개요
DevOps(Development Operation)
소프트웨어 개발과 운영 사이의 전체 파이프라인을 자동화하여 빠르고 안정적인 배포를 목표로 한다.
MLOps(Machine Learning Operation)
데이터가 바뀜에 따라 해석부터 모델 개발과 배포, 모니터링의 전체 생명주기를 자동화하고 운영하는 걸 목표로 한다.
기존의 모델은 평가만 하고, 다른 모델들은 학습까지하여 계속해서 새롭고 좋은 모델을 만들어낸다.
모델 재학습 및 교체, 배포 주기는 운영 관리하는 사람들에게 전적으로 달려있다.
성능이 저하됬을 때 알림을 보낸다든가, 반 년마다 갈아엎든가, MLOps 라인을 전자동화하여 매일 모델을 갈아치우는 곳도 있다.
MLOps 춘추전국시대 정리라는 자료가 괜찮다고 공유받았다.
Swagger
개발자가 REST 웹 서비스를 설계, 빌드, 문서화하는 일을 도와주는, 대형 도구 생태계의 지원을 받는 오픈 소스 프레임워크

실시간 인텔리전스가 사용하는 언아는 KQL이다.
| Azure 리소스를 활용할 실시간 | Fabric을 활용한 실시간 |
| 입력 - ASA(SQL) - CosmosDB | 입력 - Event Stream(KQL) - Event house |
Fabric Data Science Preprocessing by Wrangler

Azure에서 제공하는 오렌지주스 판매량 데이터를 가져와서 전처리 연습을 한다.
이를 위해 create에서 notebook을 하나 만들어서 wrangler 기반의 전처리를 한다.
Data Wrangler는 Fabric에서 제공하는 pandas 기반 전처리 UI 도구 혹은 Power Query 편집기다.
즉 어려운 코드형 데이터 전처리를 UI 기반의 전처리로 할 수 있게끔 도와준다.
# Azure storage access info for open dataset diabetes
blob_account_name = "azureopendatastorage"
blob_container_name = "ojsales-simulatedcontainer"
blob_relative_path = "oj_sales_data"
blob_sas_token = r"" # Blank since container is Anonymous access
# Set Spark config to access blob storage
wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token)
print("Remote blob path: " + wasbs_path)
# Spark reads csv
df = spark.read.csv(wasbs_path, header=True)
import pandas as pd
df = df.toPandas()
df = df.sample(n=500, random_state=1) # 데이터가 크므로 500개의 샘플만 사용
# 각 열의 데이터 타입을 올바르게 설정
df['WeekStarting'] = pd.to_datetime(df['WeekStarting'])
df['Quantity'] = df['Quantity'].astype('int')
df['Advert'] = df['Advert'].astype('int')
df['Price'] = df['Price'].astype('float')
df['Revenue'] = df['Revenue'].astype('float')
df = df.reset_index(drop=True)
df.head(4)사용한 코드는 위와 같고, 데이터의 크기가 커 첫 번째 셀의 실행 시간이 꽤 걸린다.

Data Wrangler를 사용하여 데이터프레임 전처러를 진행해본다.
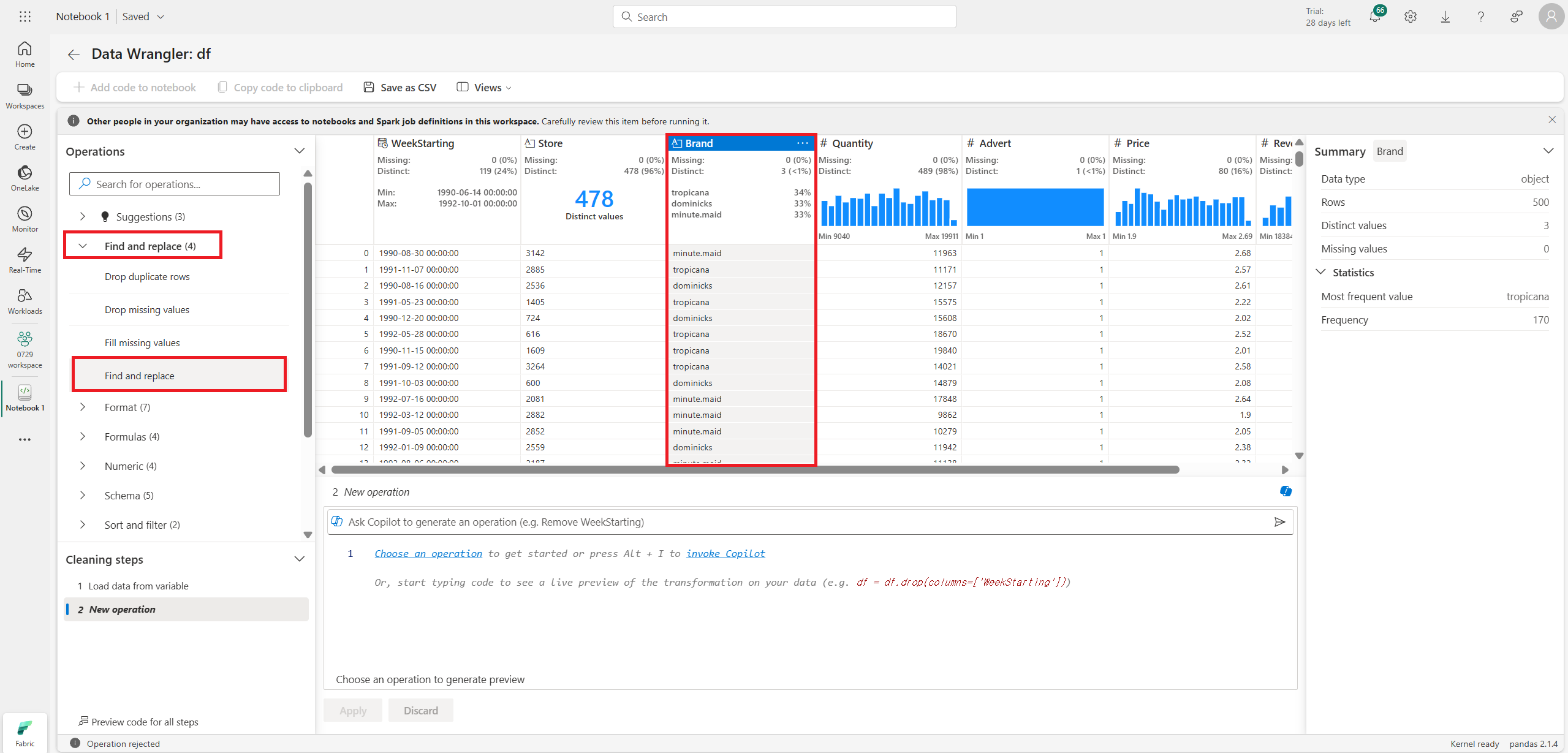
처리하고 싶은 컬럼(여기서는 Brand)를 고른 뒤, 'Find and replace'에서 결측치 처리를 한다.

