개요
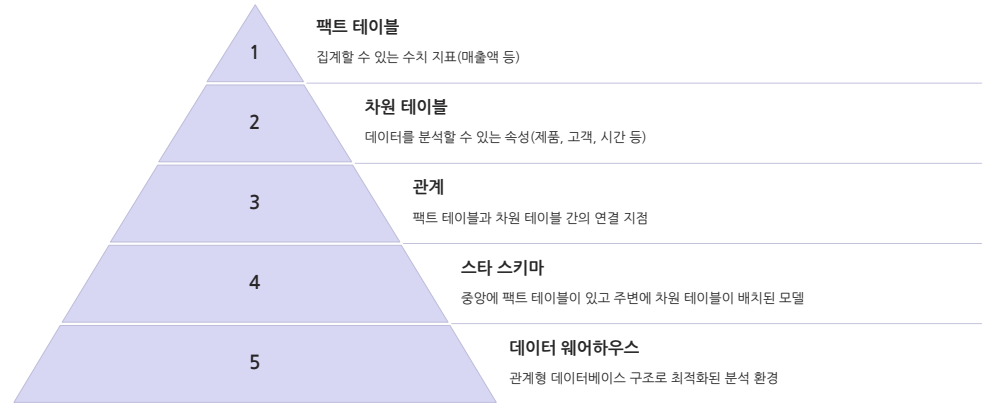
Microsoft Fabric Data Warehouse는 대규모 분석을 위한 관계형 데이터베이스다.
관계형 데이터 웨어하우스는 Fact table과 Dimension table로 구성한다.
이때 독자적인 T-SQL을 사용한다.
Fabric Data Warehouse

데이터 분산과 중복 저장 및 동기화 문제로 인해 warehouse가 나왔다.
Warehouse 실습을 위해 sample warehouse 데이터를 사용한다. sample 리소스를 생성한다.
Sample warehouse 생성을 기다리면 내용이 뜬다.

코드 작성을 위해 warehouse 리소스를 생성한다.

새로운 쿼리창을 열고 테이블을 만든다.
CREATE TABLE dbo.DimProduct
(
ProductKey INTEGER NOT NULL,
ProductAltKey VARCHAR(25) NULL,
ProductName VARCHAR(50) NOT NULL,
Category VARCHAR(50) NULL,
ListPrice DECIMAL(5,2) NULL
);
INSERT INTO dbo.DimProduct
VALUES
(1, 'RING1', 'Bicycle bell', 'Accessories', 5.99),
(2, 'BRITE1', 'Front light', 'Accessories', 15.49),
(3, 'BRITE2', 'Rear light', 'Accessories', 15.49);
GO사용한 쿼리는 위와 같다.
https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/create-dw.txt
이후 위 링크에 있는 SQL 쿼리를 복사 붙여넣기하여 Run한다.
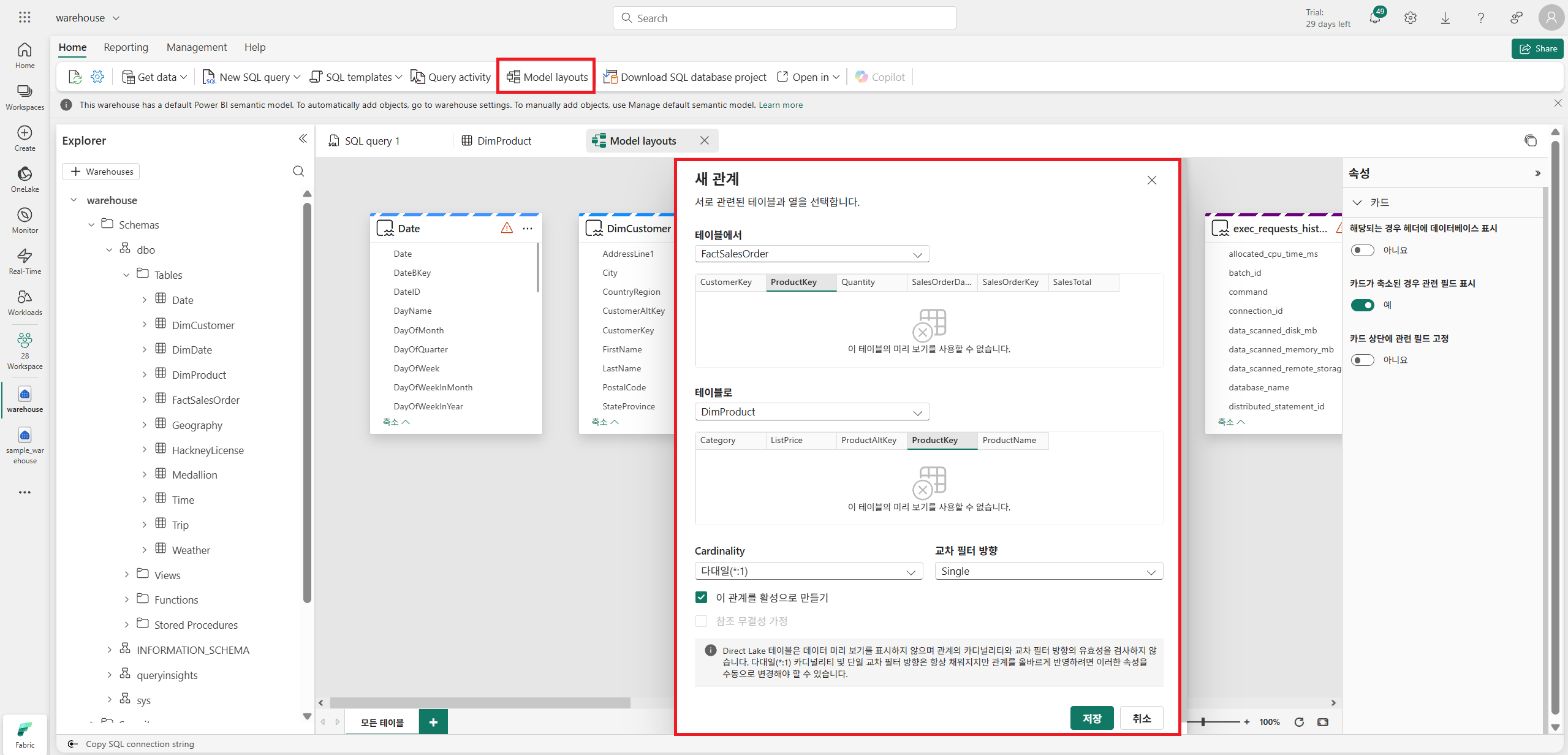
이후 Model Layouts으로 들어가서 테이블 관계를 설정해준다.

FactSalesOrder와 관계있는 DimProduct, DimCustomer, DimDate 테이블의 관계를 모두 이어준다.
-- Query 1: test
SELECT d.[Year] AS CalendarYear,
d.[Month] AS MonthOfYear,
d.MonthName AS MonthName,
SUM(so.SalesTotal) AS SalesRevenue
FROM FactSalesOrder AS so
