Azure SQL Server 기반 DB 유지 관리 개요

Microsoft 지능형 데이터 플랫폼
구성은 온프레미스-하이브리드-클라우드의 단계로 이루어져있다.
└ on-premise: 기존 SQL Server 인프라를 통한 데이터 관리 및 처리
└ 하이브리드: on-premise와 클라우드 환경 간의 원활한 데이터 통합
└ 클라우드: 온전한 클라우드 네이티브 데이터 서비스
Azure DB 관리자는 클라우드 환경에서 DB 설계, 구현, 유지 관리를 담당한다.
관리자는 다음과 같은 역할 책임을 가진다.
ㆍ DB 아키텍쳐 설계 및 최적화
ㆍ 성능 모니터링 및 튜닝
ㆍ 보안 및 규정 준수 관리
ㆍ 고가용성 및 재해 복구 구현
ㆍ on-premise와 클라우드 환경의 통합 관리
ㆍ 데이터 접근 권한 제어

Azure SQL Server 기반 제품들이다.
| Migration 시나리오 | SQL Server on VM | Azure SQL Database | SQL Managed Instance |
| on-premise 직접 이전 | Lift and Shift로 가장 쉬움 | 애플리케이션 변경 필요 | 최소한의 변경만 필요 |
| 제어 수준 | 높음(OS, SQL 완전 제어) | 낮음(PaaS) | 중간(Instance 제어) |
| 관리 부담 | 높음 | 낮음 | 낮음 |
| 확장성 | 수동 확장 | 자동 확장 | 수동 확장 |
| 비용 모델 | VM 비용 + license | 사용량 기반 | Instance 기반 |
Azure SQL Server 기반 제품들의 migration 시나리오에 따른 비교 표다.

SQL Server on VM의 주요 기능들이다.
배포는 '리소스 계획 > Azure portal에서 VM 생성 > 네트워크 구성 > 스토리지 최적화 > SQL Server' 구성 순이다.
그밖의 특징들은 다음과 같다.
ㆍ 완전한 SQL Server 환경 제공
ㆍ 기존 on-premise 애플리케이션의 쉬운 migration
ㆍ OS 및 DB 엔진에 대한 완전 제어
ㆍ License 이동성 지원 (Azure 하이브리드 혜택)
ㆍ 특수 워크로드를 위한 맞춤형 구성 가능

주요 사항들은 다음과 같다.

Azure SQL Database의 주요 기능들이다.
그 외 핵심 기능으로 자동 백업, 자동 패치, 성능 모니터링 등이 있다.

Azure SQL Database의 배포 오션 비교다.

Azure SQL Database의 개발 패턴이다.
| 비교 항목 | DTU 모델 | vCore 모델 |
| 리소스 측정 | 추상화 단위(DTU) | CPU, 메모리, IO 직접 제어 |
| 적합 워크로드 | 예측 가능한 소규모 워크로드 | 복잡하고 가변적인 워크로드 |
| 하이브리드 혜택 | 지원 X | 지원 O |
| serverless 옵션 | 지원 X | 지원 O |
Azure SQL Database의 운영 효율화 전략이다.

Azure SQL Managed Instance의 아키텍처 및 배포 모델에 대한 설명이다.
주요 기능으로는 자동 백업, 자동 패치, 엔터프라이즈 기능 등이 있다.

Azure SQL Managed Instance의 Migration 옵션에 대한 설명이다.

Azure SQL Managed Instance의 주요 사항들은 다음과 같다.
Microsoft SQL Server 인덱스 관리 개요

Index는 DB 테이블의 검색 속도 향상하기 위해 설계한 특별한 자료구조다.
Index는 DB 성능의 핵심 요소로, 대량 데이터를 처리하는 환경에서는 필수 요소다.
적절한 index를 설정하지 않으면 시스템이 모든 데이터를 순차적으로 검색해야 하기에 성능이 크게 하락한다.
이러한 index는 테이블의 특정 열을 기반으로 생성한다.

SQL Server에서 index가 있는 경우 동작 과정이다.

