# ---------- Import ----------
import sys
input = sys.stdin.readline
# ---------- Function ----------
def bit_check(num):
bit = []
while num & -num:
bit.append(num & -num)
num &= (num-1)
return bit
# ---------- Main ----------
N = int(input())
mp, mf, ms, mv = map(int, input().split())
foods = {2 ** i : tuple(map(int, input().split())) for i in range(N)}
possible_list = list()
for i in range(1, 2 ** N):
p, f, s, v = 0, 0, 0, 0
price = 0
is_possible = bit_check(i)
for bit in is_possible:
food_p, food_f, food_s, food_v, food_price = foods[bit]
p += food_p
f += food_f
s += food_s
v += food_v
price += food_price
if mp <= p and mf <= f and ms <= s and mv <= v:
possible_list.append((is_possible, price))
if not possible_list:
print(-1)
else:
possible_list.sort(key = lambda x: (x[1], x))
print(possible_list[0][1])
print(*list(map(lambda x: len(bin(x))-2, possible_list[0][0])))
from itertools import permutations
import re
def regex_pattern(input_string):
return re.compile(input_string.replace("*", ".{1}"))
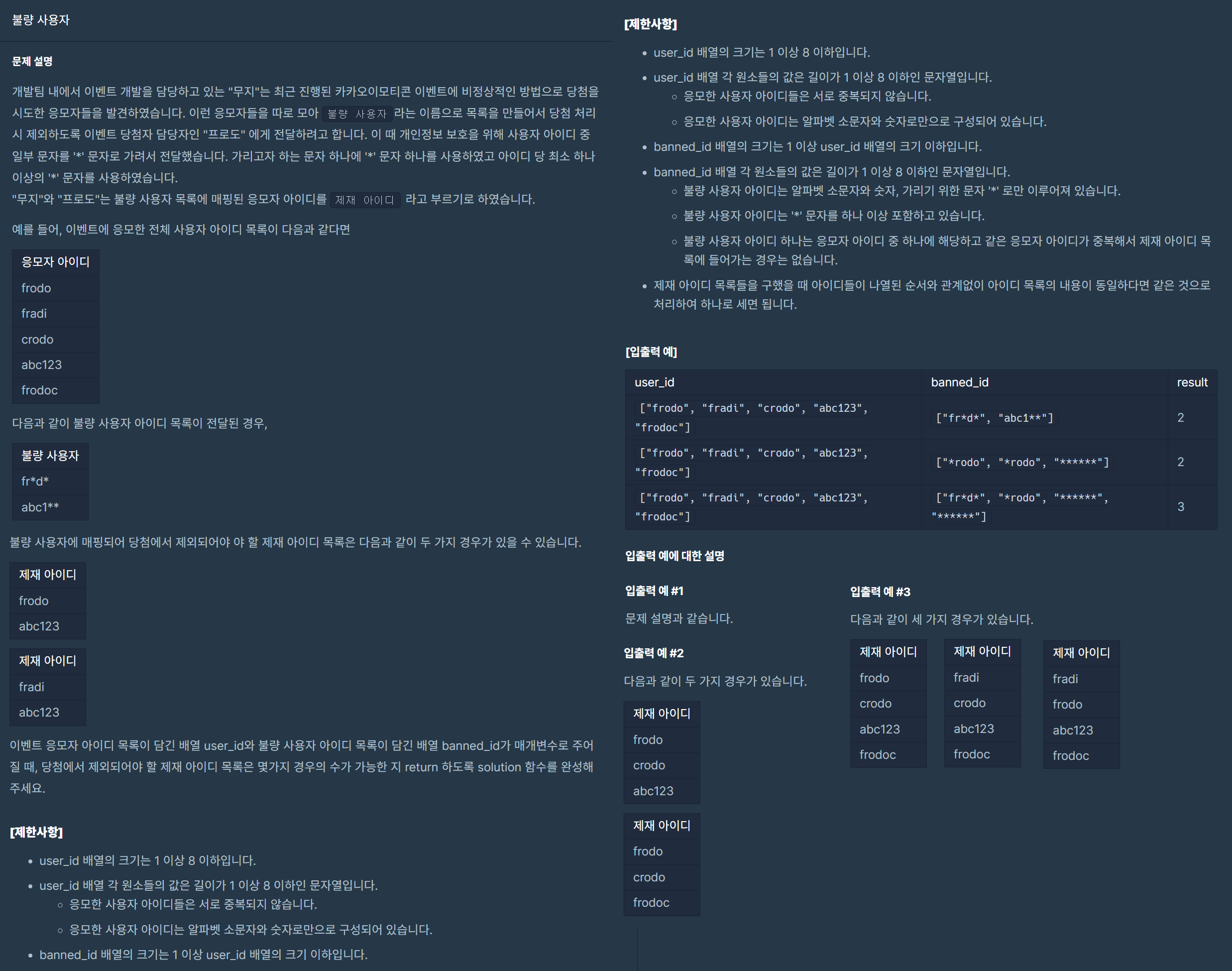
def solution(user_id, banned_id):
answer = []
count = 0
banned_id = list(map(regex_pattern, banned_id))
for case in permutations(user_id, len(banned_id)):
for c, b in zip(case, banned_id):
if not b.fullmatch(c):
break
else:
answer.append(tuple(sorted(case)))
return len(set(answer))
이때 user_id가 [frodo, crodo]이고, banned_id가 [*rodo, *rodo]라고 해보자.
