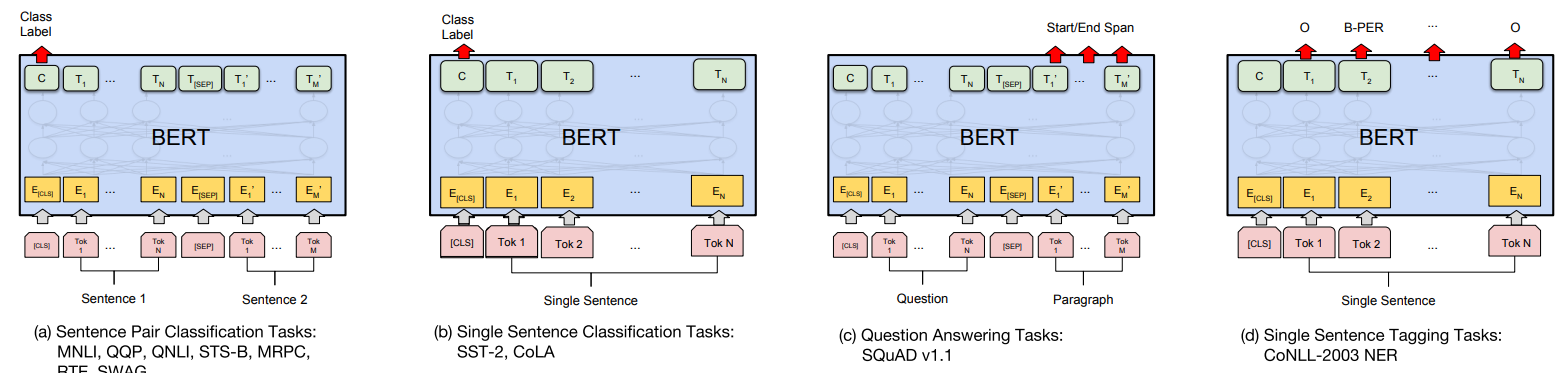
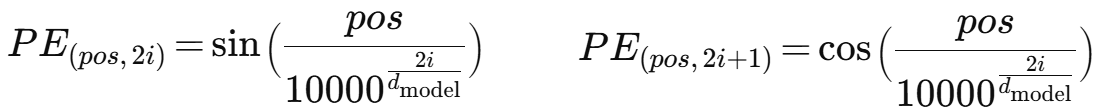데이터 기본 개념
| 정량 데이터(Quantitative Data) | 정성 데이터(Qualitative Data) | |
| 유형 | 정형 데이터, 반정형 데이터 | 비정형 데이터 |
| 특징 | 주로 수치로 이루어진 규칙을 따르는 데이터, 객관적 | 객체 하나하나가 함축적 의미를 내포, 주관적 |
| 형태 | 수치, 스프레드시트, 데이터베이스 | 문자열, 로그, 이미지 등 |
| 위치 | DBMS나 로컬 시스템 등의 내부 | 웹사이트나 플랫폼 등의 외부 |
| 통계, 분석 | 용이 | 어려움 |
정량 데이터와 정성 데이터 비교 표
| 정형 데이터 (Structured Data) |
반정형 데이터 (Semi-Structured Data) |
비정형 데이터 (Unstructured Data |
|
| 개념 | 고정 포맷(스키마)이 있는 데이터 행과 열 구조이며 검색, 분류가 용이 RDBMS나 스프레드시트에서 다룸 |
구조가 있지만 정형처럼 엄격하지 않음 태그, 키-값 등의 구조를 가짐 데이터 간 관계가 자유롭고 유동적 |
명확한 구조나 스키마가 없는 데이터 내용이 다양하고 예측이 불가능 분석을 위한 추가 처리가 필요 |
| 예시 | 엑셀에 저장한 고객명, 전화번호, 주소 은행 거래 내역 테이블 병원 환자 기록 데이터베이스 등 |
JSON, XML, 이메일, 로그 파일 등 | 텍스트 문서(보고서, 소설 등) 이미지 파일, 동영상, 음성 파일 SNS 게시물 |
그 밖에도 정형, 반정형, 비정형의 구분이 있다.
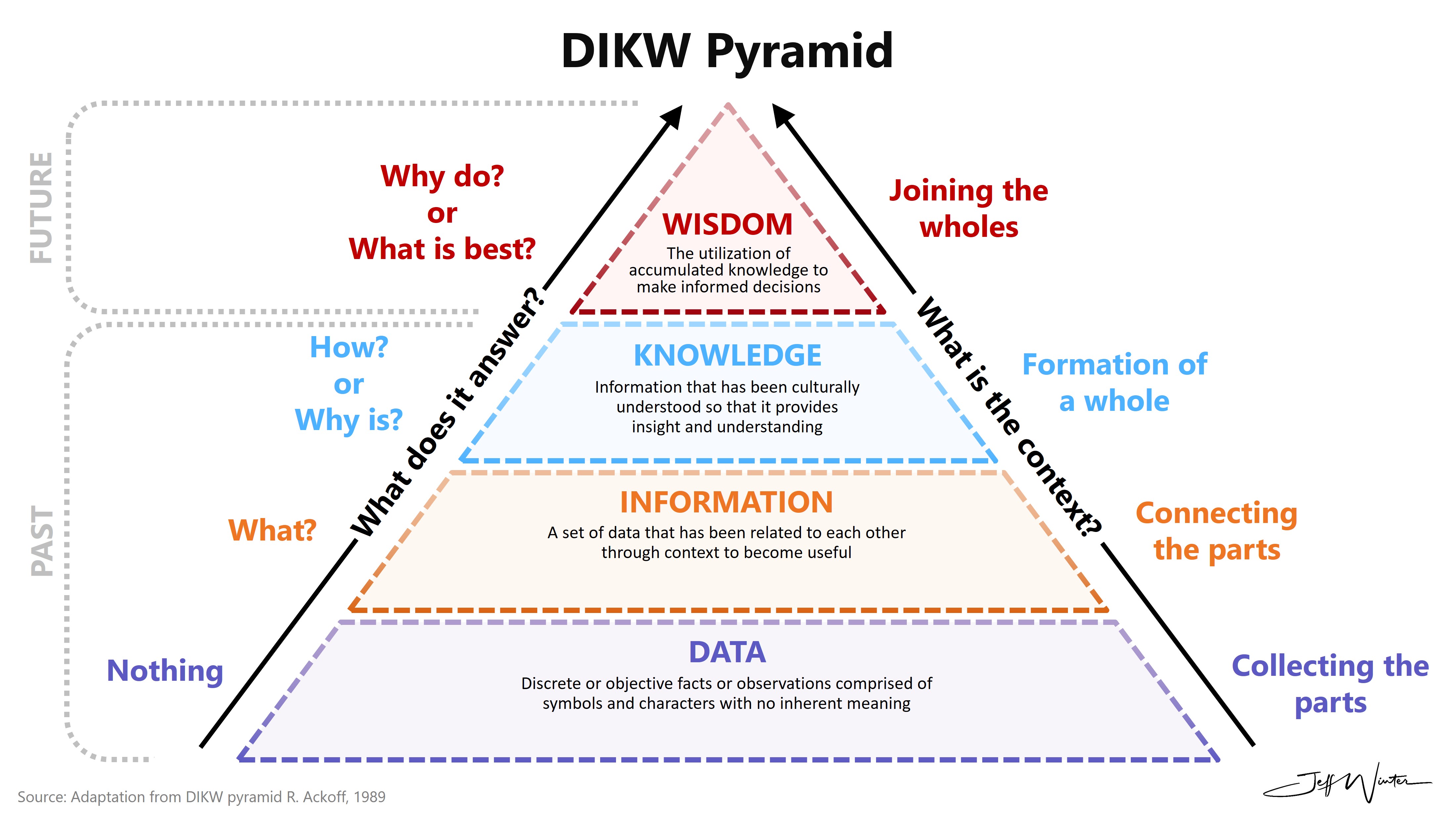
DIKW는 Data Informationo Knowledge Wisdom의 약자이다.
DIKW 피라미드는 데이터를 점차 가공하고 해석하면서 더 높은 수준의 가치를 갖게 되는 과정을 계층 구조로 표현한 것이다.