SQL Server 대부분의 index는 B+ tree 구조로 동작한다.
B+ tree 구조가 신이어도 index는 생성하고 방치해서는 안 되는 하나의 객체다.
시간이 지남에 따라 데이터 삽입, 수정, 변경, 삭제가 발생하며 index가 조각화되며 성능은 떨어진다.
이는 디스크 공간을 낭비하며, 검색 속도(전체 시스템의 응답 시간 지연)도 저하하는 요인이다.
특히 대용량 DB에서는 index 유지 보수가 무척 중요해진다.
리소스 모니터링
Azure SQL에서 작업 리소스 모니터링 및 최적화 - Training | Microsoft Learn
Azure SQL에서 작업 리소스 모니터링 및 최적화 - Training
Azure SQL에서 작업 리소스 모니터링 및 최적화
learn.microsoft.com
참고사항

SQL Server 만들기
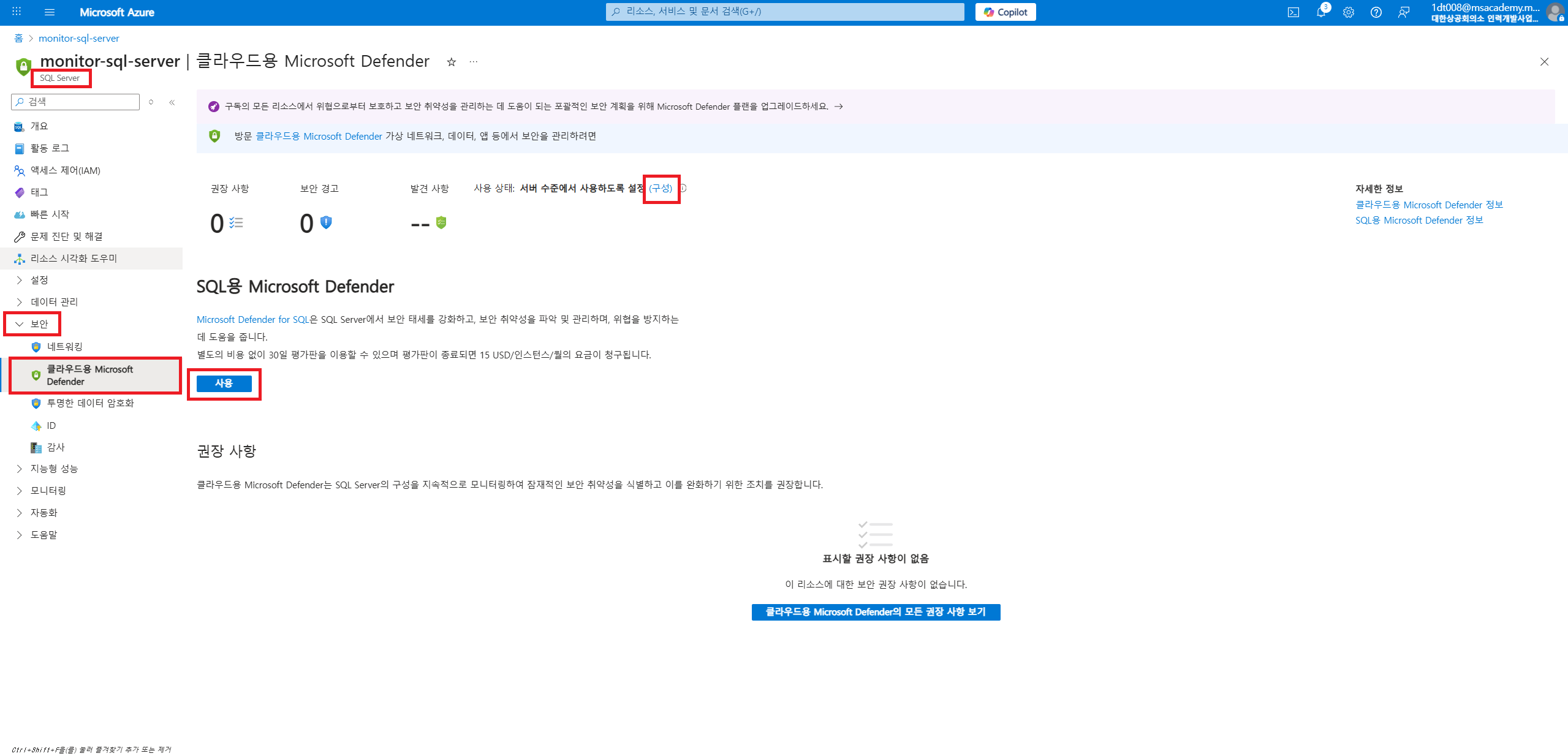
허용 및 구성

설정 확인
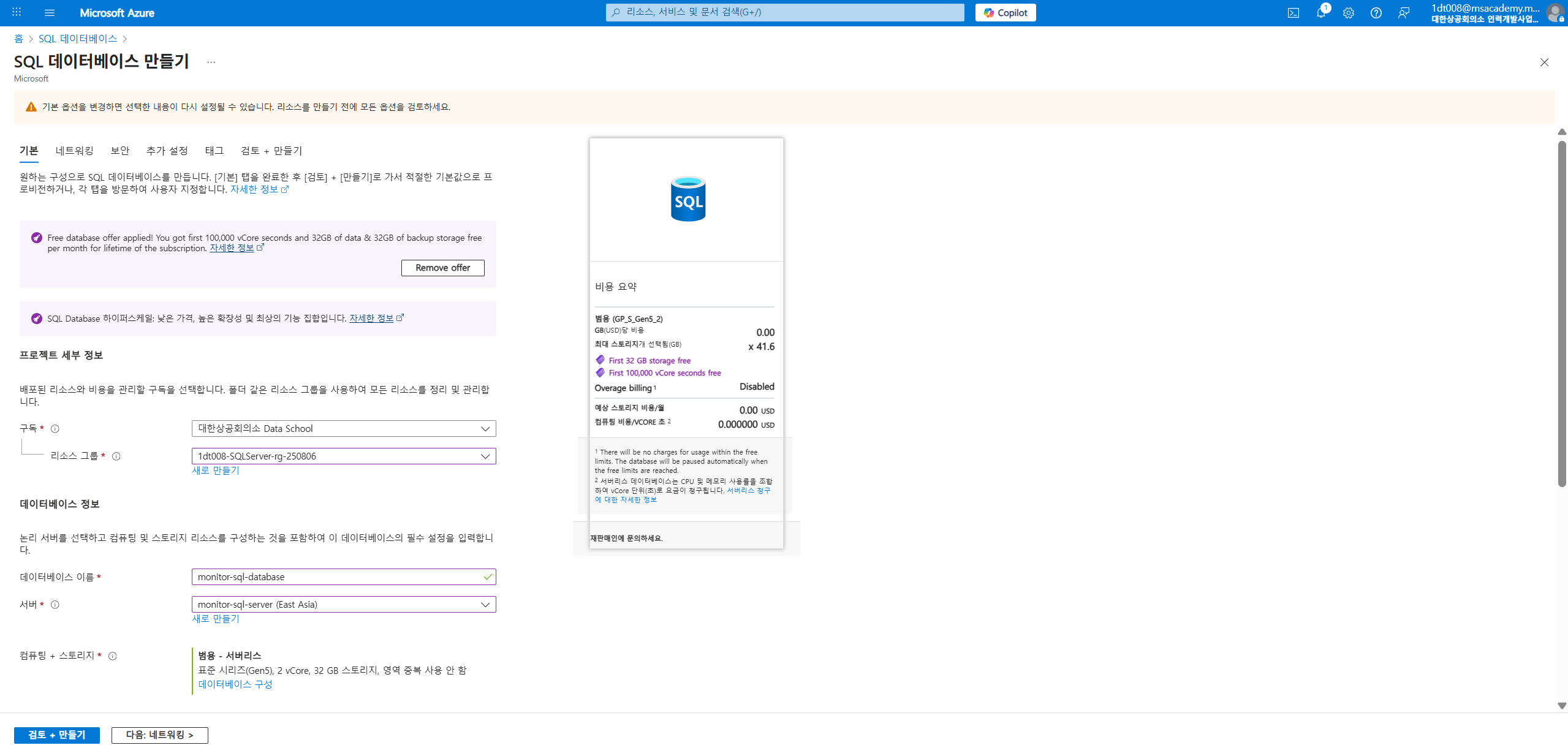
SQL Database 만들기