*rodo는 각각 frodo, crodo가 될 수 있는 경우 2개가 있다. 그럼 2 * 2 = 4일까?
아니다. 이 점을 주의해야 한다. 중복하는 경우는 전부 하나로 취급한다.
import re
def regex_pattern(input_string):
return re.compile(input_string.replace("*", ".{1}"))
우선 '정규 표현식(Regular Expression)'을 활용하기로 했다.
*이 하나의 문자에만 대응하니 .{1}로 바꿔서 re.compile하여 사용하는 함수를 작성했다.
banned_id = list(map(regex_pattern, banned_id))
내장 함수 map을 활용하여 banned_id로 입력받은 모든 아이디를 컴파일해준다.
map 객체는 len() 같은 다른 built-in function을 사용하는 것이 불가능하기 때문에 list()로 변환한다.
번거롭게 반복문을 사용하지 않고, map() 함수와 함수를 변수처럼 사용하는 기능을 이용하였다.
from itertools import permutations
[ 제한사항 ]
ㆍ user_id 배열의 크기는 1 이상 8 이하입니다.
ㆍ banned_id 배열의 크기는 1 이상 user_id 배열의 크기 이하입니다.
문제에 위와 같은 제한 사항이 존재했다.
어라? 생각보다 제한사항이 크지가 않았다.
그럼 banned_id에 대응하는 문자열을 찾아낸 다음에 경우의 수를 조합하는 방식이 아니라,
banned_id의 길이만큼 user_id를 조합하여 모든 경우의 수를 찾으면 되는 거 아닐까?
최악의 경우를 생각해보자.
user_id가 8이면서 banned_id도 8인 경우다. 8P8로 8!에 해당하는 숫자다.
8! = 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1 = 40320개뿐이다.
따라서 브루트 포스로 모든 경우의 수를 확인해도 충분하다고 판단했다.
for case in permutations(user_id, len(banned_id)):
for c, b in zip(case, banned_id):
if not b.fullmatch(c):
break
else:
answer.append(tuple(sorted(case)))
위에서 생각한 것처럼 user_id를 banned_id의 길이만큼 경우의 수를 만든다.
이떄 combinations이 아니라 permutation을 활용한 것은 순서가 필요하기 때문이다.
정답에서 [frodo, crodo]와 [crodo, frodo]는 같은 것으로 취급하는데 모순처럼 보인다.
하지만 user_id가 [frodo, abc123]이라고 가정해보자.
그리고 banned_id가 [abc***, *rodo]라고 가정해보자.
user_id를 combinations을 해버리면 입력받은 순서를 유지한 채로 [frodo, abc123]만 존재한다.
하지만 분명하게 user_id와 banned_id는 하나하나 대응할 수 있는 상태다.
즉 이런 상황을 방지하기 위해서, 중복이 존재하더라도 우선은 permutation으로 확인해주었다.
어차피 중복은 나중에 제거하면 된다.
zip을 사용하여 permutations으로 나온 각각의 경우(case)를 묶어서 비교한다.
re.compile로 나온 b와 전부 일치하는지(fullmatch) 확인한다.
하나라도 일치하지 않는 경우가 있다면 해당 case는 무시해야 하는 경우다.
따라서 break로 빠져나온다.
만약 모든 경우에 대해서 break로 빠져나오지 않았다면, for - else 구문에서 else로 넘어간다.
나중에 중복을 제거해줘야 하기 때문에 정렬한 상태로 answer에 추가한다.
이때 주의해야 할 점은 저장한 후 자료 구조를 그대로 두면 안 된다는 것이다.
파이썬은 sort() 혹은 sorted() 내장 함수를 사용하면 list로 반환한다.
하지만 set 자료 구조를 사용할 때는 list는 사용할 수 없다. ( TypeError: unhashable type: 'list' )
set 또한 dict처럼 해시를 이용하기 때문에 키 값이 바뀌어서는 안 된다.
즉 키로 사용하는 값이 immutable 해야 한다는 뜻이다.
따라서 mutable한 list가 아닌 immutable한 tuple로 바꿔준 다음 추가한다.
return len(set(answer))
위에서 언급한 중복을 없애야 한다.
set() 자료 구조를 이용하여 간단하게 중복을 제거할 수 있다.