JOIN DimDate AS d ON so.SalesOrderDateKey = d.DateKey
GROUP BY d.[Year], d.[Month], d.MonthName
ORDER BY CalendarYear, MonthOfYear;
-- Query 2: test
SELECT d.[Year] AS CalendarYear,
d.[Month] AS MonthOfYear,
d.MonthName AS MonthName,
c.CountryRegion AS SalesRegion,
SUM(so.SalesTotal) AS SalesRevenue
FROM FactSalesOrder AS so
JOIN DimDate AS d ON so.SalesOrderDateKey = d.DateKey
JOIN DimCustomer AS c ON so.CustomerKey = c.CustomerKey
GROUP BY d.[Year], d.[Month], d.MonthName, c.CountryRegion
ORDER BY CalendarYear, MonthOfYear, SalesRegion;관계를 설정하면 위와 같은 JOIN 구문을 통해 정보를 조회할 수 있다.
-- Query 3: generate view
CREATE VIEW vSalesByRegion
AS
SELECT d.[Year] AS CalendarYear,
d.[Month] AS MonthOfYear,
d.MonthName AS MonthName,
c.CountryRegion AS SalesRegion,
SUM(so.SalesTotal) AS SalesRevenue
FROM FactSalesOrder AS so
JOIN DimDate AS d ON so.SalesOrderDateKey = d.DateKey
JOIN DimCustomer AS c ON so.CustomerKey = c.CustomerKey
GROUP BY d.[Year], d.[Month], d.MonthName, c.CountryRegion;
-- Query 4: check view
SELECT CalendarYear, MonthName, SalesRegion, SalesRevenue
FROM vSalesByRegion
ORDER BY CalendarYear, MonthOfYear, SalesRegion;Query 2를 매번 조회할 수 없으니 view로 만들어서 사용하는 것도 가능하다.
