카카오가 문제를 어렵게 출제하기로 유명하니, 연습을 한다면 기왕이면 어럽게 하고자 카카오로 골랐다.
1번 문제는 예전에 손쉽게 풀었었고, 바로 다음 문제인 2번을 필연적으로 고르게 됐다.
문제 자체는 이미지도 없어서 짧은 편이다.
두 큐가 있을 때, 한 쪽에서 값을 꺼낸 뒤 다른 쪽 큐에 커낸 값을 넣는다.
어느 쪽 큐에서 꺼내든 상관없지만, 두 큐의 합이 같아질 때까지 이를 반복한다.
두 큐의 합이 같아지는 경우는 다양하게 있을 수 있다.
그럴 때 최소 횟수는 과연 얼마나 걸릴까를 구하는 문제다.
처음에는 두 큐를 활용한 방법이니 collections.deque를 사용해야 하나? 했지만 굳이 그럴 필요가 없다고 느꼈다.
deque를 사용하지 않고 해결하기 위해 생각한 방법은 누적합(prefix sum)을 활용하는 방법이다.
개수가 몇 개인지, 어디서부터 어디까지 더하는지는 우선순위가 상대적으로 낮다.
우선 두 큐의 합이 같아야 한다는 것이다.
그래서 두 큐를 연결한 다음, 마지막 요소(위의 예시에서는 30)의 반이 될 때까지 탐색을 진행한다.
요소를 더한 다음에 이 값을 비교하는 게, 누적합을 구한 뒤 뺄셈을 하는 방식이 생각났다.
따라서 빠르게 구할 수 있다고 생각해 누적합 방식을 채택했다.
이때 주의할 점은 2가지가 있다. 하나는 slicing이고, 다른 하나는 우선순위다.
우선 slicing을 생각해보자. 2 + 7 + 2 + 4일 때, 30의 절반인 15가 된다.
하지만 누적합을 활용하면 18 - 3, 즉 시작하는 위치는 한 칸 앞이 된다. 이 점을 유의해서 코드를 작성한다.
우선 순위를 생각해보자. 위에서는 15가 되는 구간이 2 + 7 + 2 + 4와 4 + 6 + 5로 2개가 있다.
문제의 목적은 "작업의 최소 횟수"를 구하는 문제다. 그러니까 시작 지점에서 최대한 가까워야 한다.
따라서 먼저 발견하는 범위가 정답이 된다.
def solution(queue1, queue2):
all_sum = sum(queue1) + sum(queue2)
if all_sum % 2 == 1:
return -1
count = 0
answer = all_sum // 2
prefix = queue1 + queue2
length = len(prefix)
# Calculating prefix sum
for i in range(1, length):
prefix[i] += prefix[i-1]
# Calculating min len dif
for start in range(length-1):
for end in range(start+1, length):
if prefix[end] - prefix[start] == answer:
count = start + end - len(queue1) + 2
return count
return -1
우선 같은 두 값을 더하면 무조건 짝수가 된다. (N + N = 2N)
그럼 모든 값을 더한 값이 홀수면, 애초에 성립이 불가능하다는 말이다.
그래서 조기 종료를 위해 if all_sum % 2 == 1: return -1 구문을 넣어줬다.
그 다음 위에서 생각한 것을 그대로 코드로 옮겼다.
누적합을 구하고(for i in range(1, length)),
각 요소들을 하나씩 확인하면서(for start in range(length-1) for end in range(start+1, length)),
만약 구간의 차가 정답과 같다면, 정답을 계산한다.
start와 end 지점은 하나의 큐가 가져야 할 범위다.
따라서 두 큐를 연결한 전체의 큐에서, 해당 범위만큼을 따로 빼내는 작업(몇 칸을 이동해야 하는지)을 세야 한다.
start의 앞부분을 다른 큐의 뒷부분으로 이동해야 한다. 위에서 유의할 점을 생각하면 start + 1만큼 이동한다.
end 자체가 아니라 앞의 queue1의 길이만큼 빼준 만큼 다른 큐의 뒷부분으로 이동해야 한다.
그리고 index는 0부터 시작하니 1을 더해줘야 한다. 그래서 end - len(queue1) + 1만큼 이동해야 한다.
따라서, 정답을 계산하는 식은 start + end - len(queue1) + 2가 된다.