정렬한 상태로 answer에 담아주었기 때문에, 모든 경우의 수를 빠짐없이 중복을 제거할 수 있다.
from itertools import combinations
from collections import Counter
def solution(orders, course):
answer = []
for c in course:
temp = []
for order in orders:
combi = combinations(sorted(order), c)
temp += combi
counter = Counter(temp)
if len(counter) == 0 or max(counter.values()) == 1:
continue
MAX = max(counter.values())
answer += [''.join(c) for c, t in counter.items() if t == MAX]
return sorted(answer)
"코스요리 메뉴는 최소 2가지 이상의 단품메뉴로 구성하려고 합니다. 또한, 최소 2명 이상의 손님으로부터 주문된 단품메뉴 조합에 대해서만 코스요리 메뉴 후보에 포함하기로 했습니다."...? 라고 하는 게 이해가 안 됐다.
아니 정확하게는 '코스 요리는 2글자 이상이어야 한다'는 알겠다.
하지만 여러 개의 코스 요리가 나오는데, 어떤 기준으로 메뉴를 선택하는 거지?
코딩테스트 문제에서 풀이 과정을 얻을 수 있지만, 예제에서 얻는 문제도 있다고 한다.
하지만 아무리 그래도... 문제를 보고 풀 수 있어야 문제가 아닌가 싶기는 하다.
그래도 우선 해봐야 무엇이 틀렸는지, 확인할 수 있으니 풀어보기로 했다.
가장 좋은 확인 방법은 예제 풀이를 해 준 경우를 내가 따라가는 것이다.
우선 6명의 손님이 주문한 모든 메뉴의 개수를 세어서 오른쪽의 표를 만들어봤다.
가장 먼저 든 생각은 '모든 메뉴가 2번 이상 시켰다면 세트로 만들라는 소리인가?'였다.
예를 들자면, 2번 손님은 A와 C를 주문했다.
이때 오른쪽 표를 보면 A와 C는 모두 2번 이상 주문한 메뉴이다.
그럼 AC를 세트 메뉴로 만들어야 하는 것인가?라는 뜻이다.
def count_alphabet(count_dict, word):
for w in word:
count_dict[w] = count_dict.get(w, 0) + 1
return count_dict
그래서 알파벳의 개수를 세는 함수를 만들어 따로 세기로 했다.
간단하게 count_dict에서 get을 이용해서 개수를 세는 함수다.
def solution(orders, course):
answer = []
dict_ = {}
for order in orders:
dict_ = count_alphabet(dict_, order)
for order in orders:
for o in order:
if dict_[o] < 2:
break
else:
answer.append(order)
return sorted(answer)
첫 번쨰 반복문에서 모든 알파벳 개수를 센다.
두 번째 반복문에서 각 order의 한 글자 한 글자를 돌면서 2개를 넘었나 확인한다.
넘었다면 answer에 세트 메뉴를 추가한다.
음 역시나 아니다.
잘 살펴보니까 1번 예제에서는 H만이 2번 이상 주문한 메뉴가 아니다.
즉 ABCFG도 위의 코드에 의하면 answer에 포함되는 메뉴라는 것이다.
하지만 아니다. 조금 더 깊게 생각할 필요가 있다.
거꾸로 생각을 해보자. 요리 2개 코스, 3개 코스, 4개 코스는 여러 개 있는데 왜 하필 쟤네만 해당할까?
2개부터 생각해보자. AB부터 EH까지 다양하게 된다.
GH가 아닌 이유는, 어떤 손님에도 G와 H를 동시에 주문한 손님은 없기 때문이다.
전제 조건은 손님이 주문한 메뉴에서 조합해야 한다는 것이다.
1번 손님, AB, AC, AF, AG, BC, BF, .... 아 혹시?
혹시 말그대로 조합(combinations)을 물어보는 문제는 아닐까?
각 손님들이 가능한 모든 조합을 세서, 길이마다 가장 많은 주문을 세트 메뉴로 만드는 건 아닐까?
이게 시간이 되려나? 시간복잡도를 초과하지는 않을까?
최악의 크기를 생각해보자. 그것이 Big-O 표기법이니까.
orders의 배열의 크기는 20, 즉 최대 주문은 20개가 들어온다.
각 order는 최대 10개의 문자열로 이루어져있다.
10개의 문자에서 2개까지 세트 메뉴, 3개까지 세트 메뉴, ..., 10개짜리 세트 메뉴가 나올 수 있다.
10개에서 N개를 뽑아 조합하는 경우의 수는 파스칼의 삼각형을 이용하면 쉽게 구할 수 있다.
10C2, 10C3, 10C4, ..., 10C9, 10C10으로 파스칼의 삼각형 11번째 줄에 해당한다.
외부 라이브러리를 사용하지 않는 선에서, 적재적소에 라이브러리 사용은 약(藥)이라는 생각을 했다.
실제로 빠른 입력을 위해 sys도 사용하고, BFS를 위해 deque도 사용한다.
당장 이 문제에서만 해도 조합을 위해 itertools의 combinations을 사용하고 있다.
