
Block Based Model

Multi Head Attention을 핵심 모듈로 가져가고, 거기에 여러 후처리를 엮어 커다란 하나의 모듈을 만든다.
그렇게 생긴 커다란 모듈 집합을 하나의 단위인 Block으로 간주한다.
입력 후 처리하는 최초의 Block 내부 구조는 위와 같다.
입력이 들어오면 Q, K, V로 나뉘어져 Multi Head Attention으로 계산한다.
이후 Add와 Normalization 연산을 수행한다.
그렇게 나온 결과를 Feed Forward를 수행한 후 다시 Add와 Normalization 연산을 수행한다.
최종 나온 결과를 모델 구조에 따라서, 다음 Encoder 혹은 Decoder로 전달한다.
Residual Connection
위 Block에서 Add에 해당하는 연산으로 Residual Connection(잔차 연결)이라고 부른다.
Computer Vision 분야, 특히 ResNet에서 처음 제안된 구조이다.
깊은 레이어의 NN을 만들 때 발생하는 gradient vanishing 문제를 해결하고 안정적으로 학습할 수 있다.
기존 DL layer 구조가 y = F(x)라면, Add 구조는 y = F(x) + x이다.
간단하게 설명하면 입력 x를 그대로 출력에 더해주는 방식이다.
x를 그대로 유지하기 때문에 최소한의 Identity Function(항등 함수)를 보장하기에 안정적인 학습이 가능하다.
└ 학습이 안정적이라는 말은, 학습 과정의 gradient의 손실이 없고, backpropagation에서 loss 전달이 잘 된다는 뜻이다.
└ 이는 layer를 수십 수백 층을 쌓아도 발휘되며, 성능이 대폭 향상한다.
Layer Normalization
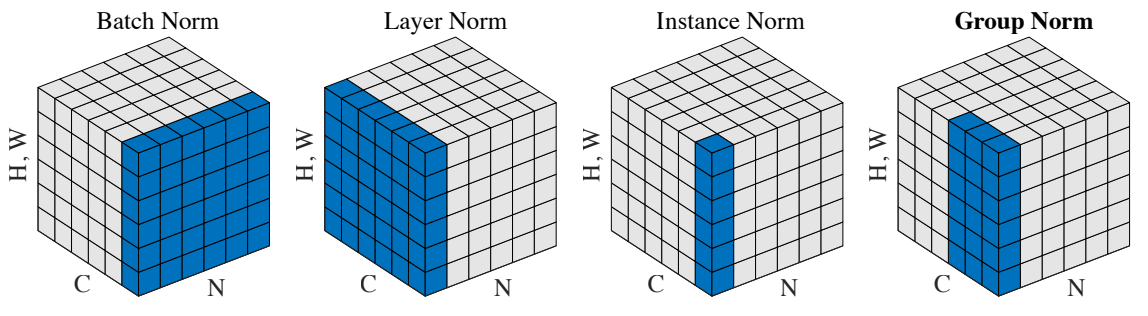
NN(Neural Network) 혹은 DL(Deep Learning)에서 사용하는 다양한 Normalization 기법이 존재한다.
주어진 다수의 샘플에 대해 평균을 0, 분산을 1로 만드는 선형 변환이다.
그 후 사용자가 원하는 방향으로 평균과 분산 값들을 조정하는 식으로 사용한다.

평균을 계산하는 수식이다.
모든 관측값(각 데이터)를 더한 뒤, 개수만큼 나눠주면 된다.
관측값(각 데이터)에서 평균을 빼주면, 전체 평균은 0이 된다.

표준편차를 계산하는 수식이다.
표준편차는 분산의 제곱근이므로, 우선 분산을 구하면 된다.
분산은 관측값(각 데이터)에서 평균을 뺸 값을 제곱하고, 다시 평균을 구하면 된다.
관측값(각 데이터)을 표준편차로 나누면, 전체 분산이 1이 된다.

평균을 0, 분산을 1로 만든 뒤 사용자가 원하는 방향으로 조정하는 수식, Affine Transformation(아핀 변환)이다.
Linear Transformation(선형 변환)과 Translation(평행 이동)을 합친 연산이다.
수식에서 g_i와 b_i는 학습 가능한 parameter에 해당한다.
간단하게 예를 들어 y = Wx + b라는 식이 있다고 하자.
평균을 0 분산을 1로 만든 vector V가 [v1, v2, v3]로 있다고 하면,
V를 y = Wx + b에 넣을 때, 평균은 b 분산은 W^2으로 바뀐다.
그리고 W(g_i)와 b(b_i)는 각각 gradient descent에 의해 최적화하는 parameter에 해당한다.
Batch Normalization 같은 경우 이러한 수식에 기반해서 Normalization한다.

Layer Normalization은 마지막에 Affine Transformation을 row 단위로 수행한다는 차이점이 있다.
Batch Normalization은 col(혹은 feature) 단위로 Affine Transformation을 수행한다는 말과 같다.
Normalization 방법마다 아주 세세하게 다르지만, 결국 최종 목적은 학습을 안정화하고 성능을 향상하는 것이다.
'공부 > BoostCourse 자연어 처리' 카테고리의 다른 글
| 18. NLP Trends - GPT 1 (0) | 2025.03.27 |
|---|---|
| 17. Transformer - Positional Encoding (1) | 2025.03.26 |
| 15. Transformer - Multi Head Attention (0) | 2025.03.24 |
| 14. Transformer - Scaled Dot Product Attention (0) | 2025.03.21 |
| 13. Transformer - Long Term Dependency (0) | 2025.03.20 |