온점(.)을 띄어쓰기(white space)로 변경한다.
중앙에 변경 전과 변경 후의 상태를 보여준다.
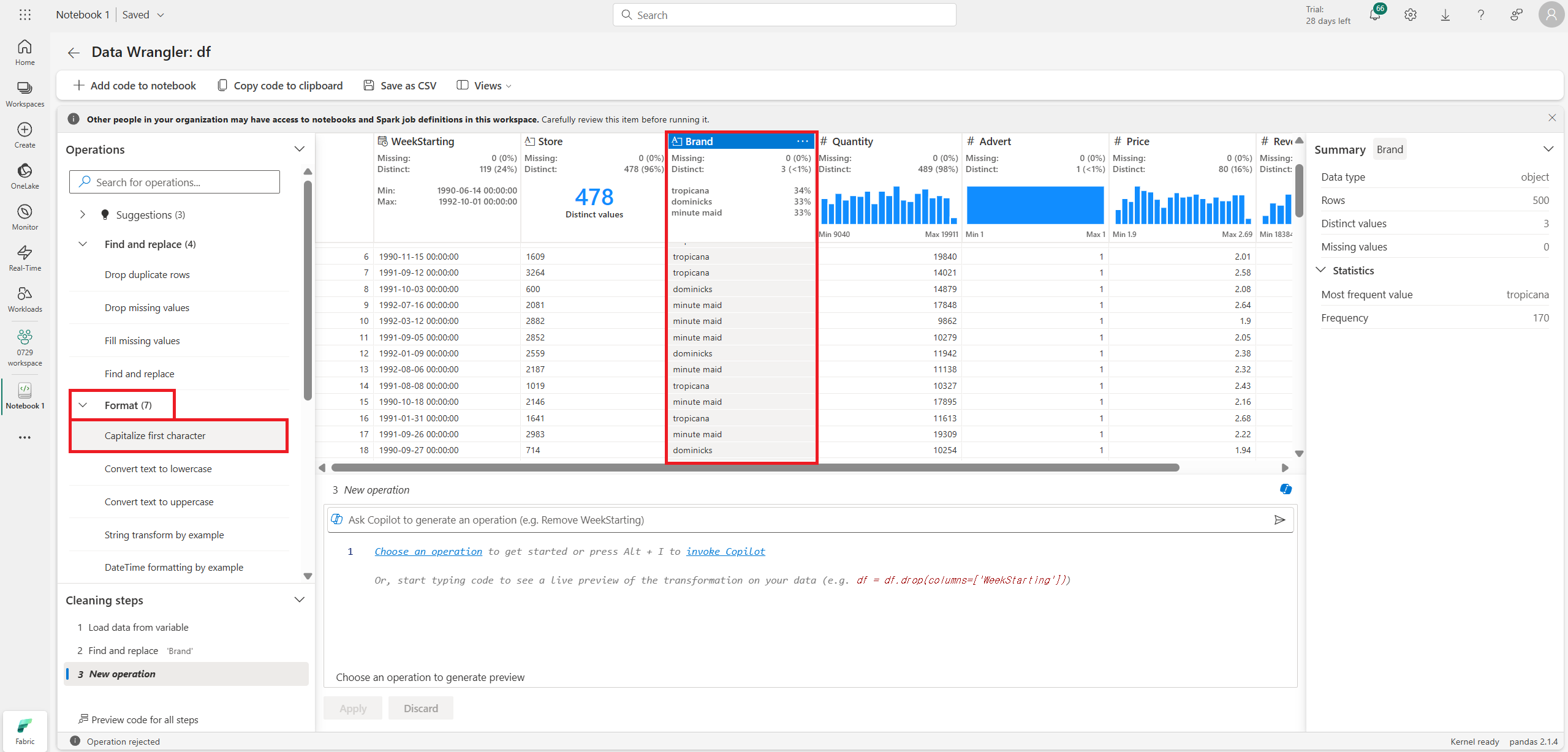
글자의 대소문자 변경도 가능하다.

단어의 첫 글자를 대문자(Capitalization) 형태로 바꿔준다.
이때 Capitalize all words를 하면 띄어쓰기 기준으로 모든 단어의 첫 글자를 대문자로 바꾼다.
이후 좌상단의 'Add code to notebook'을 하면 해당 전처리 코드가 notebook에 들어간다.

적용하면 바로 df에 적용하는 게 아니라 사용자 정의 함수 형태로 입력한다.
즉 여기서도 입맛에 맞게 변수명과 자잘한 코드를 변경할 수 있다.

그밖에도 One-hot encode도 가능하다.

Encode missing values는 비어있는지 아닌지에 대한 True/False 컬럼을 하나 더 추가해준다.

Filter로 행이나 열을 제거(필터링)하는 것도 가능하다.