따라서 collections의 Counter 라이브러리를 사용하기로 했다.
from itertools import combinations
from collections import Counter
이 문제에서 사용할 라이브러리를 크게 2가지다. combinations과 Counter.
combinations은 iterable 객체와 int를 매개변수로 갖는다.
iterable 객체에 대해서 int 개수만큼 가능한 모든 조합의 경우의 수를 반환한다.
Counter는 iterable 객체 하나를 매개변수로 갖는다.
iterable 객체에 대해서 element를 key로 개수를 value로 취급해 dictionary 형태로 반환한다.
def solution(orders, course):
answer = []
for c in course:
temp = []
for order in orders:
combi = combinations(sorted(order), c)
temp += combi
course의 세트 메뉴 길이(c)에 대해서 하나씩 돌아준다.
그리고 각 길이에 대해서 모든 손님의 주문(order)에 대해 조합(combinations)을 실행한다.
그리고 temp에 더해준다.
그럼 모든 손님에게 발생하는, 각 조합의 경우의 수가 temp에 들어간다.
course에 2, 3, 4가 들어있다면, 첫 번째 반복문에서는 2가지 를 묶은 세트 메뉴, 다음에는 3가지를 묶은 세트가 들어간다.
counter = Counter(temp)
if len(counter) == 0 or max(counter.values()) == 1:
continue
MAX = max(counter.values())
answer += [''.join(c) for c, t in counter.items() if t == MAX]
return sorted(answer)
Counter를 사용해 temp를 Counter 객체로 만들어 counter에 담는다.
만약 counter에 세트 메뉴가 하나도 없거나, 최대로 주문한 횟수가 1이라면, 다음 세트 메뉴를 확인하러 간다.
예를 들어 counter = {"AB" : 1, "BC" : 1, "AG" : 1}이라면, 2가지를 묶은 세트 메뉴는 만들지 않는다.
그러니 3가지를 묶은 세트 메뉴를 확인하러 간다.
그게 아니라면 values 중에서 가장 큰 값(주문이 많은 메뉴=MAX)를 확인한다.
counter의 모든 요소를 돌면서 주문이 MAX라면, answer에 추가해준다.
그리고 마지막으로 모든 answer를 한 번 더 정렬해준다.
문제 조건에서 각 세트 메뉴도 오름차순 정렬이지만, 전체 메뉴도 오름차순 정렬이라고 한다.
그랬더니 꽤나 안정적으로 AC를 받을 수 있었다.
어째 문제를 풀수록 내가 컴퓨터 공학과가 아니고, 국문과나 영문과나 수학과는 아닐까?라는 생각이 든다.
# ---------- Function ----------
def distance(A: str, B: str) -> int:
cnt = 0
for v1, v2 in zip(A, B):
if v1 != v2: cnt += 1
return cnt
우선 거리를 재는 distance() 함수부터 작성했다.
A와 B를 받아 zip으로 묶어준다. 예를 들어서 TEST와 TEXT를 각각 넣어주었다고 해보자.
zip 객체를 list로 바꾼다면, [('T', 'T'), ('E', 'E'), ('S', 'X'), ('T', 'T)]의 형태로 반환한다.
v1, v2로 unpacking하여 다른지 비교하여 cnt에 값을 더해준다.
# ---------- Import ----------
import sys
input = sys.stdin.readline
# ---------- Main ----------
caseT = int(input())
for _ in range(caseT):
people = int(input())
MBTI = {}
# dictionary: key(MBTI)-value(count)
for v in list(input().rstrip().split()):
MBTI[v] = MBTI.get(v, 0) + 1
입력이 들어왔을 때, 심리적 거리가 최소인 경우(0)는? 똑같은 게 3개 있을 때이다.
어떻게 표현할까 하다가, 다른 MBTI 입력 개수도 같이 세줄 겸 dict으로 구현했다.
이때 for문에서 입력을 직접 받아, key(MBTI) - value(개수)로 만들어주었다.
# ---------- Main ----------
# Checking max pigeonhole
MAX = max(MBTI.values())
# Is 0 difference
if MAX >= 3:
print(0)
MAX 변수에 MBTI의 value들 중 가장 큰 값을 저장한다.
3 이상이라면 심리적인 거리는 0이니, 0을 출력하고 끝마친다.
# ---------- Import ----------
from itertools import combinations
# ---------- Main ----------
# Same things is exist
elif MAX == 2:
gap = []
for v1, v2 in combinations(MBTI.keys(), 2):
gap.append(distance(v1, v2))
print(min(gap) * 2)
만약 MAX가 2라면 ENFJ ENFJ ISTJ 이런 형태로 입력이 들어온 것이다.
그렇다면 ENFJ의 거리는 잴 필요가 없다. ENFJ와 ISTJ의 거리만 재면 되는 것이다.
입력받은 keys()들을 2개씩 combination하여 gap에 추가한다.
그 뒤 가장 작은 값에 2를 곱하면 된다.
2를 곱하는 이유는 두 명의 ENFJ와 한 명의 ISTJ이기 때문이다.