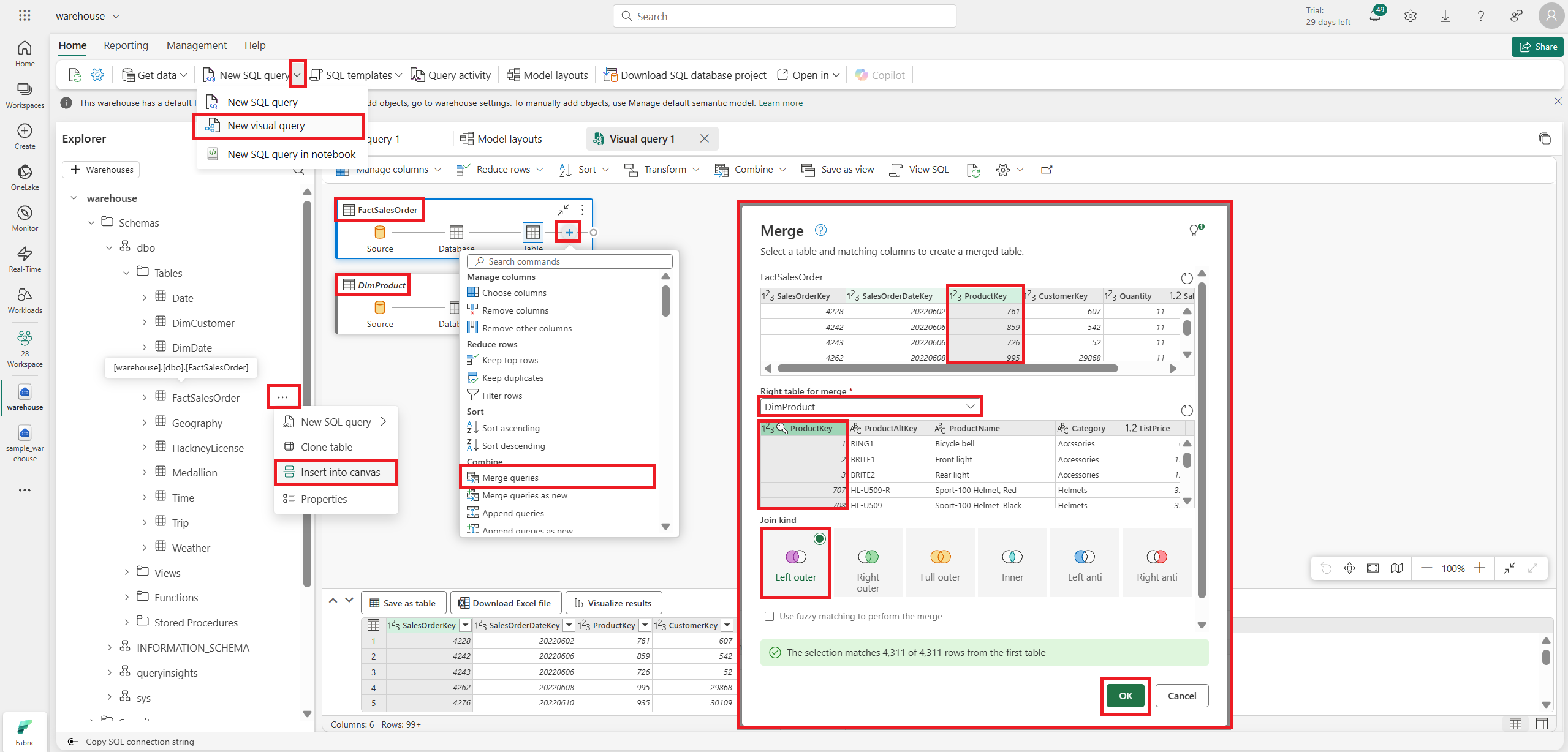
JOIN은 Query가 아니라 Visual Query에서 하는 것도 가능하다.

JOIN하고 나면 위와 같이 'Merged queries' 결과가 나온다.
이후 + 버튼으로 Rename을 하든 Filter를 하든 마음대로 할 수 있다.
Fabric Data Warehouse Load

새로운 lakehouse를 만들고 https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/sales.csv를 가져온다.
