
1. 뉴럴 네트워크를 활용한 분류
1.1. 데이터
분류(Classfication)
여러 특징 데이터를 기반으로 클래스(데이터 종류)를 예측하는 태스크다.
예측하는 클래스의 수가 두 가지인 경우 '이진 클래스 분류'라고 부른다.
이진 클래스보다 많은 분류를 수행하는 경우 '다중 클래스 분류'라고 부른다.
숫자 데이터 세트 MNIST
0~9의 숫자를 손으로 쓴 이미지와 정답을 묶은 데이터 세트이다.
훈련 데이터 60,000건, 테스트 데이터 10,000건으로 이루어져있다.
이미지는 그레이 스케일(무채색)로 28 × 28 pixel 사이즈다.
1.2. Colab에서의 실행
본 교재에서는 Google에서 제공하는 텍스트 에디터, Colab을 사용한다.
웹 브라우저에서 텍스트와 코드를 작성하는 클라우드 환경이다. (Jupyter Notebook을 생각하면 편하다.)
언어는 python을 지원하며, 실행 환경에 GPU도 제공해 인공지능 코드를 실행하기에 적합하다.
하지만, 무료와 유료 버전 차이가 있어서 일정 용량 이상은 메모리 초과로 실행할 수 없다.
# Tensorflow : 딥 러닝 패키지
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Activation, Dense, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
# Numpy : 고속 배열 계산 패키지
import numpy as np
# Matplotlib : 그래프 표시 패키지
import matplotlib.pyplot as plt
# Google Colab 상에 그래프를 표시하는 명령
%matplotlib inline일반적인 컴퓨터 실행 환경에서는 python 관련 모듈과 패키지를 설치해야 하지만,
Colab에서는 이미 기본적으로 설치되어 있어 import로 호출만 해주면 사용 가능하다.
# train_images : 훈련 이미지 배열 # train_labels : 훈련 라벨 배열
# test_images : 테스트 이미지 배열 # test_labels : 테스트 라벨 배열
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print(train_images.shape) # (60000, 28, 28)
print(train_labels.shape) # (60000,)
print(test_images.shape) # (10000, 28, 28)
print(test_labels.shape) # (10000,)mnist의 숫자 데이터 세트를 load_data()를 사용해 4가지 배열로 읽어들인다.
그 후 shape로 배열의 형태(차원)을 확인한다. (60000, 28, 28)은 60000 × 28 × 28의 3차원 배열이다.
주석(실행 결과)를 보면, 훈련 데이터와 라벨은 6만 건, 테스트 데이터와 라벨은 1만 건임을 볼 수 있다.
물론 이미지 사이즈는 28 × 28 pixel 이다.
# 데이터 세트 이미지 확인
for i in range(10):
# subplot(nrows, ncols, index) : 서브 플롯 추가, 인수는 행/열 수와 플롯의 위치
plt.subplot(1, 10, i+1)
# imshow(X, cmap=None) : 이미지 표시, 인수는 이미지와 컬러 맵
plt.imshow(train_images[i], 'gray')
# 그래프(이미지 결과)를 보여주는 코드
plt.show()
# 가장 앞의 10건의 훈련 라벨을 확인
print(train_labels[0:10]) # [5 0 4 1 9 2 1 3 1 4]
plt.imshow(train_images[i], 'gray')를 통해 첫 10개의 훈련 이미지를 확인하면 위와 같은 그림이 나온다.
print(train_labels[0:10])과 동일한 상태임을 확인할 수 있다.
1.3. 데이터 전처리
전처리(Preprocessing)
학습을 하기 전, 데이터를 뉴럴 네트워크에 적합한 형태로 바꾸어주는 작업
# datasets 이미지 전처리
train_images = train_images.reshape(train_images.shape[0], 784)
test_images = test_images.reshape(test_images.shape[0], 784)
# 이미지 전처리 후의 shape 확인
print(train_images.shape) # (60000, 784)
print(test_images.shape) # (60000, 784)이번에 사용할 뉴럴 네트워크는 1차원 배열을 입력으로 받는다.
따라서 28 × 28 크기의 2차원 이미지를 28 × 28 = 784 크기의 1차원 배열로 바꾸어 주어야 한다.
이때 reshape()함수를 사용하면 배열의 차원을 변경할 수 있다.

images 데이터를 1차원 배열로 바꾸었으니, labels 데이터는 원-핫 인코딩으로 바꾸어준다.
원-핫 인코딩(One-Hot Encoding)은 어떤 요소만 값이 1이고, 나머지는 전부 0으로 표현하는 방법이다.