# ---------- Main ----------
# No duplicate
else:
gap = []
for v1, v2 in combinations(MBTI.keys(), 2):
gap.append(distance(v1, v2))
print(sum(sorted(gap)[:3]))
나머지 경우(else)는 중복하는 입력이 하나도 없는 경우이다.
MAX == 2인 경우와 코드가 거의 유사하다.
마찬가지로 keys()에서 2개씩 combination하여 차이를 조사한다.
그리고 gap을 정렬하여 가장 작은 3개의 값을 더하면 최솟값이 되리라 생각했다.
이렇게 코드를 작성하고 예제 입력을 테스트 해보았지만 틀렸다.
MAX >= 3인 부분에서는 틀릴 이유가 없으니 나머지 부분에서 틀렸으리라 생각했다.
실제로 계속해서 elif(MAX == 2)에서 오류가 나서 생각해보았다.
생각해보니 elif에서 치명적인 문제가 있었다.
중복하는 입력이 있다고 하더라도 그것의 심리적인 거리가 최소라는 보장은 없었다.
예를 들어서 ENFJ ENFJ ISTP ISTJ INTJ의 입력을 받았다고 해보자.
그럼 MBTI dictionary는 {'ENFJ': 2, 'ISTP': 1, 'ISTJ': 1, 'INTJ': 1}로 이루어질 것이다.
ENFJ-ISTP, ENFJ-ISTJ, ENFJ-INTJ, ISTP-ISTJ, ISTP-INTJ, ISTJ-INTJ 경우 중 가장 작은 차이를 고를 것이다.
└ Combinations를 하면 생기는 6가지의 경우의 수이다.
즉 이말은 ENFJ와의 거리가 가장 작은 것을 고른다는 보장이 없다는 말이다.
문제는 더 있었다. 만약 위에서 ENFJ와의 거리가 가장 작은 걸 골랐다고 가정해보자.
그래도 과연 이게 최소 심리 거리를 보장받을 수 있을까? 아니다.
ISTP, ISTJ, INTJ 어느 것과도 ENFJ는 심리 거리가 3 이상이다. 그럼 최종 심리 거리는 6 이상이다.
하지만 ISTP, ISTJ, INTJ 셋 사이의 심리 거리는 1 + 1 + 2로 4에 불과하다.
MAX값이 2인 key가 최적의 해를 반환한다는 보장이 없다.
# ---------- Main ----------
# Is 0 difference
if MAX >= 3:
print(0)
# Combinations all element, and sum min 3 side
else:
gap = []
for v1, v2 in combinations(MBTI.keys(), 2):
gap.append(distance(v1, v2))
print(sum(sorted(gap)[:3]))
결국 하나하나 비교하는 방법밖에 없었기에 elif 조건문은 지워버렸다.
elif일 때나 else일 때나 코드도 기본적으로 유사했기 때문에 상관이 없었다.
더 빠른 연산을 위해 MAX 값이 2일 때의 예외 처리를 해줬을 뿐이다.
그래도 여전히 틀렸습니다가 나온다. 결국 또 else 부분이 문제라는 거다.
곰곰이 생각해보니 저 코드도 말이 안 되는 코드였다.
최솟값에만 집중하다보니 세 MBTI와의 상관 관계를 무시해버렸다.
입력이 예를 들어서 ISFJ INFJ ESTP ESFP ENFJ ENTJ가 들어왔다고 가정해보자.
그럼 다양한 경우의 수들을 조합해서 그 차이를 계산할 것이다.
오름차순으로 정렬하면 ISFJ INFJ의 1, ESTP ESFP의 1, ENFJ ENTJ의 1이 가장 앞의 3개이다.
최솟값은 맞으나 세 명의 상관 관계가 전혀 아니다.
애초에 Combination을 할 때, 2가 아니라 3으로 진행했어야 한다.
# ---------- Main ----------
people = int(input())
MBTI = list(input().rstrip().split())
# Pigeonhole principle
if people > 32: print(0)
# Combinations all element, and sum min 3 side
else:
gap = []
for v1, v2, v3 in combinations(MBTI, 3):
g1 = distance(v1, v2)
g2 = distance(v1, v3)
g3 = distance(v2, v3)
gap.append(g1 + g2 + g3)
print(min(gap))
코드에 크게 2가지 변화를 주었다.
하나는 요소들을 조합(Combination)하는 방법, 다른 하나는 비둘기 집 원리의 조건문이다.
우선 Combination부터 살펴보면, 위와 다르게 이제는 dict으로 저장할 필요가 없어졌다.
따라서 문자열을 list로 입력받고 3개씩 조합해주었다.
└ 다른 언어에서는 3중 for문을 사용하면 된다. Python3에서는 3중 for문보다 combinations을 활용하면 더욱 빠르다.
v1, v2, v3로 unpacking해서 각각의 요소들의 거리를 측정해준다.
그리고 gap에 이 값들을 추가해주고, 최종적으로 가장 작은 값을 출력하면 된다.