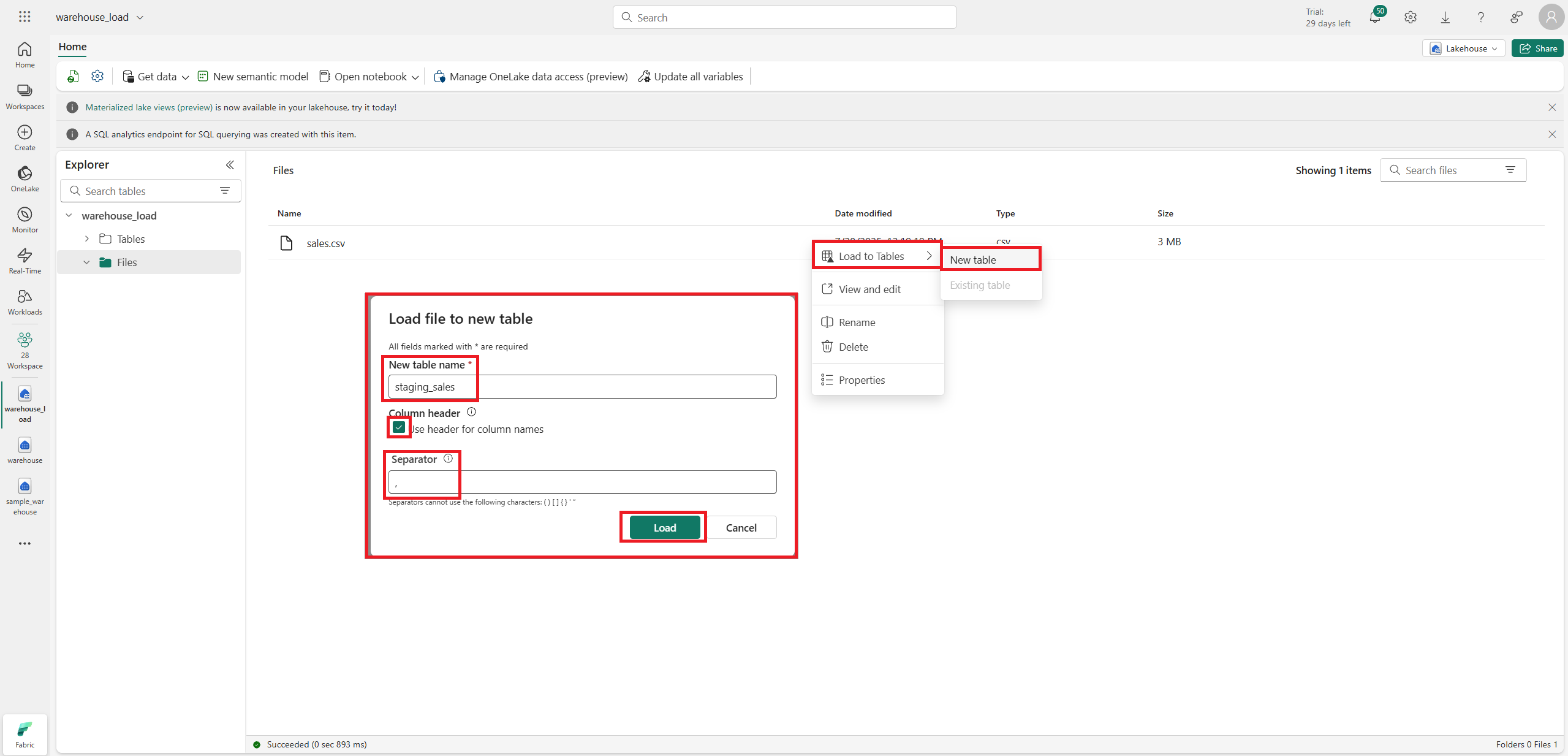
가져온 csv를 기준으로 새로운 table을 만든다.