원-핫 인코딩은 '분류' 결과를 출력할 때 사용한다. 10분류의 경우 출력을 10개 준비한다.
정답의 출력을 1.0에, 오답의 출력을 0.0에 수렴하도록 출력한다.
추론 시에는 출력(예상값)이 가장 높은 것을 예측 결과로 한다.
# datasets 라벨 전처리
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 라벨 전처리 후의 shape 확인
print(train_labels.shape) # (60000, 10)
print(test_labels.shape) # (60000, 10)숫자를 원-핫 인코딩으로 변환하려면 to_categorical() 함수를 사용한다.
1.4. 모델 생성

유닛(Unit)
ANN을 구성하는 각 노드들을 말한다.
레이어(층)에 따라 입력 노드, 은닉 노드, 출력 노드 등으로 나뉜다.
전결합 레이어(Fully-Connected Layer, FC Layer)
각 유닛이 다음 레이어의 모든 유닛과 결합한 형태의 레이어
옆의 그림에서 256개의 유닛을 가진 layer가 '입력층'
128개의 유닛을 가진 layer가 '은닉층'
10개의 유닛을 가진 layer가 '출력층'이다.
드롭아웃(Dropout)
과적합을 방지하는, 모델의 정확도와 정밀도를 높이는 방법 중 하나
임의의 레이어 유닛을 무효로 하여 특정 뉴런에 대한 의존을 방지한다.
이 방식으로 범용성(Generalizability)을 높인다.
무효화하는 비율은 일반적으로 50%정도로 설정한다.
# 모델 생성
model = Sequential()
# Dense : 전결합 레이어 생성 함수, 인수는 유닛 수와 활성화 함수, 입력 데이터 형태
model.add(Dense(256, activation='sigmoid', input_shape=(784,))) # 입력 레이어
model.add(Dense(128, activation='sigmoid')) # 히든 레이어
# Dropout : 드롭아웃 생성 함수, 인수는 유닛을 무효로 만드는 확률
model.add(Dropout(rate=0.5)) # 드롭아웃
model.add(Dense(10, activation='softmax')) # 출력 레이어
'''
model.add(Dense(256, input_shape=(784,)))
model.add(Activationi('sigmoid'))
이와 같은 방법으로 Dense의 activatin을 인자가 아니라 따로 분리해서 지정할 수 있다.
'''다음과 같은 코드를 통해 레이어와 드롭아웃 모델을 생성한다.
1.5. 활성화 함수
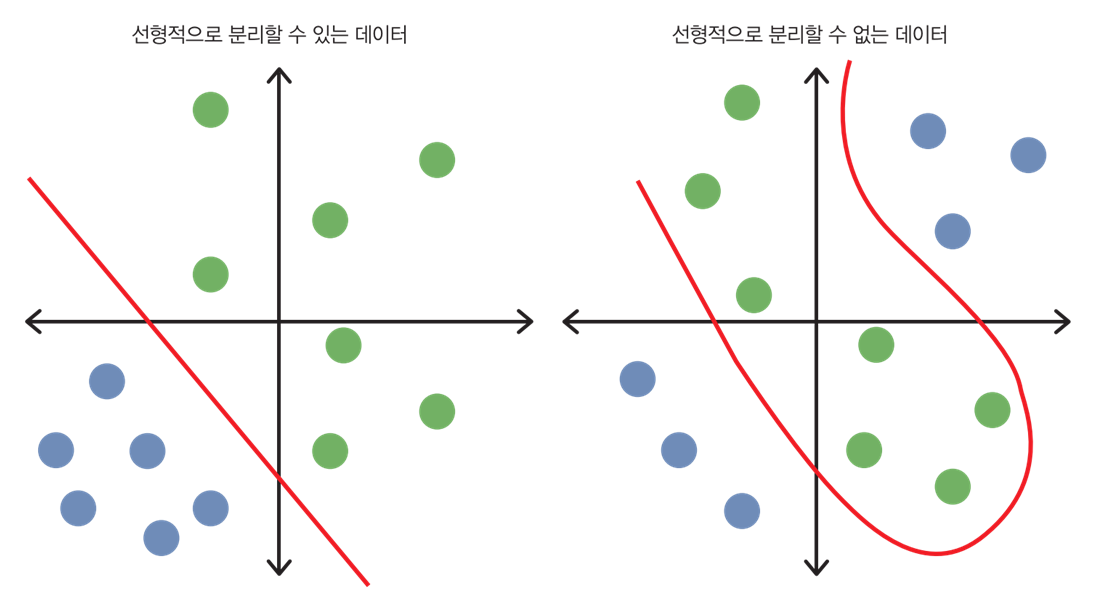
02 딥러닝 개념 - 퍼셉트론(https://miny-genie.tistory.com/87#No2)에서 설명한 것처럼
활성화 함수는 어떤 문제의 선형/비선형 구조를 해결할 수 있다.
02 딥러닝 개념 - 활성화 함수 선택(https://miny-genie.tistory.com/87#No6)에서 소개했지만 한 번 더 알아보자.

