
1. 알파고와 알파고 제로, 그리고 알파 제로
2. 딥 러닝 개요
2.1. 딥 러닝에 대해서
2.2. 뉴런과 뉴럴 네트워크
2.3. 모델 작성, 학습, 추론
2.4. 지도 학습, 비지도 학습, 강화 학습
2.5. 컨벌루셔널 뉴럴 네트워크와 순환 뉴럴 네트워크
3. 강화 학습 개요
3.1. 강화 학습 용어
3.2. 강화 학습 사이클
3.3. 정책 계산 방법
4. 탐색 개요
4.1. 탐색에 대해서
4.2. 완전 게임 트리와 부분 게임 트리
4.3. 탐색 알고리즘 종류
교재 : 알파제로를 분석하며 배우는 인공지능
중간중간 교재와는 상관없는 내용 정리도 작성 예정
1. 알파고와 알파고 제로, 그리고 알파 제로
알파고(AlphaGo) : 딥마인드(DeepMind)에서 개발한 인공지능 바둑 프로그램
알파고 제로(AlphaGo Zero) : 2017년 10월에 발표한 알파고의 최신 버전
알파 제로(AlphaZero) : 2017년 12월에 발표한 알파고 제로의 최신 버전
└ 알파고 제로를 발표한 뒤 정확하게 48일 후에 발표했다.
2. 딥 러닝 개요
2.1. 딥 러닝에 대해서
딥 러닝(Deep Learning)
대량의 데이터 속에서 규칙을 발견해, 분류ㆍ판단ㆍ추론을 위한 규칙을 만드는 머신러닝 방법

인공지능(Artificial Intelligence)이 예측ㆍ판단하기 위한 규칙을 사람이 만들어야 한다.
하지만 그 사람이 해당 분야의 전문가라는 보장이 없으며, 몇몇 기준은 애매성을 띄기도 한다.
이렇게 작성한 프로그래밍을 '규칙 기반(Rule Based) 프로그래밍'이라고 한다.

규칙 기반 프로그래밍은 사람이라는 명확한 한계가 있다.
그래서 컴퓨터가 대량의 데이터를 스스로 분석하고 규칙을 학습하는 '머신 러닝(Machine Learning)'이 나왔다.
데이터와 입력을 기반으로 통계적 구조를 추출, 결과적으로 값들의 규칙을 만들어낸다.
규칙을 도출하는 방법 중 하나가 '딥 러닝(Deep Learning)'이다.
사람의 신경세포인 뉴런을 참고하여 '뉴럴 네트워크(Neural Network)'라는 모델을 통해 머신러닝을 수행한다.
└ 뉴럴 네트워크는 인공 신경망(ANN; Artificial Neural Network)과 동일한 의미이다.
2.2. 뉴런과 뉴럴 네트워크

'뉴런(Neuron)'은 사람의 신경 세포이다. 그리고 위의 그림은 뉴런을 모델화한 그림이다.
간단하게 설명하면 입력이 있고, 각 입력마다 가중치가 있다.
각 입력과 가중치를 곱하고 그것들을 전부 더한다. (X1W1 + X2W2 + ... + XnWn)
이 값이 임곗값(Θ)보다 크면 1, 작으면 0을 출력한다.

W1과 W2를 1.0으로 Θ를 1.5로 설정하면, 뉴런 모델에서 AND 연산을 수행할 수 있다.