Data는 의미 없이 존재하는 객관적 사실, 숫자, 관찰 결과 등을 말한다.
예시: 22도, 서울, 우천, 습기, 50%
Information은 데이터를 맥락에 맞게 정리하거나 해석하거나, 혹은 의미를 부여한 상태다.
예시: 서울의 현재 기온은 22도이며 우천 확률은 50%이다.
Knowledge는 여러 정보를 연결하여 비교함으로써 이를 이해하거나 응용에 사용하는 것이다.
예시: 서울에서 50% 우천 확률이 있으니 우산을 준비해야 한다.
Wisdom은 지식을 바탕으로 유용한 판단이나 결정을 내리는 행동을 말한다.
예시: 금일 서울에 갈 일이 있다면 작은 우산을 챙기고, 대중교통을 이용한다.
데이터베이스
| 개념 | 종류 | 설명 | |
| 데이터 조작어 Data ManiPulation |
데이터를 추가, 수정, 삭제, 조회할 때 사용하는 SQL |
SELECT | 데이터 조회 |
| INSERT | 데이터 삽입 | ||
| UPDATE | 데이터 수정 | ||
| DELETE | 데이터 삭제 | ||
| 데이터 정의 Data Definition |
테이블이나 DB의 구조를 정의하거나 변경하는 SQL |
CREATE | 테이블, 인덱스, 뷰 생성 |
| ALTER | 테이블 구조 생성 | ||
| DROP | 테이블, 인덱스, 뷰 삭제 | ||
| TRUNCATE | 테이블 데이터 전체 삭제 (구조는 유지) | ||
| 데이터 제어어 Data Control |
데이터에 대한 접근 권한을 제어하는 SQL |
GRANT | 권한을 부여 |
| REVOKE | 권한을 회수 | ||
| 트랜잭션 제어어 Transaction Control |
트랜잭션(하나의 작업 단위)을 관리하는 SQL |
COMMIT | 트랜잭션 저장 |
| ROLLBACK | 트랜잭션 취소 | ||
| SABEPOINT | 롤백을 위한 저장 시점 설 |
기본 SQL 구문과 종류
PostgreSQL에서 사용하는 데이터 타입은 공식 docs를 참고하자.
환경 설정

