Basic of Recurrent Neural Networks (RNNs)

RNN은 sequence 데이터가 입/출력으로 주어진 상황에서
서로 다른 time step에서 들어오는 입력 데이터를 처리할 때, 동일한 파라미터의 모델을 사용한다는 것
RNN의 이전 결과가 다음 입력이 되지만, 필요에 따라 이전 결과를 출력할 수 있어야 한다.

RNN을 수식으로 나타낸다면 위와 같다
이때 각 step에서 결과 y_t를 확인하는 과정은 상황에 따라서 다르다.
만약 각 문장의 품사를 확인하는 문제라면, 매 단어마다 결과를 확인해야 한다.
만약 문장의 긍정/부정을 확인하는 문제라면, 최종 결과만을 확인하면 된다.

입력인 x_t는 3차원 벡터이고, RNN의 hidden layer(h_t-1)는 2차원 벡터라고 가정해보자.
그렇다면 RNN은 두 벡터를 모두 입력으로 받기에, 5차원 벡터를 입력으로 받는 모델인 셈이다.
이때 RNN의 hidden layer 차원(노드) 수는 사용자가 지정하는 hyper parameter이다.
함수의 동작 과정을 살펴보기 위해, 가중치 행렬이자 파라미터인 f_W를 자세하게 살펴보자.
입력이 5차원 벡터이고, h_t가 2차원 벡터가 되기 위해서는, 가중치 행렬 W는 2 * 5 행렬이어야만 한다.
이때 2 * 5의 각 행은 한 번씩, 5차원 입력(x_t(3차원) + h_t-1(2차원))과 한 번씩 곱해질 것이다
그럼 앞 3개 열은 x_t와 곱해지고, 뒤 2개 열은 h_t-1과 곱하고 결과를 더하는 것과 같다.
전체 W 행렬을 3개 2개의 열로 쪼개어 생각할 수 있다.
이때 앞 3개의 열은 x_t와 곱해서 h_t를 계산하는 가중치 행렬이니 W_xh라고 부르고,
뒤 2개의 열은 h_t-1와 곱해서 h_t를 계산하는 가중치 행렬이니 W_hh라고 부르자.
수식을 정리하면 h_t = (W_xh * x_t) + (W_hh * h_t-1)가 된다.
이때 활성화 함수로 비선형 함수인 tanh 함수를 사용한다.
출력 범위가 sigmoid는 0에서 1인 반면, tanh는 -1에서 1이기에 평균이 0에 가까워진다.
이는 학습을 더 잘할 수 있는 Zero-centered 환경이 된다.
그렇게 최종적으로 h_t = tanh((W_hh * h_t-1) + (W_xh * x_t)) 수식을 완성한다.
수식의 결과인 h_t는 hidden layer이지 특정 time step의 결과가 아니다.
처음 가정을 생각해보자. 입력인 x_t는 3차원 벡터이기에 출력인 y_t도 3차원 벡터여야만 한다.
그리고 h_t는 현재 2 * 1의 행렬이다.
즉, h_t를 y_t의 결과(크기)로 바꿔주기 위해서는 가중치 행렬을 한 번 더 곱해주어야 한다.
따라서 y_t = W_hy * h_t가 완성된다.
이렇게 나온 y_t는 또 다른 활성화 함수를 거쳐서, 사용자가 원하는 class 개수를 얻어낸다.
Type of RNNs
RNN을 사용하면 입/출력이 sequence 데이터인 경우를 모두 다룰 수 있다.
이때 입력만 sequence든 출력만 sequence든 모두 sequence 데이터든 상관이 없는 모델이다.
아래는 입/출력 time step 개수에 따른 RNN 과정과 다양한 예시이다.
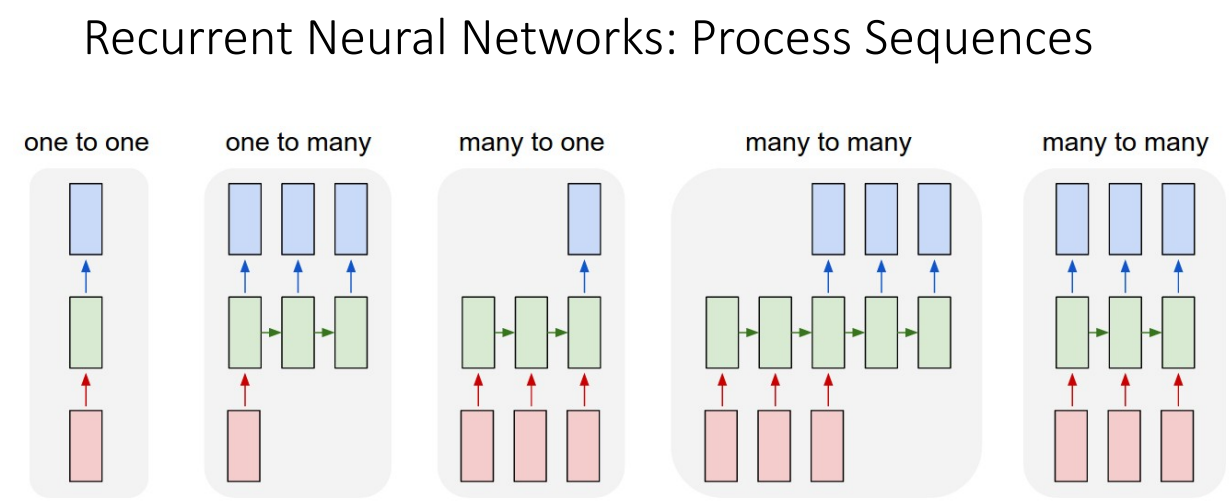
| 분류 | 예시 | |
| 1 | one to one | [키, 몸무게, 나이]와 같은 정보가 입력일 때, 저혈압/고혈압인지 분류하는 형태의 태스크 |
| 2 | one to many | '이미지 캡셔닝'과 같이 하나의 이미지를 입력으로 주면, 설명글을 생성하는 태스크 이때 입력은 처음에만 들어간다. 이후에 들어가는 입력 데이터는 모두 0값을 가진다. |
| 3 | many to one | '감성 분석'과 같이 문장을 넣으면, 긍/부정 중 하나의 레이블로 분류하는 태스크 예를 들면 문장의 각 단어를 embedding하여 입력으로 넣어준다. |
| 4 | many to many | '기계 번역'과 같이 입력값을 끝까지 다 읽은 후, 번역된 문장을 출력해주는 태스크 입력의 모든 단어 embedding을 읽은 후, 마지막 단어에서부터 결과를 반환한다. |
| 5 | many to many | 4번의 many to many와 다른 점은, delay를 허용하지 않거나 없는 실시간 경우이다. 비디오 분류와 같이 영상의 프레임 레벨에서 예측하는 태스크 혹은 각 단어의 품사에 대해 태깅하는 PoS와 같은 태스크 |
'공부 > BoostCourse 자연어 처리' 카테고리의 다른 글
| 07. NLP DL - Backpropagation through time and Long-Term-Dependency (0) | 2025.03.12 |
|---|---|
| 06. NLP DL - Character-level Language Model (0) | 2025.03.11 |
| 04. NLP Basic - Word Embedding (2)GloVe (0) | 2025.03.09 |
| 03. NLP Basic - Word Embedding (1)Word2Vec (0) | 2025.03.08 |
| 02. NLP Basic - 기존의 자연어 처리 기법 (0) | 2025.03.07 |