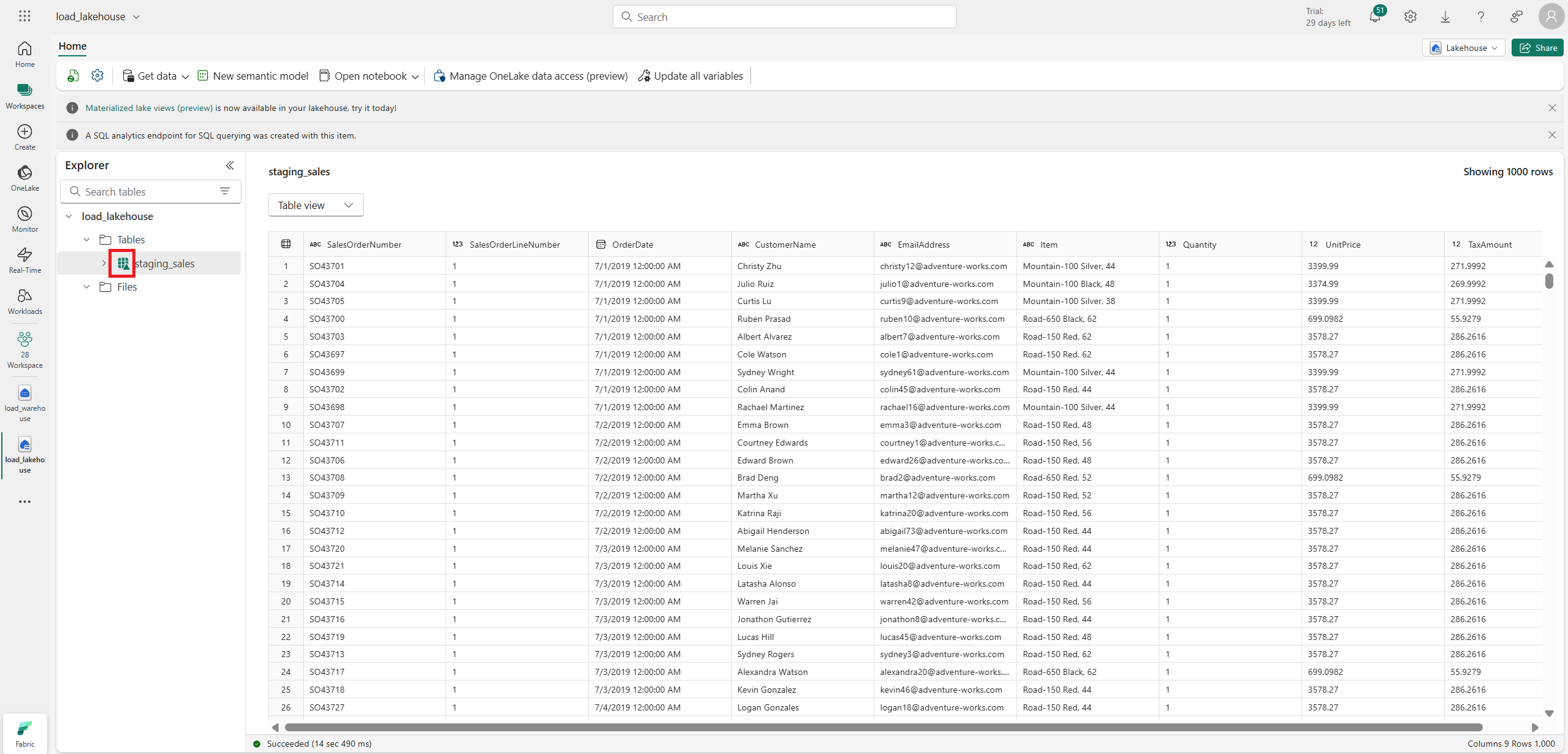
그럼 새롭게 테이블이 생긴 걸 볼 수 있다.
이때 lakehouse에서 생성한 테이블 아이콘을 잘 보면 9개의 칸 옆에 작게 세모 모양이 있다.
이는 그리스어로 delta(Δ)를 뜻하고, 해당 테이블이 delta table이라는 걸 의미한다.

이후 데이터를 실습할 warehouse를 만든다.
SQL Query 입력창을 열어 Fact Table, Dimension Table, View를 만든다.
-- Sales 스키마를 생성합니다. 이미 존재한다면 에러 없이 넘어간다.
CREATE SCHEMA [Sales]
GO
-- Sales.Fact_Sales 테이블이 존재하지 않을 경우에만 생성한다.
IF NOT EXISTS (
SELECT * FROM sys.tables
WHERE name='Fact_Sales' AND SCHEMA_NAME(schema_id)='Sales'
)
CREATE TABLE Sales.Fact_Sales ( -- 판매 내역을 저장하는 팩트 테이블을 생성한다.