여기서는 총 다섯 개의 활성화 함수를 설명한다.
보통 입력층과 은닉층에서는 '시그모이드 함수'를 주로 사용하며, 출력층에서는 '소프트맥스 함수'를 사용한다.

기본적으로 그래프의 가로축은 특정 노드의 시그마 계산값, 세로축은 활성화 함수 적용값이 된다.
시그모이드(Sigmoid) 함수의 식과 그래프는 위와 같다.
중심점(입력이 0)일 때 시그모이드의 기울기는 0.25의 값을 갖는다.
입력이 작을수록 출력이 0에 가까워지며, 클수록 출력이 1에 가까워진다.
그렇기에 보통 '2 클래스 분류'에 주로 사용한다. (출력 A가 0.2, 출력 B가 0.8이라면 B일 확률이 80%)
시그모이드는 다음과 같은 문제점이 있어, 최근에는 잘 사용하지 않는다.
ㆍ 입력 0에 대해 출력이 항상 양수라 학습 효율이 좋지 않다(입력 0에 대해서는 출력 0이 비교적 좋다).
ㆍ 입력이 너무 크거나 작으면 '기울기 소실 문제'가 발생한다.

쌍곡 탄젠트(Hyperbolic Tagent) 함수의 식과 그래프는 위와 같다.
쌍곡 탄젠트는 시그모이드와 같은 연속 함수이지만, 출력의 범위가 -1 ~ 1이다.
출력의 범위가 -1에서 1이므로, 시그모이드의 (입력 0에 대한) 학습률 문제를 해결했다.
또한, 중심에서의 기울기가 0.5로 시그모이드보다 커 기울기 소실 문제를 완화했다.
└ 완화했을 뿐이지, 쌍곡 탄젠트에서도 기울기 소실 문제는 존재한다.

항등(Identity) 함수의 식과 그래프는 위와 같다.
입력을 변환하지 않고 그대로 출력한다. 회귀 등에서 값을 변환하지 않고 그대로 출력할 때 사용한다.

ReLU 함수의 식과 그래프는 위와 같다.
입력이 0 이하인 경우는 출력이 0이며, 입력이 0 이상인 경우는 항등함수와 같은 형태를 취한다.
입력이 양수일 경우, 미분값이 항상 1로 역전파 계산도 간단해진다.
또한 시그모이드 함수의 미분치보다 커서, 기울기 소실 문제를 해결할 수 있다.
ReLU 함수는 컨볼루셔널 뉴럴 네트워크(CNN; https://miny-genie.tistory.com/87#No8)에서 많이 사용한다.

소프트맥스(Softmax) 함수의 식과 그래프는 위와 같다.
다중 클래스 분류에서 많이 사용하는 활성화 함수이다. 결과의 총 합계가 1이 되게끔 결과를 출력한다.
(Ex. A 10% B 30% C 25% D 15% E 20%)
1.6. 컴파일
컴파일 시 '손실 함수', '최적화 함수', '평가 함수' 3가지를 설정한다.

손실 함수(Loss Function)
모델의 예측값과 실제 결과값 사이의 오차를 계산하는 함수이다. (비용을 계산하는 함수)
이 오차를 기반으로 '최적화 함수'와 '손실 함수'의 결과가 0에 가까워지도록 가중치(weight)와 편향값(bias)을 조정한다.

최적화 함수(Optimizer Function)
'손실 함수'의 결과가 0에 가까워지도록 가중치(weight)와 변향값(bias)을 최적화하는 함수이다.
미분으로 구한 값을 학습률, 이폭(epoch), 과거 가중치 차 등을 고려해 가중치 변경폭을 결정한다.
└ epoch은 시행 횟수를 이야기한다.