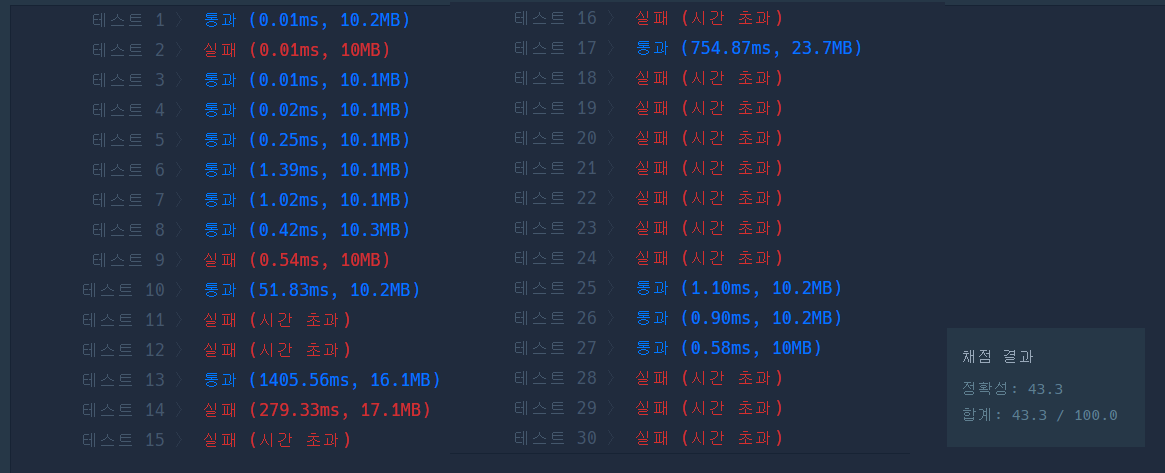
틀린 것은 둘째치더라도, TLE가 너무 많이 나온다.
생각해보니까 누적합에서 값을 찾을 때 이중 반복문을 활용해 시간복잡도가 O(n^2)이 나온다.
하나의 리스트에서 두 개의 위치 정보를 이용하여 탐색하는 방법.
하지만 시간복잡도가 O(n^2)보다는 짧아야만 한다.
모든 조건을 만족하는 알고리즘 '투 포인터'가 있었다.
투 포인터를 활용하면 누적합을 이용하기 애매해진다.
이용하라면 할 수는 있겠지만, 그래도 계속해서 추가적인 연산이 필요하다.
방법을 바꿔서 누적합이 아니라, 포인터가 움직일 때마다 연산을 하는 방법을 선택했다.
end 포인터가 이동하여 가리키는 요소를 더한다. 왜냐하면 새롭게 포함하는 값이기 때문이다.
start 포인터가 이동하기 전 가리키는 요소를 뺀다. 왜냐하면 범위를 벗어난 값이기 때문이다.
start와 end가 새로운 지점을 가리킬 때마다 sum() 내장 함수를 사용하는 방법은 지양한다.
sum() 내장 함수 자체가 O(n)이기 때문에 시간 초과가 걸릴 수 있기 때문이다.
def solution(queue1, queue2):
mid_sum, ep = 0, 0
full_que = queue1 + queue2
if sum(full_que) % 2 == 1:
return -1
half = sum(full_que) // 2
for sp in range(len(full_que)):
while mid_sum < half and ep < len(full_que):
mid_sum += full_que[ep]
ep += 1
if mid_sum == half:
return sp + ep - len(queue1)
mid_sum -= full_que[sp]
return -1
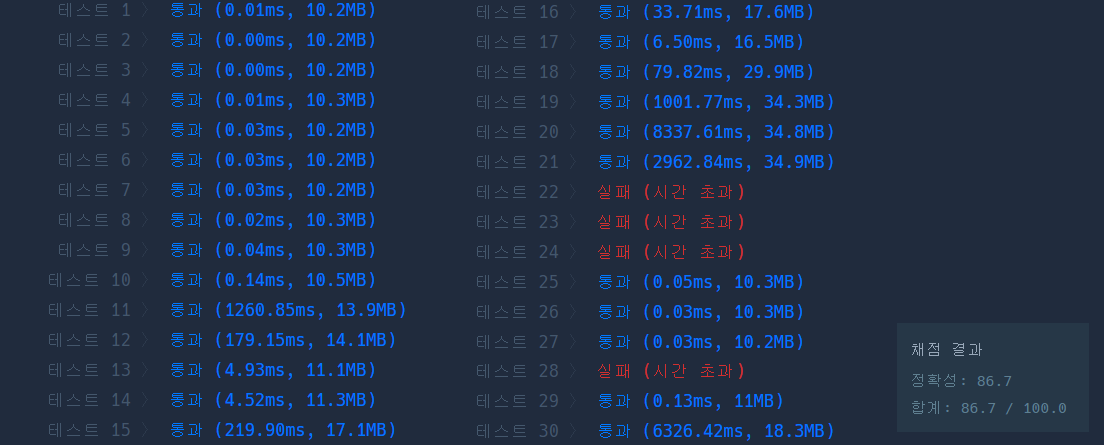
투 포인터를 활용한 알고리즘 방식을 코드를 다시 짰다.
이중 반복문 부분만 투 포인터로 바꾸고, 조기 종료 같은 부분은 그대로 유지했다.
투 포인터로 돌다가 역시나 처음에 만나는 값이 가장 적게 이동할 수 있는 값이다.
그래서 mid_sum이 half와 같아진다면 sp + ep - len(queue1)을 반환하고 종료한다.
이번에는 return 값에는 +2가 없어졌다.
sp(start pointer)와 ep(end pointer)가 가리키는 값이 먼저 한 칸씩 이동하기 때문에 굳이 +2를 할 필요가 없어졌다.
TLE는 확실하게 없어졌다. 하지만 2개의 반례가 있는 듯했다.
어떤 반례가 있나 생각해보니, 위의 코드는 start와 end가 다른 큐에 속하는 경우만 해당한다는 사실을 알았다.