PostgreSQL 설치

DBeaver 설치 후 PostgreSQL 연동

DBeaver에서 수동으로 table 생성

테이블 생성 이후 GUI 기반으로 수동 column 생성
ALTER TABLE public.user_info ADD user_id char varying(20) NOT NULL;
COMMENT ON COLUMN public.user_info.user_id IS 'This is necessary data';
ALTER TABLE public.user_info ADD CONSTRAINT user_info_pk PRIMARY KEY (user_id);
ALTER TABLE public.user_info ADD user_name char varying(10) NOT NULL;
COMMENT ON COLUMN public.user_info.user_name IS 'user name, not nickname';
ALTER TABLE public.user_info ADD jumin_no character(13) NOT NULL;
COMMENT ON COLUMN public.user_info.jumin_no IS 'personal number, exactly 13 digits';
ALTER TABLE public.user_info ADD tel_co character(2) NOT NULL;
COMMENT ON COLUMN public.user_info.tel_co IS 'telephone company';
ALTER TABLE public.user_info ADD tel_no character(11) NOT NULL;
COMMENT ON COLUMN public.user_info.tel_no IS 'telephone number';GUI에서 작성한 내용을 자동으로 DBeaver가 자동으로 SQL 구문을 짜준다.
이거는 SQL을 몰라도 사용할 수 있다는 점과 공부하려는 측면에서 생각보다 유용해보인다.

ㅇㅇ

데이터 삽입
General에서 Format과 Encoding 맞추기
Options에서 Header 옵션 켜기
Columns에서 Columns to Export 확인하기

제약 조건 추가
DBeaver 기준)
1. Databases > postgres > Schemas > public > Tables > user_info에서 테이블 우클릭 후
Create > Constraints로 제약 조건 생성하기
2. 테이블까지 들어와서 상단의 Properties에서 위 사진처럼 컬럼명 우클릭 후
New Constraint from Selection으로 제약 조건 생성하기
pgAdmin 기준)
Servers > PostgreSQL > Databases > postgres > Schemas > public > Tables에서 원하는 테이블을 우클릭 후
Properties > Constraints > Check로 제약 조건 생성하기

쿼리 실행하기
pgAdmin 기준)
상단의 Tools > Query Tool을 클릭 후 쿼리 입력하기
00
00
'공부 > Microsoft Data School 1기' 카테고리의 다른 글
| PowerBI를 활용한 데이터 시각화 1 (0) | 2025.04.25 |
|---|---|
| 파이썬으로 데이터 수집, 형태 및 분석 6 (1) | 2025.04.22 |
| 파이썬으로 데이터 수집, 형태 및 분석 5 (0) | 2025.04.18 |
| 파이썬으로 데이터 수집, 형태 및 분석 4 (0) | 2025.04.17 |
| 파이썬으로 데이터 수집, 형태 및 분석 3 (0) | 2025.04.16 |