하지만 저런 단일 뉴런 모델로는 복잡한 문제를 해결하지 못한다. 그래서 뉴런 모델을 나열해 레이어(Layer)를 만든다.
수십억 개의 트렌지스터를 모아 CPU를 만들 듯, 레이어들을 모아 뉴럴 네트워크를 만든다.
└ 레이어는 입력을 받아들이는 '입력 레이어(Input Layer)'
└ 입력 레이어와 출력 레이어 사이에서 연산을 수행하는 '히든 레이어(Hidden Layer)'
└ 출력을 수행하는 '출력 레이어(Output Layer)'
이때 히든 레이어는 여러 개를 생성할 수 있는데, 4개 이상이 되면 '딥 뉴럴 네트워크(Deep Neural Network)'라고 한다.
2.3. 모델 작성, 학습, 추론
모델 작성(Modeling)
뉴럴 네트워크의 구조를 작성하는 단계이다. 입력ㆍ히든ㆍ출력 레이어의 수와 용도를 정한다.
학습 전의 뉴런은 가중치ㆍ파라미터ㆍ바이어스(B) 등의 값이 정확하지 않아 0이나 상수, 난수 등으로 초기화 한다.
└ 바이어스(편향값; Bias) : 모든 (입력 X 가중치) 값을 더한 뒤에 따로 더해주는 임의의 상수
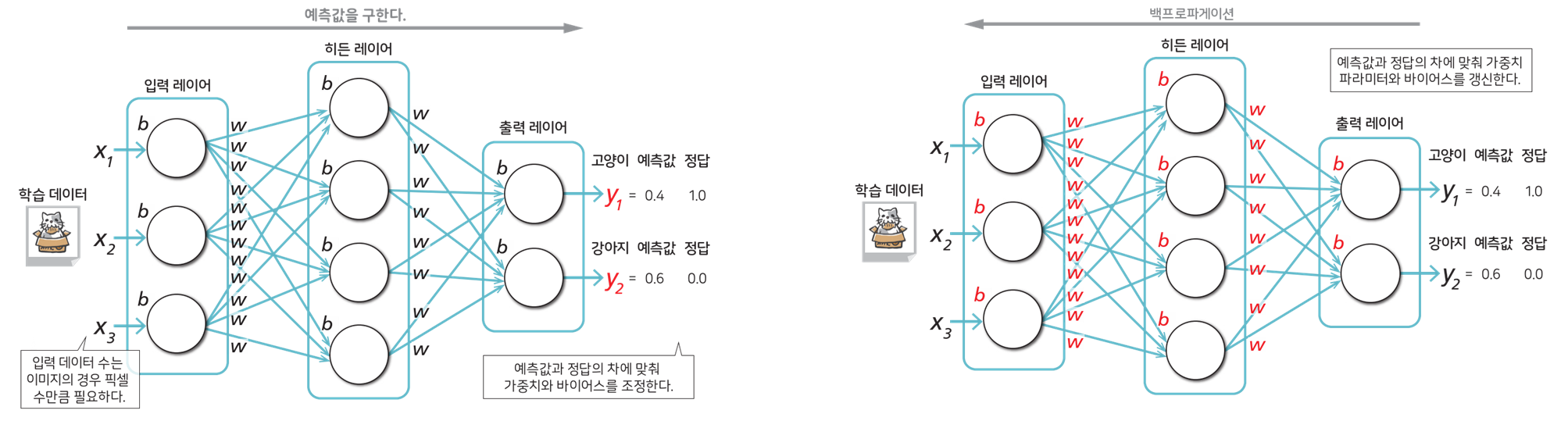
학습(Learning)
입력한 데이터에 맞춰 예측값을 출력하도록 가중치ㆍ파라미터ㆍ편향값을 최적화한다.
이때 대량의 데이터와, 데이터에 따른 정답을 입력해 연산ㆍ조정하는 과정을 반복한다.
└ 백프로파게이션(Backpropagation) : 예측값과 정답의 차가 줄어들도록 여러 값을 조정하여 갱신하는 과정
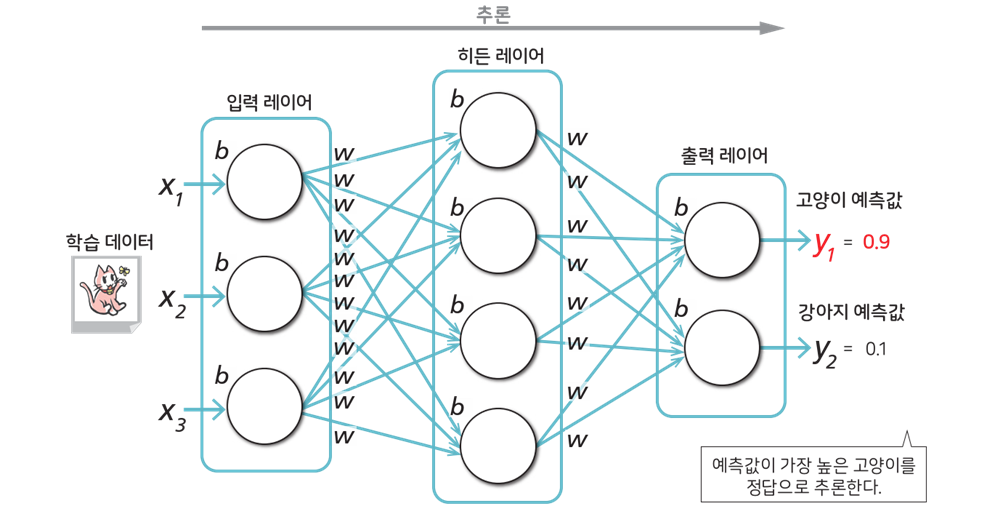
추론(Inference)
학습 완료 후, 테스트 데이터를 입력해 예측값을 확인한다. 가장 값이 높은 결과를 정답이라고 추론한다.
2.4. 지도 학습, 비지도 학습, 강화 학습
지도 학습(Supervised Learning)
입력과 출력의 관계를 학습하는 방법이다.
예측의 토대가 되는 '정답 데이터'와 학습에 사용하는 '학습 데이터' 세트로 학습시킨다.
이렇게 추론 모델을 생성하는 방법은 분류와 회귀의 방법으로 나눈다.