지금 글을 쓰면서 생각난 건데, gap을 굳이 list로 받지 않았어도 됐겠다 싶다.
gap을 int로 선언하고, 들어올 때마다 더 작은 값을 gap에 넣어주면 메모리를 더 아낄 수 있었다.
비둘기 집 원리는 dict에서 list로 MBTI를 받음에 따라 조건에 변화를 줄 필요가 있었다.
문제를 해결할 때 언제나 최악의 경우를 생각해야 한다.
입력이 가장 중복하지 않게끔 들어온다면 몇 개가 와야 0을 출력할 수 있을까?
최악의 경우 32개(16개의 MBTI가 중복하지 않고 들어온다)가 들어오고 난 뒤이다.
그러고 나면 어떤 MBTI가 들어오든 무조건 3개가 중복되는 MBTI가 생기게 된다.
└ 이래서 비둘기 집 원리가 알고리즘 분류에 있었구나 싶었다.
단순하게 개수 입력이 32개를 초과하면 0을 출력하면 되는 문제였다.
그렇게 정답을 맞췄다.
비둘기 집 원리에 따르면 32개가 최악의 경우라는 이야기이다.
그럼 최악에 32 * 32 * 32의 경우의 수인데, 이는 32,768개로 브루트포스가 4만 개도 돌지 않는다.
# ---------- Import ----------
import sys
input = sys.stdin.readline
# ---------- Function ----------
def doMakeTetromino(visited: list, x: int, y: int, blockCnt: int, totalValue: int) -> int:
global result
# End condition 1) sum of all elements(for MAX) is smaller than result
if result >= totalValue + MAX * (4-blockCnt):
return
# End condition 2) success tetromino
if blockCnt == 4:
result = max(result, totalValue)
return
# Checking 4 directions by backtracking
for i in range(4):
nx = dx[i] + x
ny = dy[i] + y
# Whether include, and not visited
if 0<=nx<row and 0<=ny<col and visited[nx][ny]==0:
# Shape ㅗ, ㅜ, ㅓ, ㅏ
if blockCnt == 2:
visited[nx][ny] = 1
doMakeTetromino(visited,x, y, blockCnt+1, totalValue+INPUT[nx][ny])
visited[nx][ny] = 0
# Other shapes
visited[nx][ny] = 1
doMakeTetromino(visited, nx, ny, blockCnt+1, totalValue+INPUT[nx][ny])
visited[nx][ny] = 0
# ---------- Main ----------
row, col = map(int, input().split())
INPUT = [list(map(int, input().split())) for _ in range(row)]
# UP, DN, LFT, RGT
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
visited = [[0 for _ in range(col)] for _ in range(row)]
result = 0
MAX = max(map(max, INPUT))
for r in range(row):
for c in range(col):
visited[r][c] = 1
doMakeTetromino(visited, r, c, 1, INPUT[r][c])
visited[r][c] = 0
print(result)
그냥 종이 위에 블럭 하나를 두고, 어떤 값이 최댓값이게?하고 묻는 문제라 나름 쉽다고 생각했다.
그러기 위해서는 먼저 블럭들의 종류를 파악해야 한다.
가능한 모든 테트로미노들을 나열해보았다. 회전과 대칭이 모두 가능한 것을 유념하자.
그럼 총 19가지의 경우의 수가 나온다. 음... 하드코딩하기에는 너무 많은 종류다.
Tetrominos라는 배열을 만들고, 그 안에 2차원 배열로 각 블럭에 해당하는 값을 bool로 선언할 수 있다.
하지만 파이썬에서나 간단하지 C++나 자바를 생각했을 때 고려해야 할 상황이 많아진다.
문제를 풀 때 어느 언어에서나 가능한 '알고리즘'이 필요한 것이다.
그래서 다양한 경우의 수들을 생각해보았다.
1, 2, 3번의 수행 결과 전부 시간 초과가 발생했다.
1. (3 * 2)의 배열을 만들어서 확인한다.
예외 처리를 해줘야 하는 블럭이 2개 존재한다. 1자 블럭 2개의 버전이다.
위 2개 블럭을 제외하면 (3 * 2) 배열에서 2칸씩 빠진 부분이었다.
가운데 행 2칸이 빠지거나, 대각선으로 2칸이 빠져 1칸을 고립시키는 경우를 제외하고 나머지 경우의 수0들이다.
하지만 1자 블럭을 한 번에 포함할 수 없고, 블럭 모양에 따라 (3 *2)인지 (2 * 3)인지가 또 나뉜다.
예외 처리가 조금 필요한 아이디어라서 우선 보류해두었다.
2. 경향성을 파악한다.
우리에게 필요한 것은 최댓값이다. 그럼 입력받은 2차원 배열에서 평균보다 높은 곳을 살피면 되지 않을까?
평균을 계산하고 각 숫자들이 평균 초과인지 미만인지 검사를 해 bool 형태로 나타낸다.
이렇게 bool이 True인 요소에서만 위의 19개의 블럭 형태를 검사해주면 될 것이라 생각했다.