CustomerID VARCHAR(255) NOT NULL, -- 고객 ID (Dim_Customer와 연결 가능)
ItemID VARCHAR(255) NOT NULL, -- 아이템 ID (Dim_Item과 연결 가능)
SalesOrderNumber VARCHAR(30), -- 주문 번호
SalesOrderLineNumber INT, -- 주문 내의 라인 번호
OrderDate DATE, -- 주문 날짜
Quantity INT, -- 수량
TaxAmount FLOAT, -- 세금 금액
UnitPrice FLOAT -- 단가
);
-- Sales.Dim_Customer 테이블이 존재하지 않을 경우에만 생성한다.
IF NOT EXISTS (
SELECT * FROM sys.tables
WHERE name='Dim_Customer' AND SCHEMA_NAME(schema_id)='Sales'
)
CREATE TABLE Sales.Dim_Customer ( -- 고객 정보를 저장하는 디멘션 테이블을 생성한다.
CustomerID VARCHAR(255) NOT NULL, -- 고객 ID (기본키)
CustomerName VARCHAR(255) NOT NULL, -- 고객 이름
EmailAddress VARCHAR(255) NOT NULL -- 이메일 주소
);
-- Dim_Customer 테이블에 기본키 제약 조건을 추가한다.
-- NONCLUSTERED 옵션은 인덱스를 비클러스터형으로 생성하며,
-- NOT ENFORCED는 논리적 제약으로만 사용하고 실제 제약 조건은 강제하지 않는다.
ALTER TABLE Sales.Dim_Customer
ADD CONSTRAINT PK_Dim_Customer
PRIMARY KEY NONCLUSTERED (CustomerID) NOT ENFORCED
GO
-- Sales.Dim_Item 테이블이 존재하지 않을 경우에만 생성한다.
IF NOT EXISTS (
SELECT * FROM sys.tables
WHERE name='Dim_Item' AND SCHEMA_NAME(schema_id)='Sales'
)
CREATE TABLE Sales.Dim_Item ( -- 제품 정보를 저장하는 디멘션 테이블을 생성한다.
ItemID VARCHAR(255) NOT NULL, -- 아이템 ID (기본키)
ItemName VARCHAR(255) NOT NULL -- 아이템 이름
);
-- Dim_Item 테이블에 기본키 제약 조건을 추가한다.
-- 역시 논리적으로만 정의하고 실제 강제하지 않는다.
ALTER TABLE Sales.Dim_Item
ADD CONSTRAINT PK_Dim_Item
PRIMARY KEY NONCLUSTERED (ItemID) NOT ENFORCED
GO위와 같은 쿼리를 사용한다. 쿼리에 대한 설명은 다음과 같다.
ㆍ CREATE SCHEMA [Sales] Sales : Sales라는 이름의 새 스키마를 만들어 관련 테이블들을 논리적으로 그룹화한다.
ㆍ IF NOT EXISTS (...) CREATE TABLE ... : 테이블이 아직 존재하지 않을 경우에만 생성하도록 한다.
ㆍ Sales.Fact_Sales : 숫자 측정값(수량, 단가 등)을 담는 사실(Fact) 테이블을 생성한다.
ㆍ Sales.Dim_Customer , Sales.Dim_Item : 분석의 기준이 되는 정보를 담는 차원(Dimension) 테이블들을 생성한다.
└ 이때 정보는 속성 정보로 고객 이름, 아이템 이름 등을 포함한다.
ㆍ ALTER TABLE ... ADD CONSTRAINT ... NOT ENFORCED : 기본 키(Primary Key) 제약 조건을 추가하지만, NOT ENFORCED 옵션을 사용하여 데이터 로드 시 제약 조건 검사를 강제하지 않습니다. 이는 데이터 웨어하우스 환경에서 대량 데이터 로드 성능 향상을 위해 흔히 사용되는 기법이다.

쿼리를 실행하면 정상적으로 테이블이 생긴다.