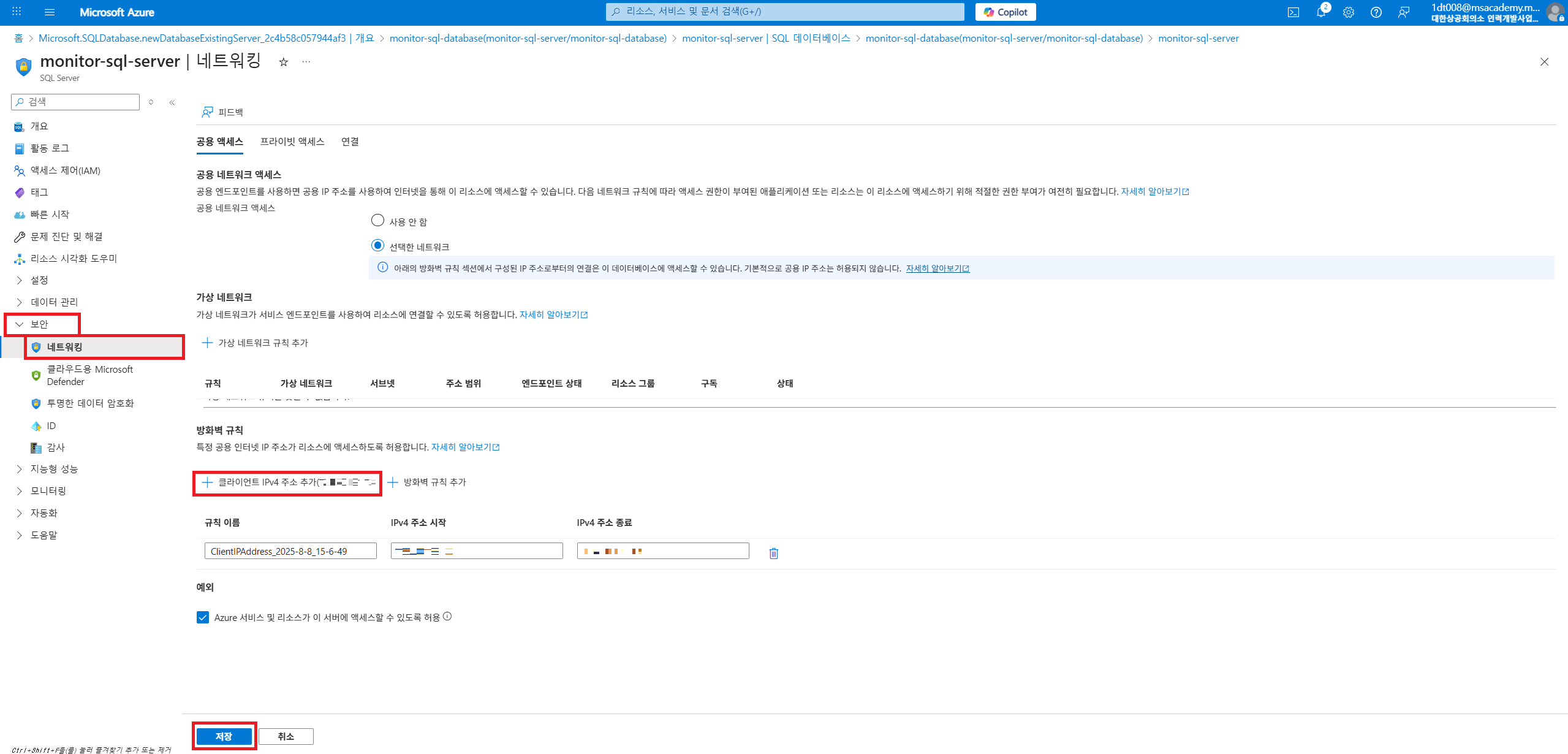
네트워크 추가
index 실습
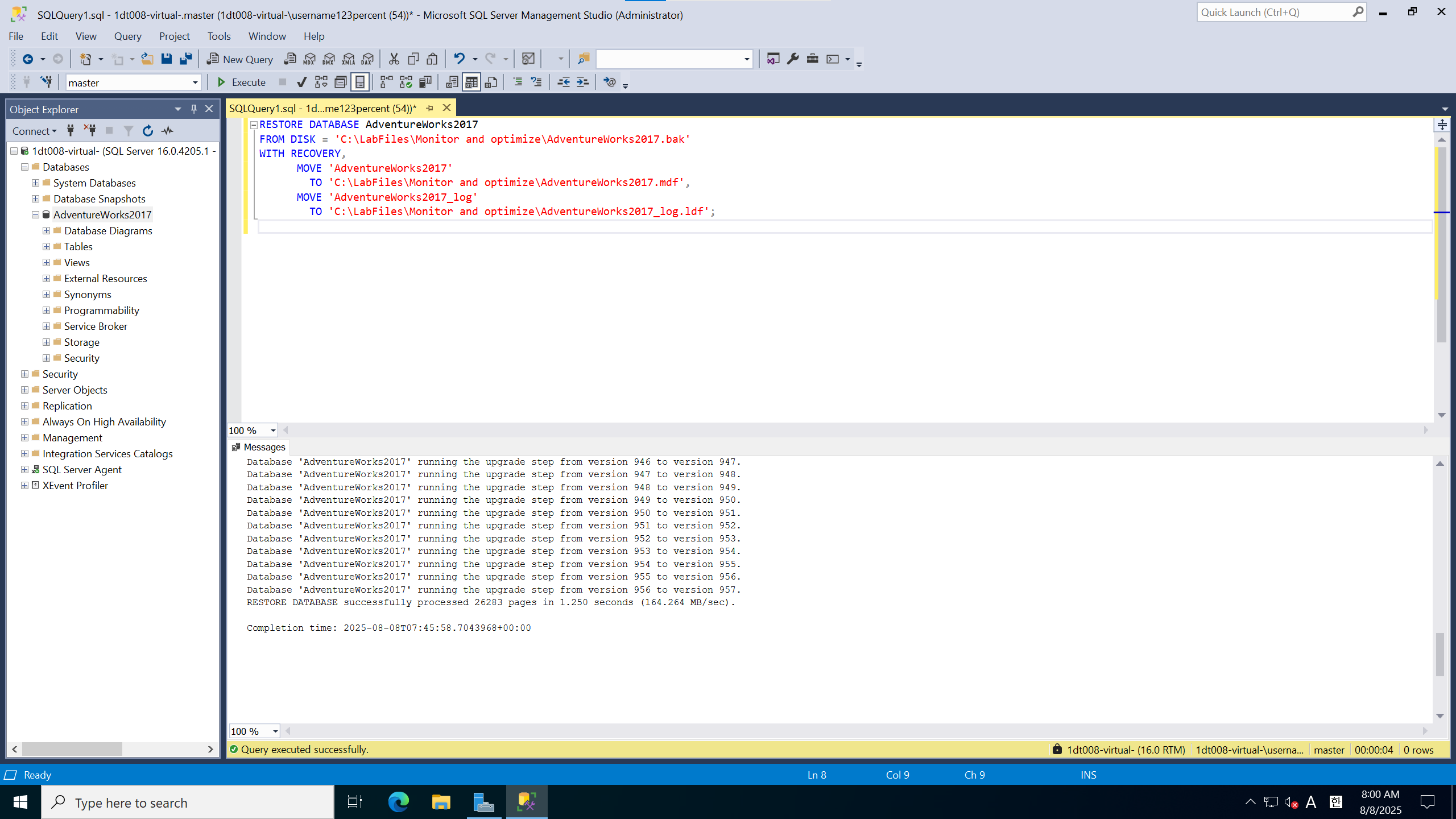
VM에 접속하여 깃허브 데이터베이스 백업 파일 링크에서 백업 파일 다운로드
SSMS 접속 이후 쿼리를 편집하여 실행하여 데이터베이스 복구 진행
RESTORE DATABASE AdventureWorks2017
FROM DISK = 'C:\LabFiles\Monitor and optimize\AdventureWorks2017.bak'
WITH RECOVERY,
MOVE 'AdventureWorks2017'
TO 'C:\LabFiles\Monitor and optimize\AdventureWorks2017.mdf',
MOVE 'AdventureWorks2017_log'
TO 'C:\LabFiles\Monitor and optimize\AdventureWorks2017_log.ldf';사용한 쿼리다. bak를 저장한 위치에 따라 경로를 바꿔서 실행하면 된다.