이때 딱 평균인 경우에는 True와 False 중 어느쪽으로 처리를 해줘야 하나 고민했는데 True로 해줘야 한다.
예를 들어 모든 2차원 입력이 1이라고 한다면 평균도 1이 된다.
False로 처리한다면 모든 부분에서 검사를 하지 않을 테고, 결국 최댓값은 4가 아니라 0이 된다.
하지만 이 방법에는 2가지 문제점이 있었다.
첫 번째는 평균보다 살짝 못 미치는 4개 숫자가 있다고 했을 때, 이게 최댓값이 될 수도 있다는 것이다.
예를 들어 평균이 6인데 5가 4개 묶여있는 곳이 있을 수 있다.
이게 최댓값이면서 검사하지 않을 수도 있지 않은가? 아니라고 확실하게 할 수 있는 수학적 근거가 없었다.
두 번째는 어찌됐든 19개의 블럭을 전부 검사해야 한다는 것이다.
물론 전체의 2차원 배열을 전부 검사하는 것보다는 시간이 짧겠지만, 언제나 Worst Case도 생각해야 한다.
모든 입력이 같다면? 결국 모든 입력을 조사해야 한다. 따라서 이 아이디어는 기각했다.
3. 블럭을 2개씩 끊어서 생성한다.
테트로미노라는 가정이 애초에 조각이 4개로만 이루어진 블럭이라는 것이다.
그럼 2개 2개로 끊어서 생성할 수 있다면 조금 간편한 브루트포스가 되지 않을까? 생각했다.
(2 * 1)의 블럭 주변으로 또 다른 (2 * 1) 블럭을 한 칸씩 맞닿게 움직이면서 블럭을 만든다.
물론 1번의 방법처럼 90° 회전해야 한다는 문제가 있기는 했지만 느낌은 좋았다.
하지만 (2 * 1)의 블럭 2개가 꼭짓점으로 맞닿는다면 이건 또 문제에서 원하는 형태의 블럭이 아니다.
게다가 ㅗ, ㅜ, ㅓ, ㅏ 네 가지 문양이 문제였다. 이 친구들을 하기 위해서는 따로 처리를 해줘야 한다.
위에서 작성한 것외에도 많은 생각들을 더 했지만, 4개의 저 블럭들이 자꾸 예외를 만든다.
직접 하드코딩으로 빼주거나 예외적으로 다른 처리를 무언가 해줘야 함이 자꾸 눈에 밟혔다.
이 방법은 네 가지 블럭 모양과, 꼭짓점의 예외 처리가 더 발생하기에 기각했다.
4. 백트래킹을 활용한다.
위에 언급한 경우의 수들은 어떻게 보면 전부 하드코딩에 가까운 방법들이다.
자신 없어서 유난히 다른 방법들을 모색해봤는데, 결국 백트래킹만이 정답일 것 같은 느낌이 든다.
한 부분을 기점으로 길이가 4가 될 때까지 DFS 탐색을 하다가, 4가 되면 백트래킹.
그렇게 2중 반복문으로 모든 원소를 돌면서 진행을 해주는 브루트포스 알고리즘.
느낌적인 느낌으로 아 이건 정답 코드다...!라는 게 왔다.
부족한 게 있으면 채워야 하는 법. 백트래킹의 방법으로 진행한다.
# ---------- Import ----------
import sys
input = sys.stdin.readline
# ---------- Function ----------
def doMakeTetromino():
return
# ---------- Main ----------
row, col = map(int, input().split())
INPUT = [list(map(int, input().split())) for _ in range(row)]
result = doMakeTetromino()
print(result)
가장 기본이 되는 코드를 짜주었다.
브루트포스이니 빠른 입출력을 위한 코드, 테트로미노를 만들 doMakeTetromino 함수, 그리고 Main 부분이다.
# ---------- Function ----------
def doMakeTetromino(visited: list, x: int, y: int, blockCnt: int, totalValue: int) -> int:
return
# ---------- Main ----------
visited = [[0 for _ in range(col)] for _ in range(row)]
result = 0
백트래킹용으로 visited 2차원 배열을 선언해주었다.
결과를 저장하는 result 변수를 생성하고 0으로 초기화해준다.
doMakeTetromino의 매개변수를 바꿔준다.
visited 배열, 조사할 2차원 배열의 x, y 좌표, 몇 조각인지 확인할 blockCnt, 숫자의 합을 확인할 totalValue이다.
# ---------- Main ----------
# UP, DN, LFT, RGT
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
visited = [[0 for _ in range(col)] for _ in range(row)]
result = 0
for r in range(row):
for c in range(col):
visited[r][c] = 1
doMakeTetromino(visited, r, c, 1, INPUT[r][c])
visited[r][c] = 0
print(result)
기조의 Main 부분에서 필요한 부분을 추가하고 다듬어주었다.
2차원 배열의 각 요소를 dx, dy의 방향으로 돌면서 19개의 테트로미노를 확인해야 한다.