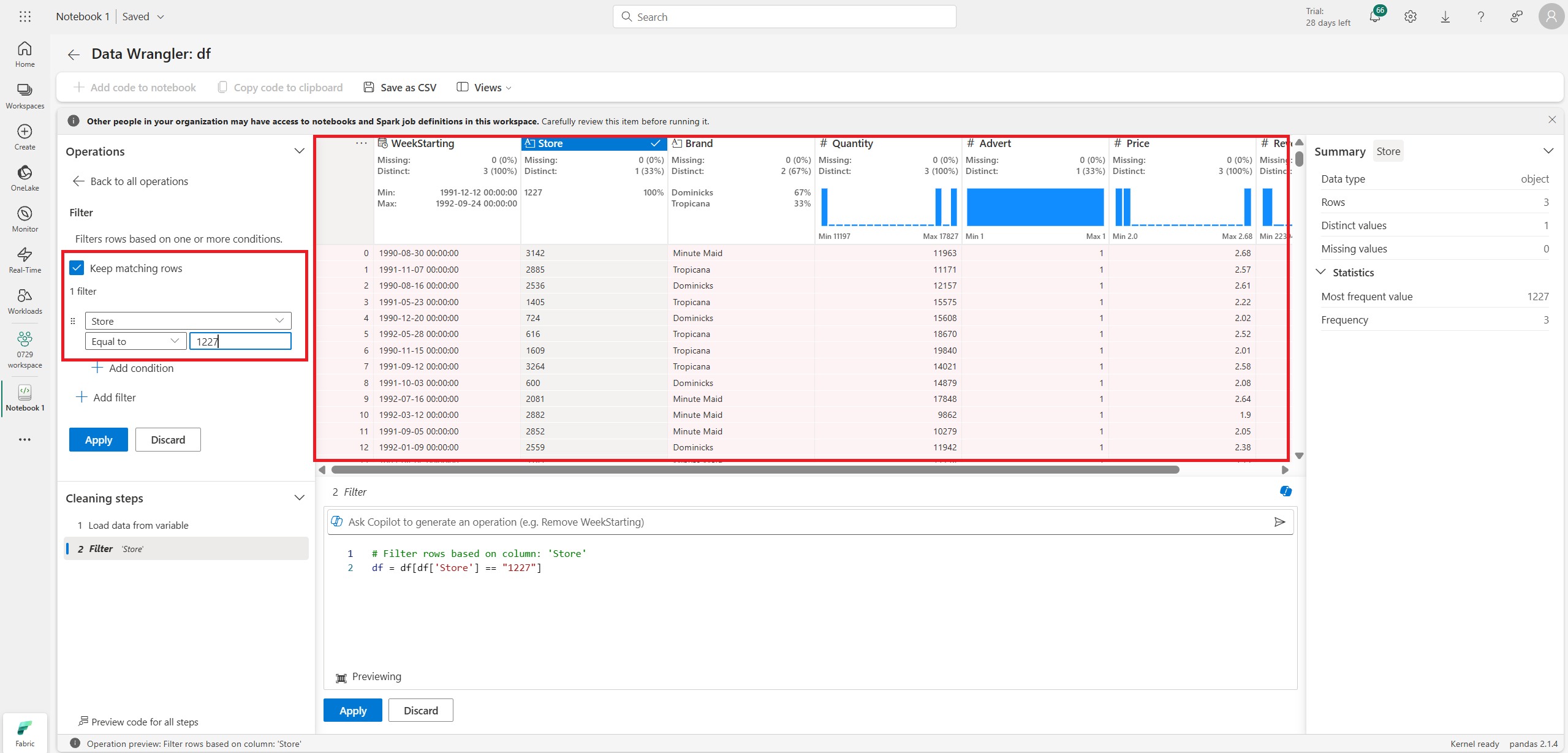
원하는 행 혹은 열과 원하는 기준을 선택할 수 있다.
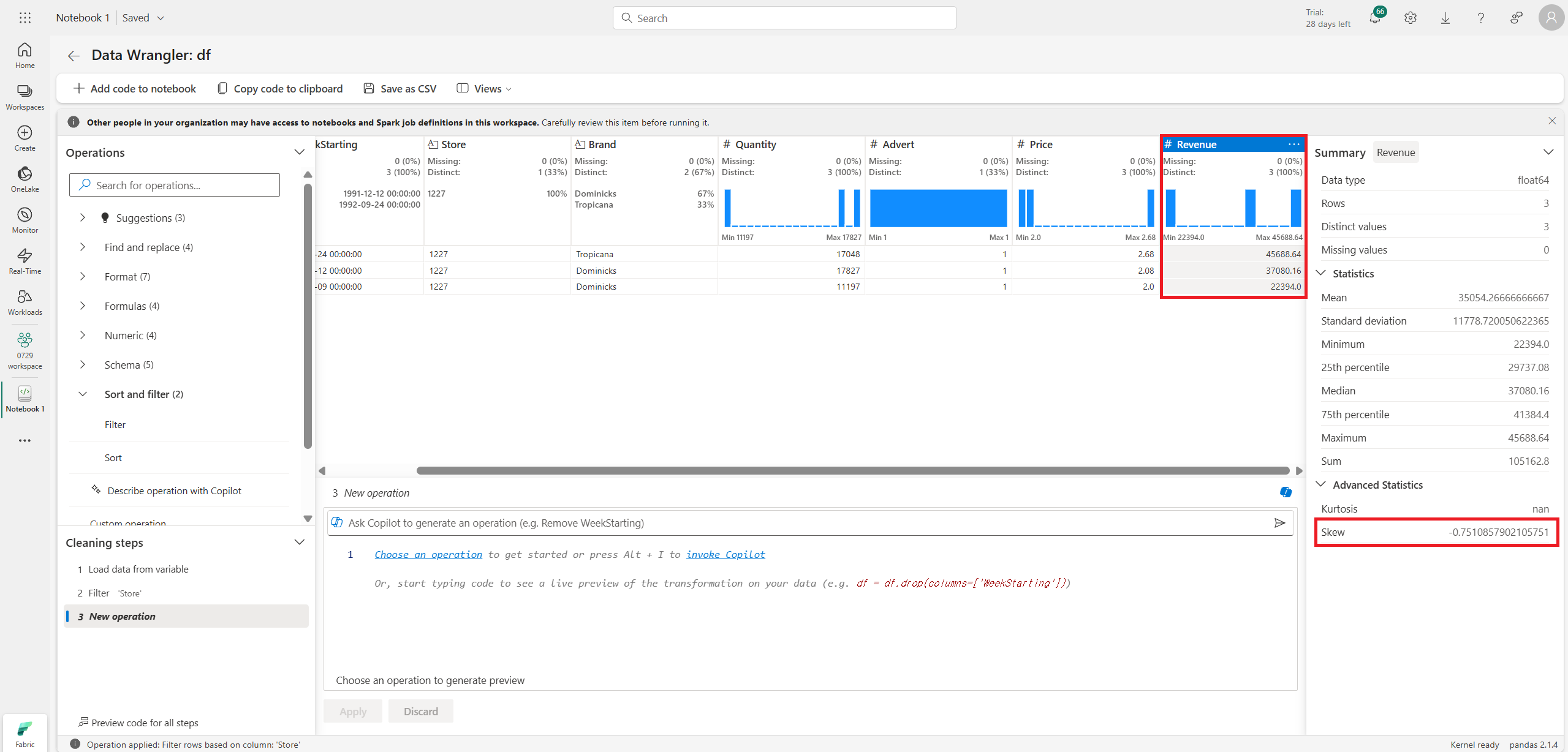
이후 y값(목표값, 종속변수)에 해당하는 Revenue를 눌러보면 우측에서 Summary로 상태를 볼 수 있다.