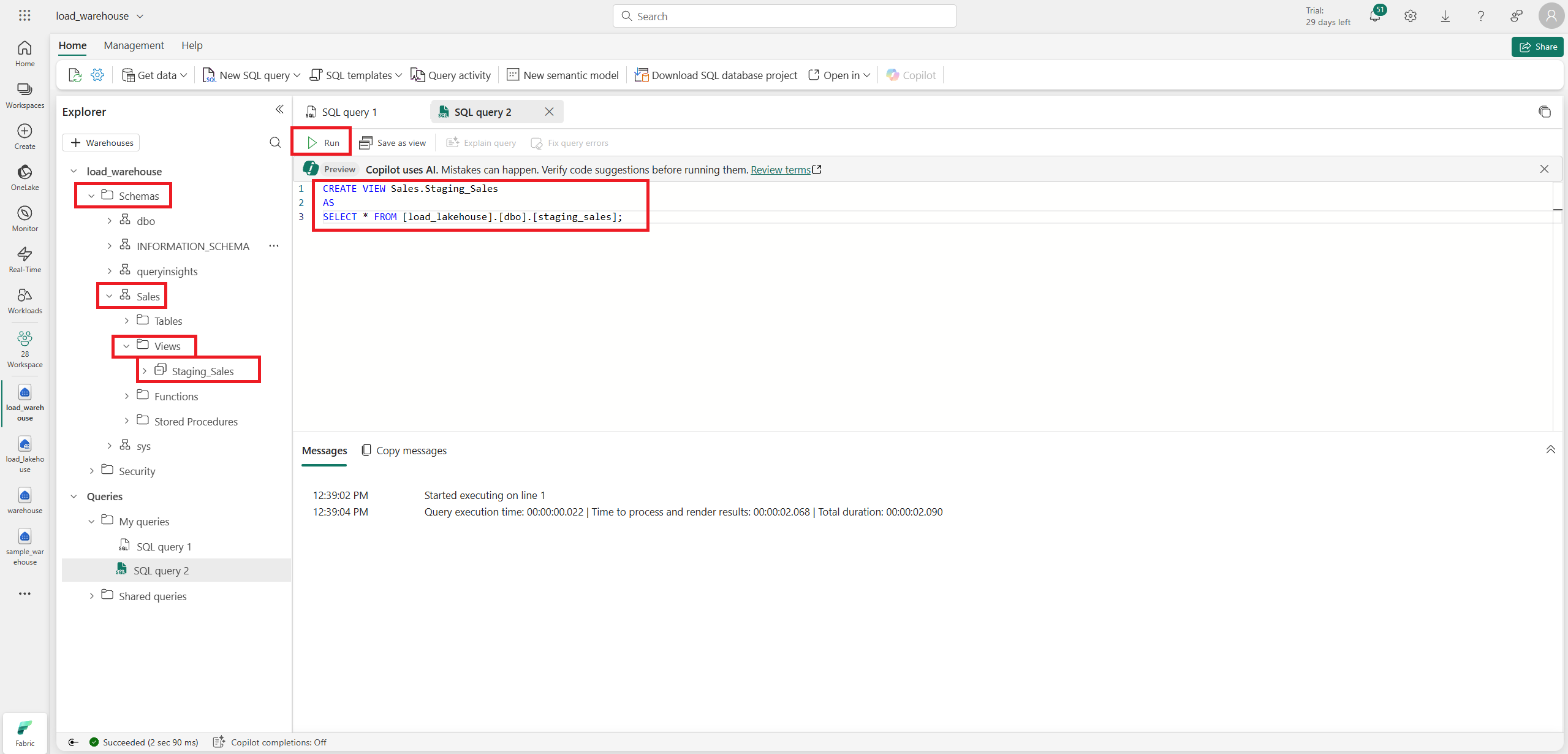
이후 View를 생성한다.
CREATE VIEW Sales.Staging_Sales
AS
SELECT * FROM [your-lakehouse-name].[dbo].[staging_sales];사용한 쿼리는 위와 같다.
CREATE OR ALTER PROCEDURE Sales.LoadDataFromStaging (@OrderYear INT)
AS
BEGIN
-- Load data into the Customer dimension table
INSERT INTO Sales.Dim_Customer (CustomerID, CustomerName, EmailAddress)
SELECT DISTINCT CustomerName, CustomerName, EmailAddress
FROM [Sales].[Staging_Sales]
WHERE YEAR(OrderDate) = @OrderYear
AND NOT EXISTS (
SELECT 1
FROM Sales.Dim_Customer
WHERE Sales.Dim_Customer.CustomerName = Sales.Staging_Sales.CustomerName
AND Sales.Dim_Customer.EmailAddress = Sales.Staging_Sales.EmailAddress
);
-- Load data into the Item dimension table
INSERT INTO Sales.Dim_Item (ItemID, ItemName)
SELECT DISTINCT Item, Item
FROM [Sales].[Staging_Sales]
WHERE YEAR(OrderDate) = @OrderYear
AND NOT EXISTS (
SELECT 1
FROM Sales.Dim_Item
WHERE Sales.Dim_Item.ItemName = Sales.Staging_Sales.Item
);
-- Load data into the Sales fact table
INSERT INTO Sales.Fact_Sales
(CustomerID, ItemID, SalesOrderNumber, SalesOrderLineNumber, OrderDate, Quantity, TaxAmount, UnitPrice)
SELECT
CustomerName,
Item,
SalesOrderNumber,
CAST(SalesOrderLineNumber AS INT),
CAST(OrderDate AS DATE),
CAST(Quantity AS INT),
CAST(TaxAmount AS FLOAT),
CAST(UnitPrice AS FLOAT)
FROM [Sales].[Staging_Sales]
WHERE YEAR(OrderDate) = @OrderYear;
END프로시저를 만들어 데이터에 접근한다.