요소의 visited를 우선 1로 만들고 doMakeTetrmino로 블럭을 전부 확인한 다음 0으로 바꿔준다.
blockCnt는 1 값으로 시작한다. 어딜 방문하든 하나의 조각은 있기 마련이니까.
또한 totalValue에는 입력받은 숫자를 넣어줘 최댓값을 계산하게 한다.
# ---------- Function ----------
def doMakeTetromino(visited: list, x: int, y: int, blockCnt: int, totalValue: int) -> int:
global result
# success tetromino
if blockCnt == 4:
result = max(result, totalValue)
return
핵심인 doMakeTetromino 함수이다.
되도록 전역변수 사용을 지양하려 했지만, 이번 코드에서 만큼은 사용해야 했다.
result는 blockCnt가 4일 때만 값 변경이 있기에 global로 사용해도 괜찮다고 판단했다.
구체적인 코드를 적기 전 return문을 작성했다.
blockCnt가 4라면, 즉 테트로미노를 완성했다면 totalValue와 result 중 최댓값을 비교하고 return한다.
# ---------- Function ----------
# Checking 4 directions by backtracking
for i in range(4):
nx = dx[i] + x
ny = dy[i] + y
# Whether include, and not visited
if 0<=nx<row and 0<=ny<col and visited[nx][ny]==0:
# Other shapes
visited[nx][ny] = 1
doMakeTetromino(visited, nx, ny, blockCnt+1, totalValue+INPUT[nx][ny])
visited[nx][ny] = 0
이제 네 방향을 돌면서 백트래킹을 수행할 차례이다.
nx와 ny가 범위 내에 있으면서 아직 방문하지 않은 곳을 가야 한다.
Main의 입력받은 곳과 마찬가지로 방문한 곳을 1로 처리하고 doMakeTetromino를 수행, 끝이 나면 0으로 처리한다.
blockCnt는 1 더한 값을, totalValue에는 기존 값에 현재 방문한 숫자를 더하여 전달한다.
# ---------- Function ----------
# Shape ㅗ, ㅜ, ㅓ, ㅏ
if blockCnt == 2:
visited[nx][ny] = 1
doMakeTetromino(visited, x, y, blockCnt+1, totalValue+INPUT[nx][ny])
visited[nx][ny] = 0
하지만 위의 백트래킹으로는 ㅗ, ㅜ, ㅓ, ㅏ 모양을 만들 수가 없다.
그래서 블럭이 2개일 때 조건문으로 예외 처리를 해줘야 한다.
이때 x와 y 값을 조심해야 한다. 기존의 백트래킹은 nx와 ny를 전달한다.
ㅗ, ㅜ, ㅓ, ㅏ 모양을 위해서는 옆의 값을 더하되 x, y에서 다시 백트래킹을 수행해야 모양을 완성할 수 있다.
이렇게 코드를 작성하고 제출하니 이전에 시도했던 것들처럼 시간 초과가 발생했다.
코드를 작성하면서 마음에 걸렸던 부분을 확인해보았다.
위의 방식대로 코드를 작성하면 같은 모양을 중복해서 확인하리라는 생각을 했었다.
예제 입력 1을 넣고 코드를 VSC에서 실행한 마지막 12개의 결과를 살펴보았다. 벌써 2쌍이 같아버린다.
이를 방지하기 위해서는 이미 확인한 값을 체크하는 배열을 만들어서 검사해주든,
다른 조건의 return문을 만들어주든 시간을 줄여야 했다.
# ---------- Function ----------
# End condition) sum of all elements(for MAX) is smaller than result
if result >= totalValue + (MAX * (4-blockCnt)):
return
# ---------- Main ----------
MAX = max(map(max, INPUT))
그래서 차용한 아이디어가 처음에 말한 경향성이다.
결국 이 문제에서 필요한 것은 최댓값을 구하는 문제이다.
2차원 배열 입력에서 가장 큰 값을 MAX라는 변수에 저장했다고 가정해보자.
몇 개의 조각을 더했는지 모르겠지만 N개의 조각을 더한 합을 SUM이라고 가정해보자.
그리고 계산을 하면서 result에는 최댓값이 들어가있는 상태이다.
N개의 조각을 뺀 나머지 조각은 4-N개이다.
4-N개의 조각이 전부 MAX 값이라는 가정일 때 SUM + ((4-N) * MAX)가 result보다 작다면,
즉, 앞으로 조사할 조각 개수만큼 전부 MAX를 더해주었음에도 이미 result보다 작다면,
굳이 이 계산을 할 필요가 있는 건가? 아니 없다.
위의 코드를 추가해주고 나니 시간 초과를 피할 수 있었다.
시간도 188ms라니 Python3의 브루트포스 문제치고는 만족스러웠다.
# ---------- Function ----------
def Tendency(row: int, col: int, graph: list) -> int:
SUM = sum(map(sum, graph))
AVG = SUM / (row * col)
for x in range(row):
for y in range(col):
if graph[x][y] >= AVG:
graph[x][y] = 1
else:
graph[x][y] = 0
return graph