지도학습 - 분류(Classification)
여러 특징 데이터를 기반으로 클래스(데이터 종류)를 예측하는 태스크다.
예측하는 클래스의 수가 2인 경우 '이진 클래스 분류'라고 부른다.
└ 어떤 사진을 보고 고양이냐 강아지냐를 고르는 태스크가 이에 해당한다.
이진 클래스보다 많은 분류를 수행하는 경우 '다중 클래스 분류'라고 부른다.
└ 어떤 글자를 보고 이 글자가 무엇인지 확인하는 태스크가 이에 해당한다.

지도학습 - 회귀(Regression)
여러 특징 데이터를 기반으로 연속값과 같은 수치를 예측하는 태스크다.
└ 특정한 결과로 나오는 것이 아닌 어떠한 값으로 나오는 경우이다.

비지도 학습(Unsupervised Learning)
데이터의 구조를 학습하는 방법이다.
학습 데이터만을 사용해 학습을 수행하며, 잠재적인 패턴을 도출하는 추론 모델을 생성한다.
비지도 학습 - 클러스터링(Clustering)
학습 데이터가 가진 패턴을 발견해 비슷한 패턴을 가진 성질의 데이터를 모으는 방법이다.
└ 의류 쇼핑몰에서 유사 구매자들을 구분하는 방법이 이에 해당한다.

강화 학습(Reinforcement Learning)
에이전트(주체)가 환경의 상태에 맞춰 어떤 행동을 해야 보상을 가장 많이 받는지를 구하는 방법이다.
지도 학습과 비지도 학습과 달리, 학습 데이터가 주어지지 않은 채 시행 착오를 통해 학습한다.
2.5. 컨벌루셔널 뉴럴 네트워크와 순환 뉴럴 네트워크
뉴럴 네트워크(Neural Network)는 특성이 다른 몇 가지 모델이 존재한다.
크게 컨벌루셔널 뉴럴 네트워크(CNN)과 순환 뉴럴 네트워크(RNN)으로 나눈다.
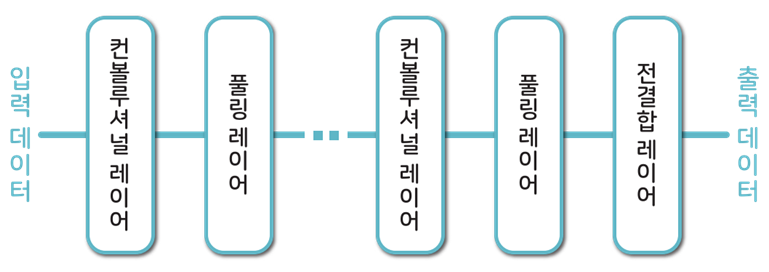
컨벌루셔널 뉴럴 네트워크(CNN; Convolutional Neural Network)
이미지 인식 분야에서 주로 사용하는 뉴럴 네트워크이다.
컨볼루셔널 레이어(Convolutional Layer)와 풀링 레이어(Pooling Layer)의 조합으로 만든다.
└ 컨볼루셔널 레이어 : 입력 이미지의 특성을 유지하며 압축하는 레이어
└ 풀링 레이어 : 왜곡과 변형에 영향을 덜 받게끔 견고함(Robustness)을 확보하는 레이어