Skewness(왜도)가 -0.75로 음의 왜도를 띄는 것도 알 수 있다.
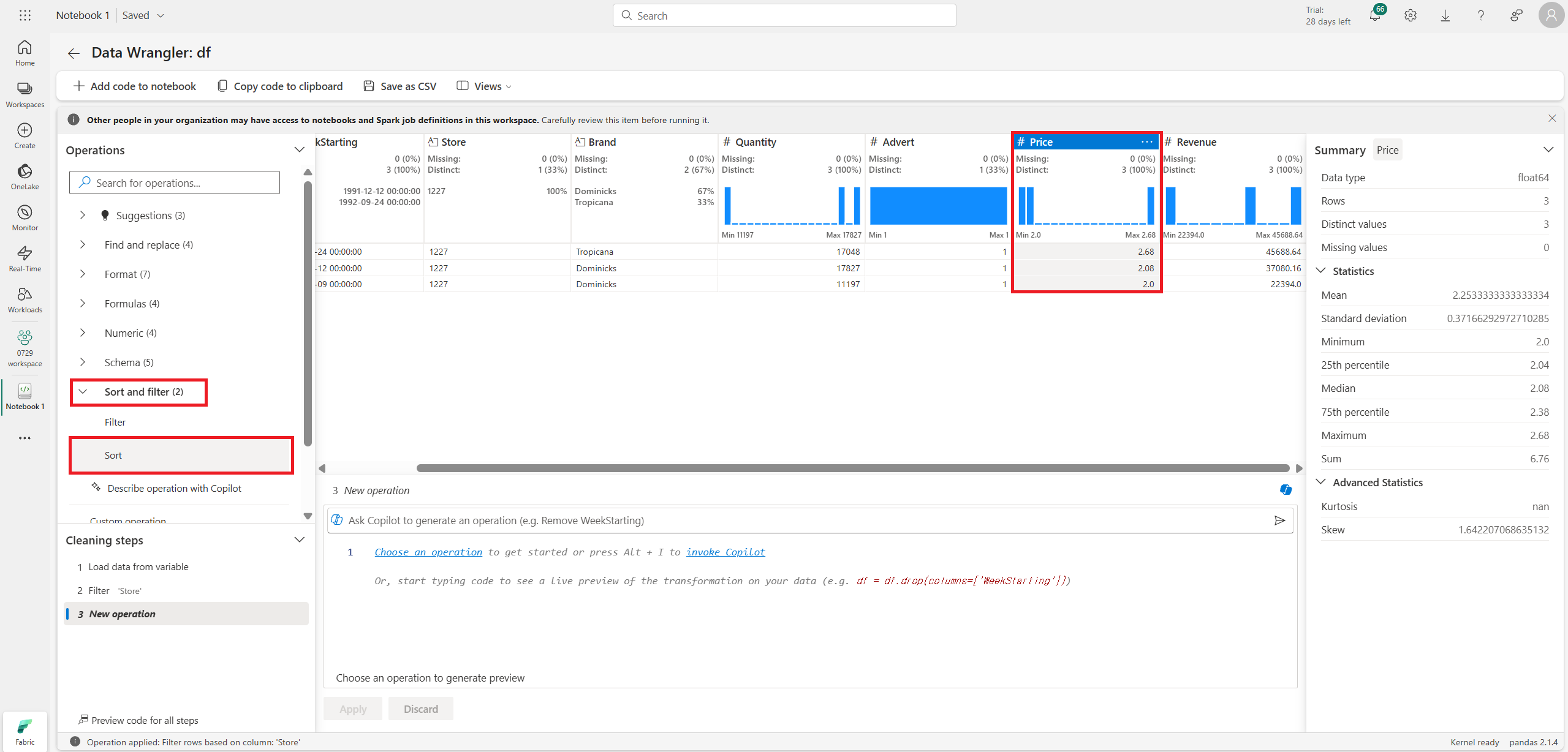
정렬도 가능하다.

정렬은 column을 선택한 다음 화살표를 눌러 ASC, DESC를 바꿔준다.
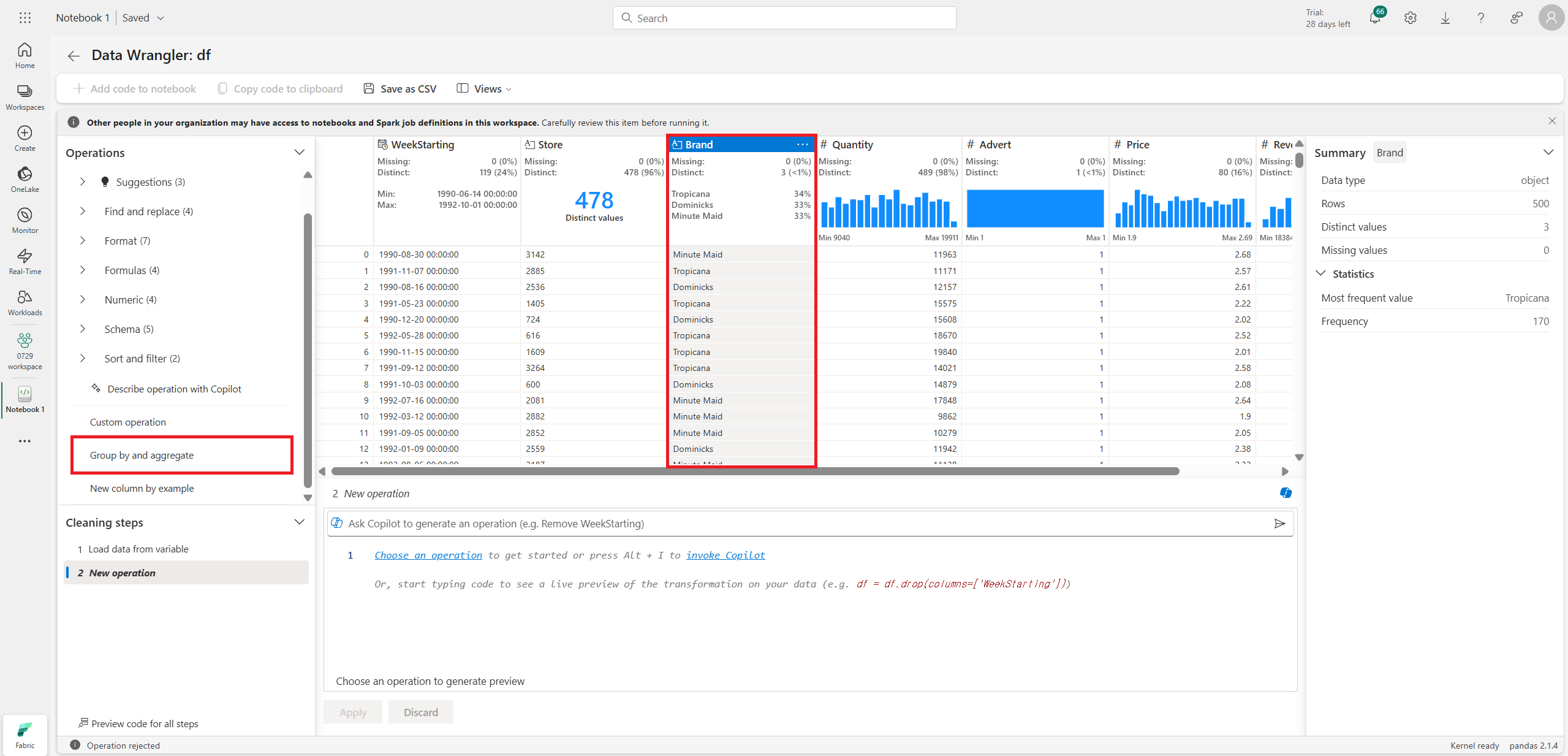
집계도 가능하다.