평가 함수(Evalulation Function)
모델의 성능을 측정하기 위해 사용하는 지표이다.
측정 결과는 학습을 수행하는 fit() 값에 저장하고, 클래스 등에 표시한다.
└ fit() 함수의 매개변수는 밑에서 코드 주석으로 설명한다.
# 컴파일
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.1), metrics=['acc'])본 교재의 예시에서는 손실 함수는 'categorical_crossentropy', 최적화 함수는 'SGD', 평가 함수는 'acc'로 한다.
최적화 함수 SGD는 lr을 인수로 갖는다. 이는 학습률이다.
└ 학습률(Learning Rate) : 각 레이어의 가중치를 얼마만큼 변경할지 결정하는 수
학습률이 낮으면 학습이 잘 진행할 수 없고, 높으면 최적화를 넘어 값이 발산(한 점에 모이지 않음)한다.
1.7. 학습ㆍ그래프ㆍ평가ㆍ추론
# 학습
history = model.fit(train_images, train_labels, batch_size=500, epochs=5, validation_split=0.2)
'''
fit(x=None, y=None, batch_size=None, epochs=1, validation_split=0.0)
x(ndarray) : 훈련 데이터
y(ndarray) : 훈련 라벨
batch_size(int) : 배치 사이즈, 훈련 데이터를 몇 개 단위로 훈련할지 결정
클수록 훈련이 빠르지만, 메모리 소비량 증가
epochs(int) : 훈련할 횟수(cycle), 훈련 데이터를 1회 전부 사용하면 1 epoch으로 간주
validation_split(float) : 훈련 데이터 중 검증 데이터로 사용할 데이터 비율
훈련 데이터의 일부를 분리해 훈련하지 않고, 검증에 사용
'''model.fit()을 사용하여 학습을 시작한다.
함수의 각 매개변수는 주석과 같은 의미를 가진다.

데이터를 나누면 위와 같다.
전체 데이터 세트가 있으면, 학습 데이터(train_data)와 테스트 데이터(test_data)로 나눈다.
그리고 학습 데이터를 validationi_split()으로 실제 훈련용 데이터와 검증용 데이터로 나눈다.

학습 코드를 실행하면 실시간으로 학습이 진행되는 것을 볼 수 있다.
그때 여러 가지 정보가 나오는데 loss, acc, val_loss, var_acc는 각각 위와 같은 의미를 지닌다.
loss와 val_loss는 컴파일 시 손실 함수로 계산한 값이다.
acc와 val_acc는 컴파일 시 평가 함수로 계산한 값이다.
# plot(x, label=None) : 그래프에 선을 표시, 인수는 데이터 및 라벨
plt.plot(history.history['acc'], label='acc')
plt.plot(history.history['val_acc'], label='val_acc')
# nlabel(label) : n축 라벨 지정
plt.ylabel('accuracy')
plt.xlabel('epoch')
# legend(loc) : 플롯한 데이터의 라벨 설명 표시, loc='best'를 사용해 가장 적합한 위치에 표시
plt.legend(loc='best')
# show() : 그래프에 데이터를 표시
plt.show()

