해서 프로젝트 진행
- 프로그램 img 파일도 생각하기
- modlunky를 참고해서 OOP로 코드 작성하기
'사이드 프로젝트 > 옥냥이 마리오카트 토토 예측' 카테고리의 다른 글
| 옥냥이 불안전한 놀이터, AI 모델 재선정하기 (0) | 2024.03.29 |
|---|---|
| 옥냥이 불안전한 놀이터, AI 모델 선정하기 (0) | 2024.03.20 |
| 옥냥이 불안전한 놀이터, EDA 해보기 (1) | 2024.03.07 |
| 데이터 추가 수집하기, csv 파일 데이터 추가하기 (0) | 2024.03.05 |
| csv 파일 만들기 (0) | 2024.03.02 |