본 코드에서 return하는 값은 sp + ep - len(queue1)이다.
이 경우는 위의 그림처럼 정상적인 경우라고 불러보자.
그럼 start가 Q1에 해당하는 자리에 있고, end가 Q2에 해당하는 자리에 있어야만 한다.
만약 start와 end가 모두 Q1에 있다면? 혹은 모두 Q2에 있다면? retrun은 달라져야 한다.
위의 그림처럼 start와 end가 모두 Q1 혹은 Q2에 있는 예외의 상황이 존재한다.
각각의 상황에서는 return값이 모두 달라지는 경우의 수를 크게 3가지로 나눴다.
1. start가 가장 처음 index를 가리키고 있을 때
2. end가 가장 마지막 index를 가리키고 있을 때
3. 둘 다 끝이 아닌 중간값을 가리키고 있을 때
1번의 경우는 '(start ~ end) + 나머지'에서 나머지만을 다른 큐로 이동해야 한다.
그러기 위해서는 (start ~ end)을 다른 큐의 뒤로 옮기고, 다른 큐의 전체를 기존 큐로 가져와야 한다.
따라서 return 값은 ep + length가 된다.
2번의 경우는 '나머지 + (start ~ end)'에서 나머지만을 다른 큐로 이동해야 한다.
이 경우는 쉽다. 나머지 부분만 다른 큐로 보내면 된다. 따라서 return 값은 sp가 된다.
3번의 경우는 '나머지 + (start ~ end) + 나머지'에서 양끝단의 나머지를 전부 떼어내야 한다.
이 경우는 처음과 유사하다. 처음부터 end까지 다른 큐로 보내고, length(다른 큐)와 나머지를 기존 큐로 보낸다.
따라서 return 값은 ep + length + sp가 된다.
if mid_sum == half:
if sp >= length and ep >= length:
sp -= length
ep -= length
if sp < length and ep < length:
if sp == 0:
return ep + length
elif ep == length - 1:
return sp
else:
return ep + sp + length
else:
return sp + ep - length
mid_sum == half 부분만 위에 보이는 코드처럼 바꿔주었다.
최대한 중복하는 코드를 줄이기 위해서 생각해보았다.
설명을 할 때 Q1에 해당하는 부분만 고려해주었다. 그야 Q1과 Q2는 사실상 같은 경우기 때문이다.
Q1에 해당하는 요소를 Q2에 보내고, Q2도 Q1으로 보낸다. 그럼 같은 경우다.
따라서 고려해야 하는 것은 index만 length만큼 뺴주면, '이동하는 횟수' 자체는 동일하다.
기존에 9번 14번은 그대로 틀린 상태고, 1번을 오히려 추가로 틀렸다.
로직에서 어떤 부분이 문제가 있을까 생각해보니, 언제나 처음이 가장 빠르다는 것을 보장해주지 않았다.
예를 들어서 queue1 값이 [2, 3, 2]이고, queue2 값이 [1, 1, 1]이라고 가정해보자.
그럼 전체의 합은 10이고, 각 큐가 5가 될 때까지 요소들을 이동할 것이다.
투 포인터로 값을 찾아보니, 이게 웬 걸 처음부터 2, 3만 있으면 5를 만족한다.
이 경우는 start가 처음에 있는 경우다.
ep + length값에 의해서 return(옮기는 최소 횟수)은 5가 된다.
진짜 그럴까? 아니다.
[2, 3, 2] 부분에서 [2, 3]을 더해도 5가 되는 건 맞지만, [3, 2]를 더해도 5가 된다.
따라서 queue1의 첫 요소인 2를 queue2로 옮기기만 해도 문제를 해결할 수 있다.
틀린 로직으로 운좋게 테스트 케이스를 통과해도 그게 과연 문제를 풀었다고 할 수 있을까?
아니라고 생각한다. 예외로 return하는 경우가 많아져 코드가 보기 싫었었다.
언제나 빠름을 보장하는 게 아니라는 것도 알았기에, 코드를 전면 수정했다.
처음으로 돌아가서, 다시 생각해보았다.
두 큐의 길이는 같고, 각 큐는 최대 300,000만의 길이를 갖는다.
만약 특별한 알고리즘 없이 하나하나 넘기면서 확인하는 방법은 어떨까?라는 생각을 했다.
TLE를 염두해야 하니, 얼마나 반복하는지를 가장 중요하게 고려해야 한다.
Q1과 Q2가 있는 초기 상태를 생각해보자. 그리고 값을 찾지 못하는 최악의 경우를 생각해보자.
Q1을 하나하나 넘겨서 Q2에 추가하면서 종료 조건이 되는지 확인한다. 종료를 안 했다.
그럼 다시 Q2를 Q1으로 하나하나 넘기면서 종료 조건이 되는지 확인한다. 이래도 종료를 안 한다.
이렇게 되면 Q1과 Q2가 다시 각각의 큐로 독립된 상태로 돌아왔다.
이번에는 Q2를 Q1으로 하나하나 넘기면서 종료 조건이 되는지 확인한다. 종료를 안 했다.