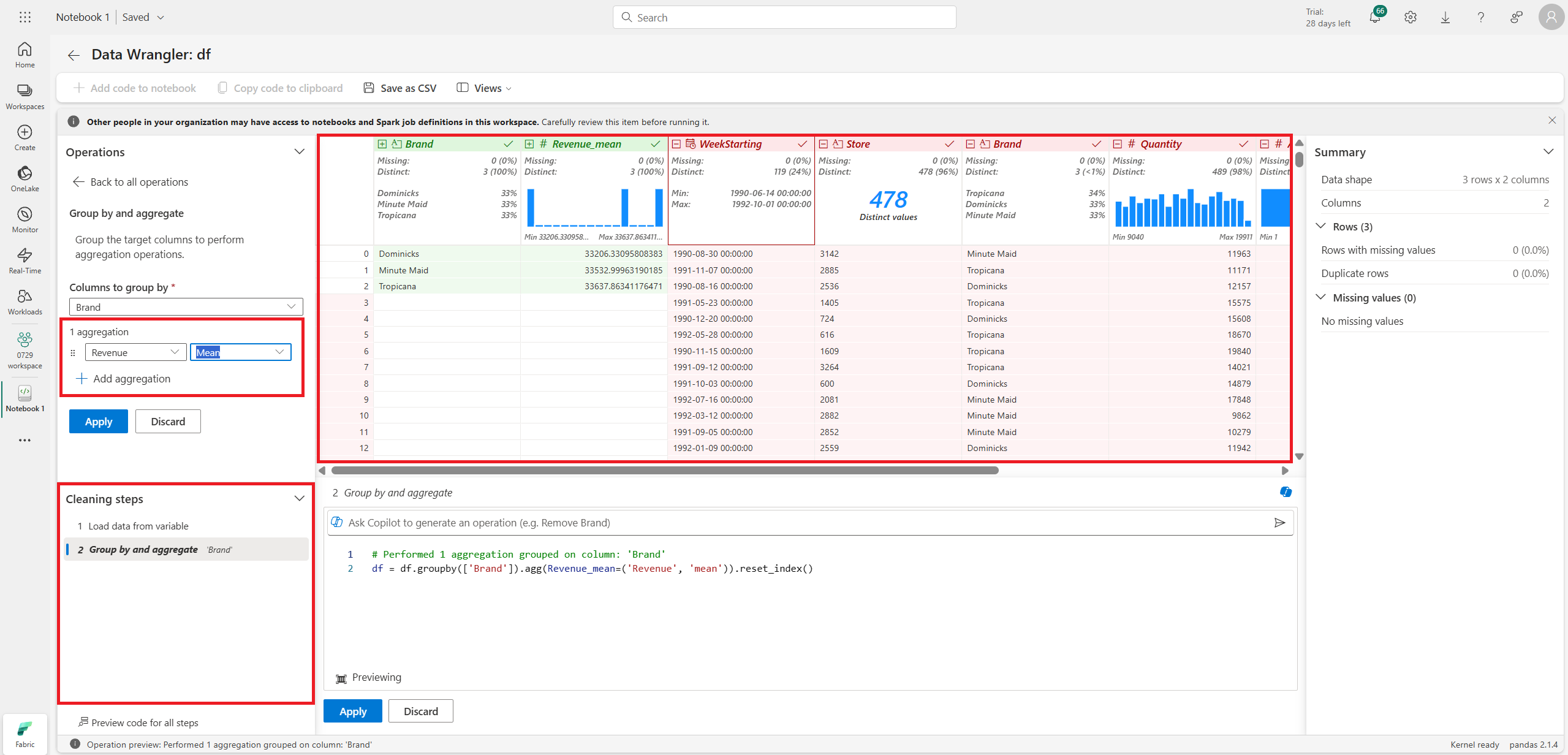
집계하려는 column과 무엇을 기준으로 할지에 대한 column, 측정값(mean, min, max 등)을 선택하면 된다.
참고로 이렇게 따라온 전처리는 좌하단의 'Cleaning steps' 창에서 제거하면 되돌릴 수 있다.
PowerBI의 Power Query 편집 상태에서 우측에 있는 step 제거와 동일하다.