순환 뉴럴 네트워크(RNN; Recurrent Neural Network)
시계열(동영상 분류, 자연어 처리, 음성 인식 등) 분야에서 주로 사용하는 뉴럴 네트워크이다.
└ 시계열(時系列) : 일정 시간 간격으로 배치된 데이터들의 수열
RNN의 특징은 히든 레이어에서 자기 피드백을 할 수 있다.
하지만 이 자기 피드백은 오차가 발생하거나 연산량이 증가하여 시간이 오래 걸린다는 단점이 있다.
그래서 이 문제를 해소한 LSTM(Long Short-Term Memory)라는 RNN이 나왔다.
3. 강화 학습 개요
3.1. 강화 학습 용어
강화 학습(Reinforcement Learning) : 학습 데이터 없이 시행 착오를 통해 학습하는 딥 러닝 방법
에이전트(Agent) : 강화 학습에서 행동하는 주체
환경(Envirionment) : 에이전트가 존재하는 세계(배경)
행동(Action) : 에이전트가 환경에서 일으키는 움직임
상태(State) : 에이전트의 행동에 따라 변화하는 환경 요소
보상(Reward) : 에이전트의 행동에 따라 좋고 나쁨을 표시하는 지표
정책(Policy) : 어떤 상황에서 어떤 행동을 수행할 확률
즉시 보상(Inmediate reward) : 행동 직후에 발생하는 단기적인 보상
지연 보상(Discounted Reward) : 미래에 발생하는 장기적인 보상
수익(Interest) : 모든 보상의 합을 최대화하는 것
3.2. 강화 학습 사이클

1. 에이전트는 처음 판단 기준이 없으므로, 랜덤으로 행동을 결정한다.
2. 에이전트는 보상을 받을 때, 어떤 상태에서 어떤 행동을 할 때 어떤 보상을 받았는지 기억한다.
3. 경험을 기반으로 정책을 계산한다.
4. 무작위 행동을 계속하며 정책을 기반으로 행동을 결정한다.
5. 2~4의 단계를 반복하며 수익을 계산한다.
이러한 과정을 마르포크 결정 과정(MDP; Markov Decision Process)라고 한다.
학습을 종료할 때까지의 1회 학습을 에피소드(Episode)라고 하며, 1회 행동을 스텝(Step)이라고 한다.
3.3. 정책 계산 방법

정책 반복법(Policy Iteration)
정책을 따라 이동하며, 성공 시 선택한 행동이 중요하다고 판단해 그 행동을 많이 선택하는 방법이다.
이러한 정책 반복법으로는 정책 경사법(Policy Gradient)이라는 알고리즘이 있다.
가치 반복법(Value Iteration)
다음 상태 가치와 현재 상태 가치 차이를 계산하고, 그 차이만큼만 현재 상태 가치를 늘리는 방법이다.
이러한 가치 반복법으로는 Sarsa, Q 학습이라는 알고리즘이 있다.
4. 탐색 개요
4.1. 탐색에 대해서
탐색(Exploration)
현재의 상황을 기점으로, 몇 수 앞까지의 상황을 읽어낸다.
읽어낸 상황의 평가들을 기반으로 현재 상황에서 가장 좋은 다음 한 수를 선택하는 방법이다.
탐색에서는 상황(국면) 전개를 위해 게임 트리를 사용해 모델화 한다.

게임 트리(Game Tree)
상황(국면)을 노드로 표시하고, 경우의 수를 선으로 표시한 트리 구조이다.
사각형은 자신이 수를 둘 차례의 국면이고, 원형은 상대방이 수를 둘 차례의 국면을 표시한다.
루트 노드(Root Node) : 가장 상위 노드
리프 노드(Leaf Node) : 가장 하위 노드
부모 노드(Parent Node) : 한 단계 상위 노드
자식 노드(Child Node) : 한 단계 하위 노드
형제 노드(Brother Node) : (부모 노드 기준으로) 본인 이외의 자신 모드들
4.2. 완전 게임 트리와 부분 게임 트리
완전 게임 트리(Complete Game Tree) : 게임을 시작할 때부터 선택할 수 있는 모든 수를 포함하는 트리
부분 게임 트리(Partial Game Tree) : 현재 국면에서 주어진 시간 내에 탐색 가능한 부분만을 포함하는 트리
4.3. 탐색 알고리즘 종류
ㆍ 미니 맥스법(Minimax Algorithm)
ㆍ 알파 베타법(Alpha-Beta)
ㆍ 원시 몬테카틀로 탐색(Monte Cario Method)
ㆍ 몬테카틀로 트리 탐색(Monte Cario Tree Search)
'학교 공부 > 인공지능 개론' 카테고리의 다른 글
| 04_1 강화 학습 (0) | 2022.10.13 |
|---|---|
| 04 강화 학습 개념 (0) | 2022.10.13 |
| 03 딥 러닝 (0) | 2022.10.13 |
| 02 딥 러닝 개념 (0) | 2022.09.30 |