EXEC Sales.LoadDataFromStaging 2021작성한 프로시저는 위와 같은 코드로 접근할 수 있다.
-- 2021년 총 판매액 기준 상위 고객
SELECT c.CustomerName, SUM(s.UnitPrice * s.Quantity) AS TotalSales
FROM Sales.Fact_Sales s
JOIN Sales.Dim_Customer c ON s.CustomerID = c.CustomerID
WHERE YEAR(s.OrderDate) = 2021
GROUP BY c.CustomerName
ORDER BY TotalSales DESC;
-- 2021년 총 판매액 기준 상위 아이템
SELECT i.ItemName, SUM(s.UnitPrice * s.Quantity) AS TotalSales
FROM Sales.Fact_Sales s
JOIN Sales.Dim_Item i
ON s.ItemID = i.ItemID
WHERE YEAR(s.OrderDate) = 2021
GROUP BY i.ItemName
ORDER BY TotalSales DESC;
-- CTE(Command Table Expression)로 동적 카테고리별 상위 고객 탐색
WITH CategorizedSales AS (
SELECT
CASE
WHEN i.ItemName LIKE '%Helmet%' THEN 'Helmet'
WHEN i.ItemName LIKE '%Bike%' THEN 'Bike'
WHEN i.ItemName LIKE '%Gloves%' THEN 'Gloves'
ELSE 'Other'
END AS Category,
c.CustomerName,
s.UnitPrice * s.Quantity AS Sales
FROM Sales.Fact_Sales s
JOIN Sales.Dim_Customer c
ON s.CustomerID = c.CustomerID
JOIN Sales.Dim_Item i
ON s.ItemID = i.ItemID
WHERE YEAR(s.OrderDate) = 2021
),
RankedSales AS (
SELECT
Category,
CustomerName,
SUM(Sales) AS TotalSales,
ROW_NUMBER() OVER (PARTITION BY Category ORDER BY SUM(Sales) DESC) AS SalesRank
FROM CategorizedSales
WHERE Category IN ('Helmet', 'Bike', 'Gloves')
GROUP BY Category, CustomerName
)
SELECT Category, CustomerName, TotalSales FROM RankedSales
WHERE SalesRank = 1 ORDER BY TotalSales DESC;만든 프로시저를 기준으로 다양한 분석을 진행할 수 있다.
Fabric Data Science

Modeling이나 feature engineering 같은 DE나 DS 같은 작업이 가능하다.
# Azure storage access info for open dataset diabetes
blob_account_name = "azureopendatastorage"
blob_container_name = "mlsamples"
blob_relative_path = "diabetes"
blob_sas_token = r"" # Blank since container is Anonymous access
# Set Spark config to access blob storage
wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token)
print("Remote blob path: " + wasbs_path)
# Spark read parquet, note that it won't load any data yet by now
df = spark.read.parquet(wasbs_path)사용할 데이터 세트는 Azure Open Datasets의 당뇨병 데이터다.
df = df.toPandas()
df.head()해당 코드로 pandas의 데이터프레임 객체로 바꾸는 것이 가능하다.
이후에는 늘 하던대로의 pd 기반 파이썬 코드로 진행하면 된다.
'공부 > Microsoft Data School 1기' 카테고리의 다른 글
| Fabric을 활용한 통합 솔루션 구현 5 (3) | 2025.07.30 |
|---|---|
| Fabric을 활용한 통합 솔루션 구현 4 (3) | 2025.07.29 |
| Fabric을 활용한 통합 솔루션 구현 2 (2) | 2025.07.25 |
| Fabric을 활용한 통합 솔루션 구현 1 (3) | 2025.07.24 |
| 2차 팀 프로젝트 기간 完 (0) | 2025.07.18 |