Fabric MLflow
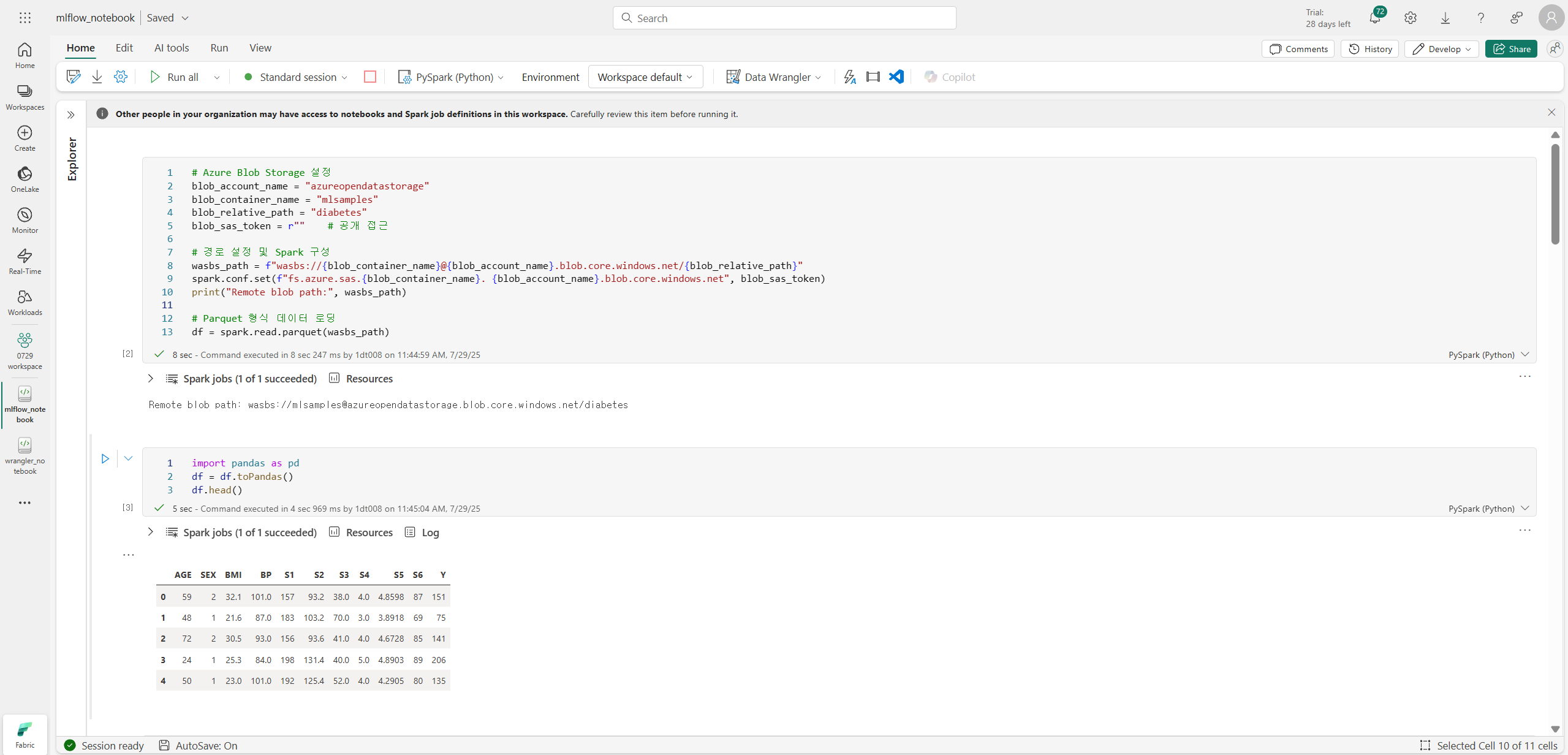
새로운 노트북을 생성하고 데이터를 불러온다.
# Azure Blob Storage 설정
blob_account_name = "azureopendatastorage"
blob_container_name = "mlsamples"
blob_relative_path = "diabetes"
blob_sas_token = r"" # 공개 접근
# 경로 설정 및 Spark 구성
wasbs_path = f"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}"
spark.conf.set(f"fs.azure.sas.{blob_container_name}. {blob_account_name}.blob.core.windows.net", blob_sas_token)
print("Remote blob path:", wasbs_path)
# Parquet 형식 데이터 로딩
df = spark.read.parquet(wasbs_path)
import pandas as pd
df = df.toPandas()사용한 데이터는 위와 같다.
from sklearn.model_selection import train_test_split
X = df[['AGE','SEX','BMI','BP','S1','S2','S3','S4','S5','S6']].values
y = df['Y'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)values로 DaraFrame이 아니라 ndarray로 바꿔 속도를 빠르게 한다.
이후 train set과 test set을 분리한다.
import mlflow
experiment_name = "experiment-diabetes"
mlflow.set_experiment(experiment_name)MLflow에서 관련 있는 실행(Run)들을 그룹화하는 단위를 Experiment라고 한다.
이 코드는 "experiment-diabetes" 라는 이름의 Experiment를 활성화한다.
만약 이 이름의 Experiment가 없다면 새로 생성하고, 있다면 기존의 것을 사용한다.
앞으로 학습할 모델들의 모든 정보는 이 Experiment 안에 기록한다.
from sklearn.linear_model import LinearRegression
with mlflow.start_run():
mlflow.autolog()
model = LinearRegression()
model.fit(X_train, y_train)
mlflow.log_param("estimator", "LinearRegression")
from sklearn.tree import DecisionTreeRegressor
with mlflow.start_run():
mlflow.autolog()
model = DecisionTreeRegressor(max_depth=5)
model.fit(X_train, y_train)
mlflow.log_param("estimator", "DecisionTreeRegressor")with 구문 안에서 실행하는 모든 코드는 하나의 MLflow Run으로 간주하여 기록한다.
autolog로 hyperparameter, metric, 학습한 모델의 artifact까지 자동으로 기록한다.
수동으로 mlflow.log_metric()과 mlflow.log_param()을 여러 번 호출할 필요가 없다.