plt.show()를 하면 matplotlib가 그래프를 다음과 같이 보여준다.
# 평가
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('loss: {:.3f}\nacc: {:.3f}'.format(test_loss, test_acc ))
'''
evaluate(x=None, y=None, batch_size=None)
x(ndarray) : 테스트 데이터
y(ndarray) : 테스트 라벨
batch_size(int) : 배치 사이즈
print 결과
loss : 0.xxx, acc : 0.xxx
0.xxx로 표기한 이유는 실행하는 컴퓨터마다 비율이 달라지기 때문이다.
'''
# 추론할 이미지 표시
for i in range(10):
plt.subplot(1, 10, i+1)
plt.imshow(test_images[i].reshape((28, 28)), 'gray')
plt.show()
# model.predict(x=None) : x(ndarray) 입력 데이터
test_predictions = model.predict(test_images[0:10])
# np.argmax(v, axis=None) : v(ndarray) 배열, axis(int) 최댓값을 읽을 축 방향
test_predictions = np.argmax(test_predictions, axis=1)
print(test_predictions)
마지막으로 평가와 추론 코드를 작성해주면, 평가에서는 오차와 정답률을 출력한다.
추론 코드에서는 입력한 테스트 데이터에 따른 예상 숫자를 위의 그림처럼 출력한다.
2. 뉴럴 네트워크를 활용한 회귀
2.1. 데이터
회귀(Regression)
다수의 특징 데이터를 기반으로 연속값 등의 수치를 예측하는 태스크다.
분류에서는 숫자 데이터 세트 MNIST를 활용했다면, 'Boston house-prices' 데이터 세트를 활용한다.
주택 정보 데이터 세트 Boston house-prices
미국 보스턴시 주택의 특징과 정답 가격 라벨을 묶은 데이터 세트이다.
훈련 데이터 404건, 테스트 데이터 102건으로 이루어져있다.
보스턴 시 주택 데이터는 13개의 특징 항목으로 관리한다.
2.2. Colab에서의 실행
# Tensorflow : 딥 러닝 패키지
from tensorflow.keras.datasets import boston_housing
from tensorflow.keras.layers import Activation, Dense, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import Adam
# Pandas : 데이터 분석 패키지
import pandas as pd
import numpy as np
# Matplotlib : 그래프 표시 패키지
import matplotlib.pyplot as plt
# Google Colab 상에 그래프를 표시하는 명령
%matplotlib inline주택 정보 데이터 세트를 회귀 방법으로 학습시키기 위해 import(호출)하는 패키지들
# datasets 준비
(train_data, train_labels), (test_data, test_labels) = boston_housing.load_data()
# datasets shape 확인
print(train_data.shape) # (404, 13)
print(train_labels.shape) # (404,)
print(test_data.shape) # (102, 13)
print(test_labels.shape) # (102,)datasets을 로드하고 각각의 값을 확인하는 과정은 분류와 동일하다.
# 데이터 세트 데이터 확인
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
df = pd.DataFrame(train_data, columns=column_names)
df.head()
# 데이터 세트 라벨 확인
print(train_labels[0:10]) # [15.2 42.3 50. 21.1 17.7 18.5 11.3 15.6 15.6 14.4]dd

dd
2.3. 데이터 전처리
# 데이터 세트 전처리(셔플)
order = np.argsort(np.random.random(train_labels.shape))
train_data = train_data[order]
train_labels = train_labels[order]
# 데이터 세트 전처리(정규화)
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
train_data = (train_data - mean) / std
test_data = (test_data - mean) / stddd

dd
2.4. 모델 생성

dd
# 모델 생성
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(13,)))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))dd
2.5. 컴파일
# 컴파일
model.compile(loss='mse', optimizer=Adam(lr=0.001), metrics=['mae'])dd

dd

dd
2.6. 학습ㆍ그래프ㆍ평가ㆍ추론
# EarlyStopping 준비
early_stop = EarlyStopping(monitor='val_loss', patience=30)dd
# 학습
history = model.fit(train_data, train_labels, epochs=500, validation_split=0.2, callbacks=[early_stop])dd
# 그래프 표시
plt.plot(history.history['mean_absolute_error'], label='train mae')
plt.plot(history.history['val_mean_absolute_error'], label='val mae')
plt.xlabel('epoch')
plt.ylabel('mae [1000$]')
plt.legend(loc='best')
plt.ylim([0,5])
plt.show()dd
# 평가
test_loss, test_mae = model.evaluate(test_data, test_labels)
print('loss:{:.3f}\nmae: {:.3f}'.format(test_loss, test_mae))dd
# 추론할 가격 표시
print(np.round(test_labels[0:10]))
# 추론한 가격 표시
test_predictions = model.predict(test_data[0:10]).flatten()
print(np.round(test_predictions))dd
3. 컨볼루셔널 뉴럴 네트워크를 활용한 이미지 분류
3.1. 데이터
3.2. CNN 개념
3.3. Colab에서의 실행
3.4. 데이터 전처리
3.5. 모델 생성
3.6. 그 이후의 과정
3.7. TPU 사용
4. ResNet을 활용한 이미지 분류
4.1. ResNet 개념
4.2. Colab에서의 실행
4.3. 데이터 전처리
4.4. 모델 생성과 컴파일
4.5. ImageDataGenerator 준비
4.6. LearningRateScheduler 준비
4.7. 그 이후의 과정
'학교 공부 > 인공지능 개론' 카테고리의 다른 글
| 04_1 강화 학습 (0) | 2022.10.13 |
|---|---|
| 04 강화 학습 개념 (0) | 2022.10.13 |
| 02 딥 러닝 개념 (0) | 2022.09.30 |
| 01 알파 제로와 머신 러닝 개요 (0) | 2022.09.25 |