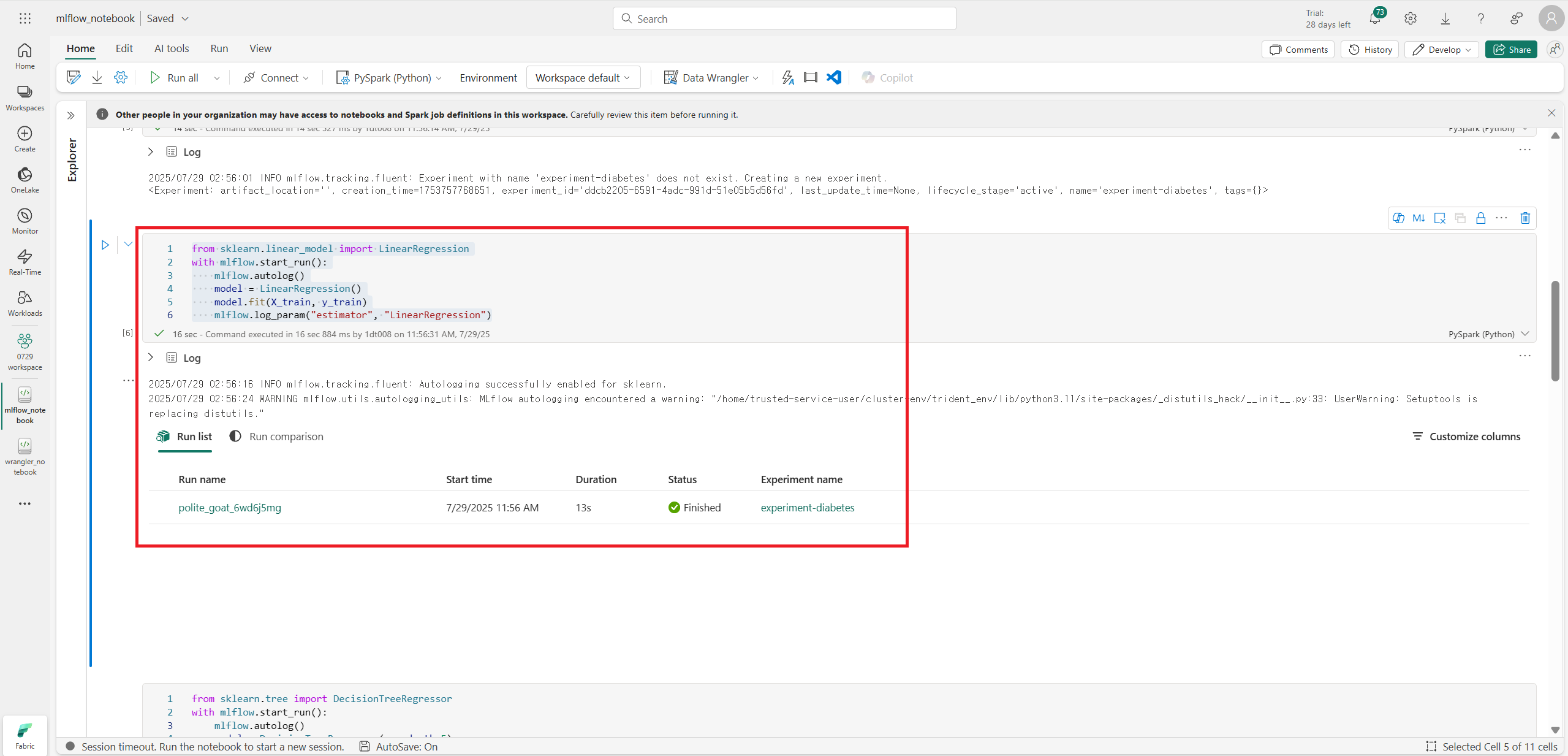
코드를 실행하면 결과는 위와 같다.
experiments = mlflow.search_experiments()
for exp in experiments:
print(exp.name)해당 코드로 간단하게 experiments 목록을 조회할 수 있다.
exp = mlflow.get_experiment_by_name("experiment-diabetes")
print(exp)
mlflow.search_runs(exp.experiment_id)exp.name으로 얻은 experiments의 이름을 get_experiment_by_name의 매개변수로 넘겨준다.
그럼 해당 exp 실험 실행 정보를 조회할 수 있다.

LogisticRegression과 DecisisonTreeRegressor로 실험했기 때문에 2개가 나온다.
각 학습의 start_time, end_time, parms, intercept, coef 등등을 보여준다.
mlflow.search_runs(exp.experiment_id, order_by=["start_time DESC"], max_results=2)위 코드는 start_time 내림차순 기준으로 최대 2개의 결과만을 보여준다.

여기서는 2개만 실행했기 때문에 같은 결과가 나온다.
import matplotlib.pyplot as plt
df_results = mlflow.search_runs(
exp.experiment_id, order_by=["start_time DESC"], max_results=2
)[["metrics.training_r2_score", "params.estimator"]]
fig, ax = plt.subplots()
ax.bar(df_results["params.estimator"], df_results["metrics.training_r2_score"])
ax.set_xlabel("Estimator")
ax.set_ylabel("R2 score")
ax.set_title("R2 score by Estimator")
for i, v in enumerate(df_results["metrics.training_r2_score"]):
ax.text(i, v, str(round(v, 2)), ha='center', va='bottom', fontweight='bold')
plt.show()해당 코드로 R2 계수에 대해 그래프를 그릴 수 있다.
Fabric batch
dd
Fabric ingest
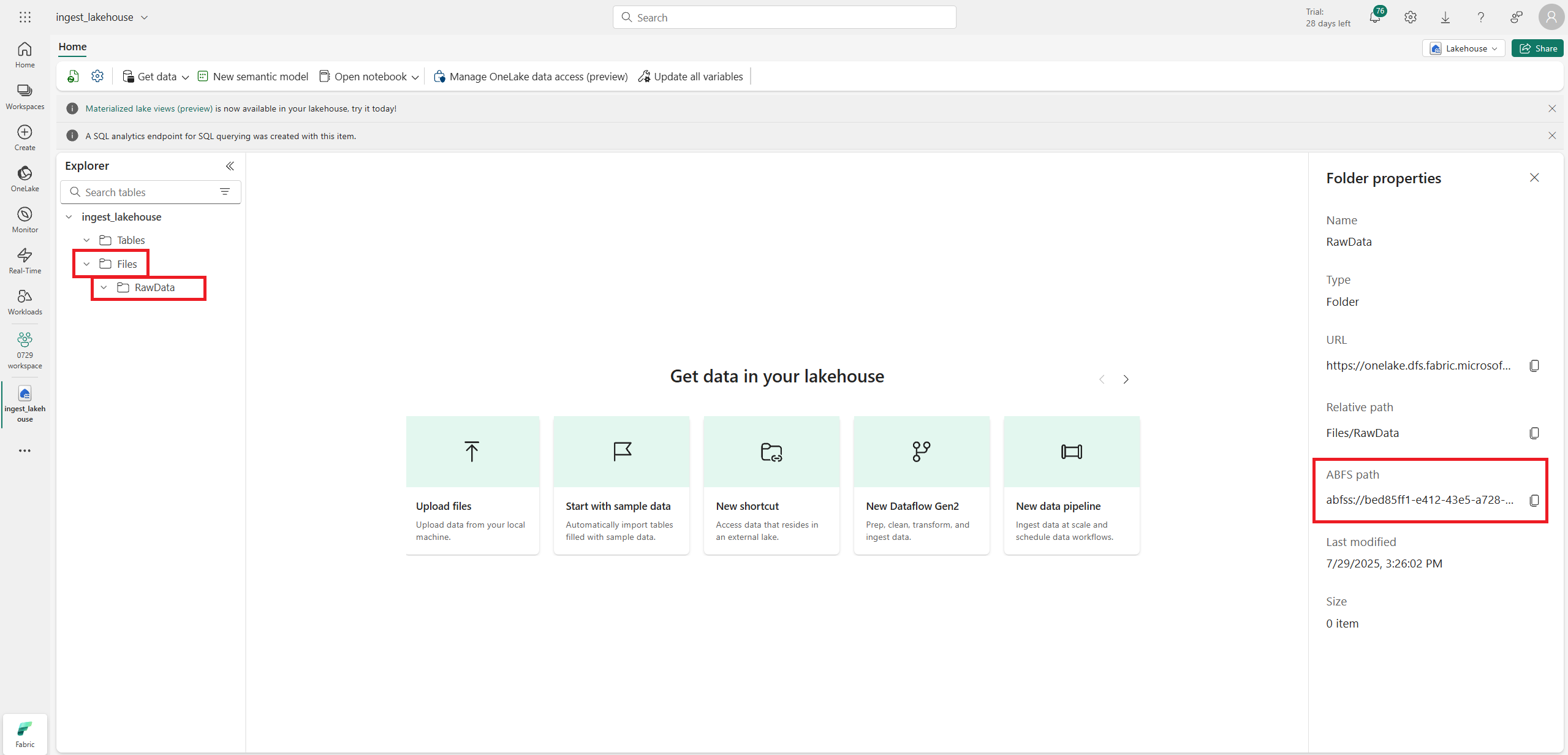
새로운 notebook을 하나 만들고 Files의 subfolder를 만들어 ABFS path를 기록해둔다.
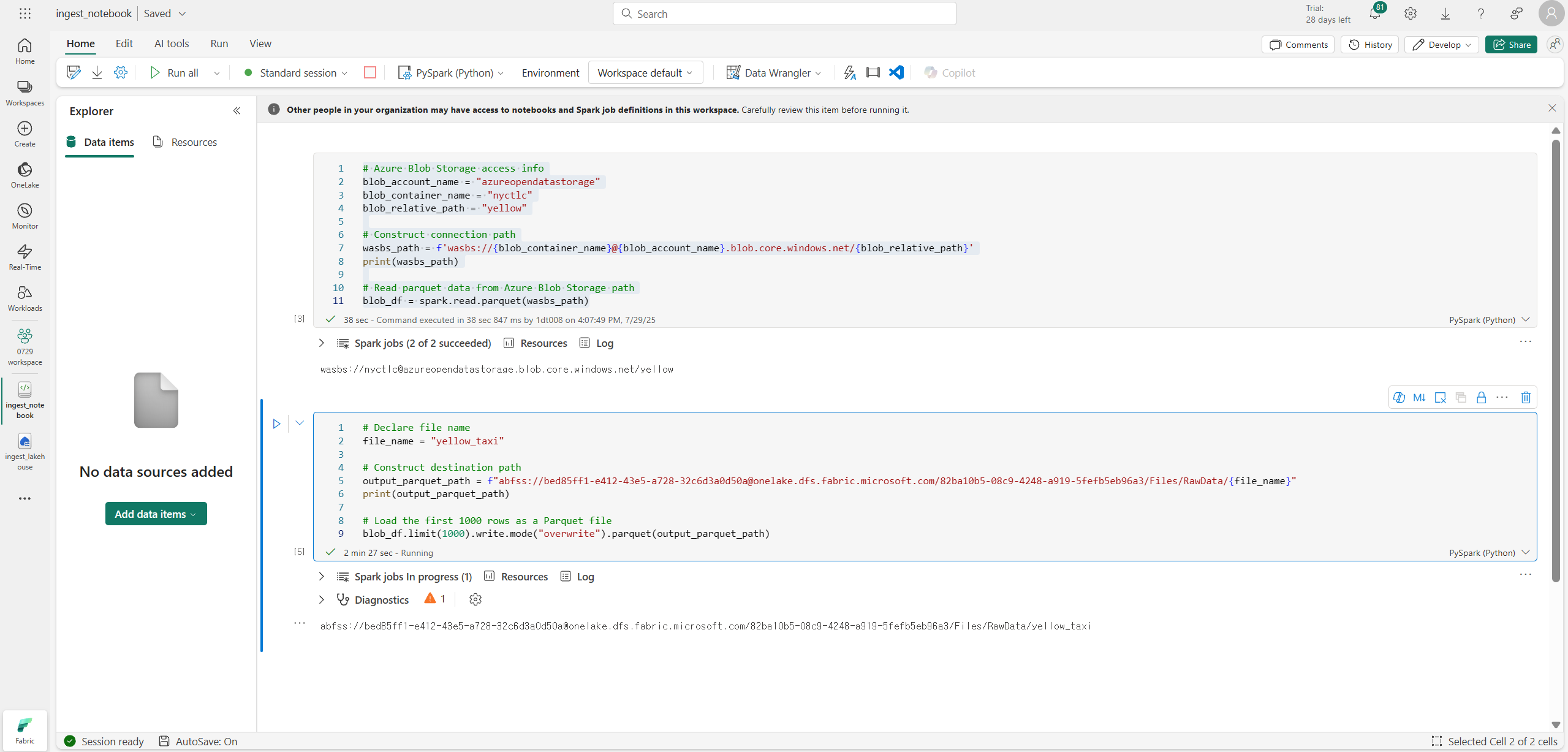
dd
# Declare file name
file_name = "yellow_taxi"
# Construct destination path
output_parquet_path = f"YOUR_ABFS_PATH/Files/RawData/{file_name}"
print(output_parquet_path)
# Load the first 1000 rows as a Parquet file
blob_df.limit(1000).write.mode("overwrite").parquet(output_parquet_path)사용한 코드는 위와 같다.

lakehouse에 yellow_taxi라는 parquet가 들어왔다.

'공부 > Microsoft Data School 1기' 카테고리의 다른 글
| AzureSQLDatabase 구성 및 관리 1 (4) | 2025.07.31 |
|---|---|
| Fabric을 활용한 통합 솔루션 구현 5 (3) | 2025.07.30 |
| Fabric을 활용한 통합 솔루션 구현 3 (1) | 2025.07.28 |
| Fabric을 활용한 통합 솔루션 구현 2 (2) | 2025.07.25 |
| Fabric을 활용한 통합 솔루션 구현 1 (3) | 2025.07.24 |