조각화 상태가 있는지 확인하는 쿼리
USE AdventureWorks2017
GO
SELECT
i.name AS Index_Name, -- 인덱스 이름
avg_fragmentation_in_percent, -- 평균 조각화율
db_name(database_id) AS Database_Name, -- 데이터베이스 이름
i.object_id, -- 인덱스가 속한 객체의 ID (테이블 등)
i.index_id, -- 인덱스 ID
index_type_desc -- 인덱스 유형 설명 (예: CLUSTERED, NONCLUSTERED)
FROM
sys.dm_db_index_physical_stats(
db_id('AdventureWorks2017'), -- 대상 데이터베이스 ID
object_id('person.address'), -- 대상 테이블의 객체 ID
NULL, NULL, -- 인덱스,파티션 ID는 NULL(모든 인덱스 포함)
'DETAILED' -- 'DETAILED' 모드로 상세 조각화 정보 수집
) ps
INNER JOIN sys.indexes i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id -- 인덱스 메타데이터와 조각화 정보 조인
WHERE avg_fragmentation_in_percent > 50 -- 조각화율이 50% 초과인 인덱스만 선택사용한 쿼리
USE AdventureWorks2017
GO
INSERT INTO [Person].[Address]
([AddressLine1], [AddressLine2], [City], [StateProvinceID], [PostalCode], [SpatialLocation], [rowguid], [ModifiedDate])
SELECT
AddressLine1,
AddressLine2,
'Amsterdam',
StateProvinceID,
PostalCode,
SpatialLocation,
newid(),
getdate()
FROM
Person.Address;
GO쿼리로 데이터 추가하여 index 일부러 파편화하기
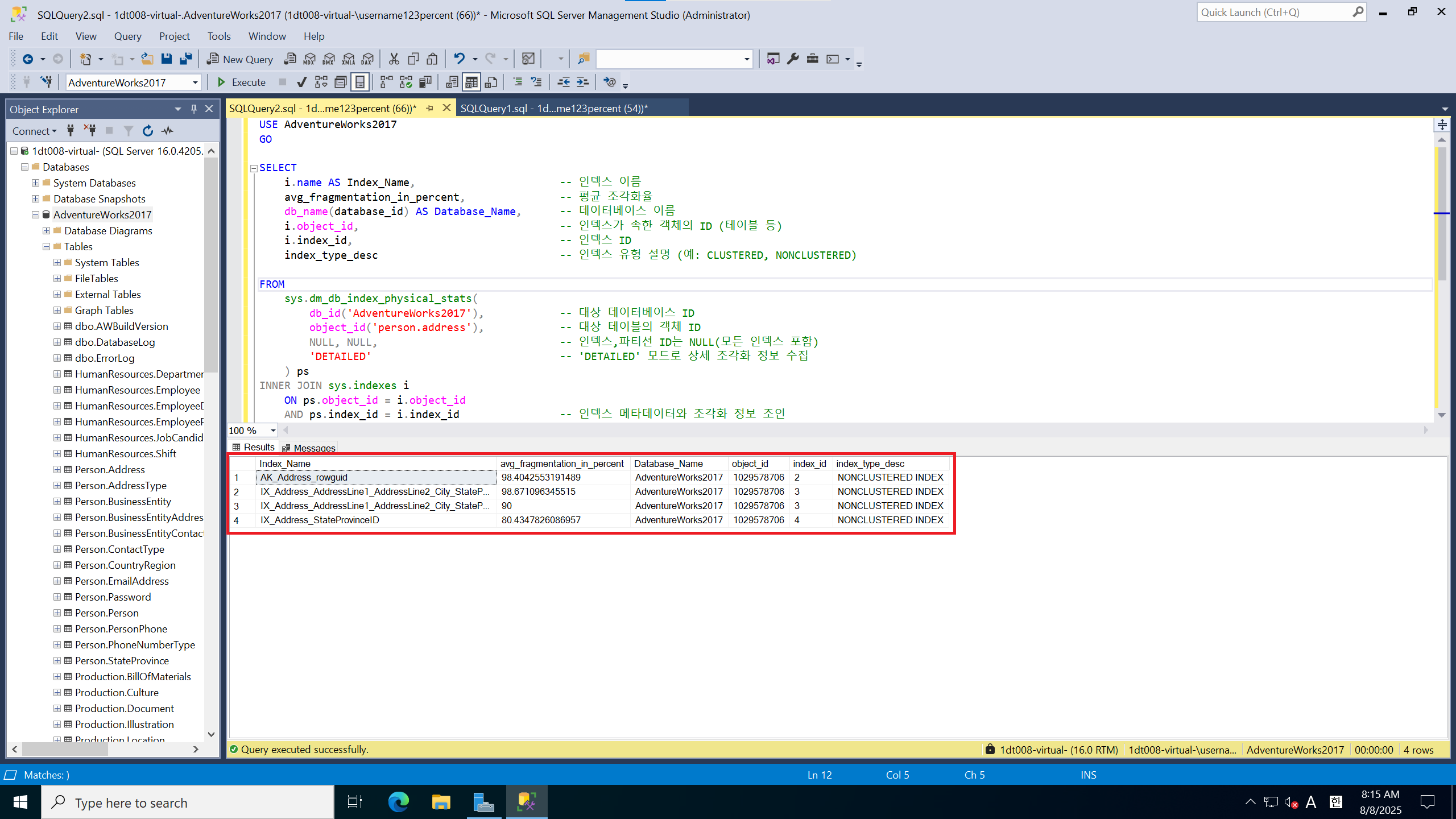
다시 확인해보면 조각난 index를 볼 수 있다.
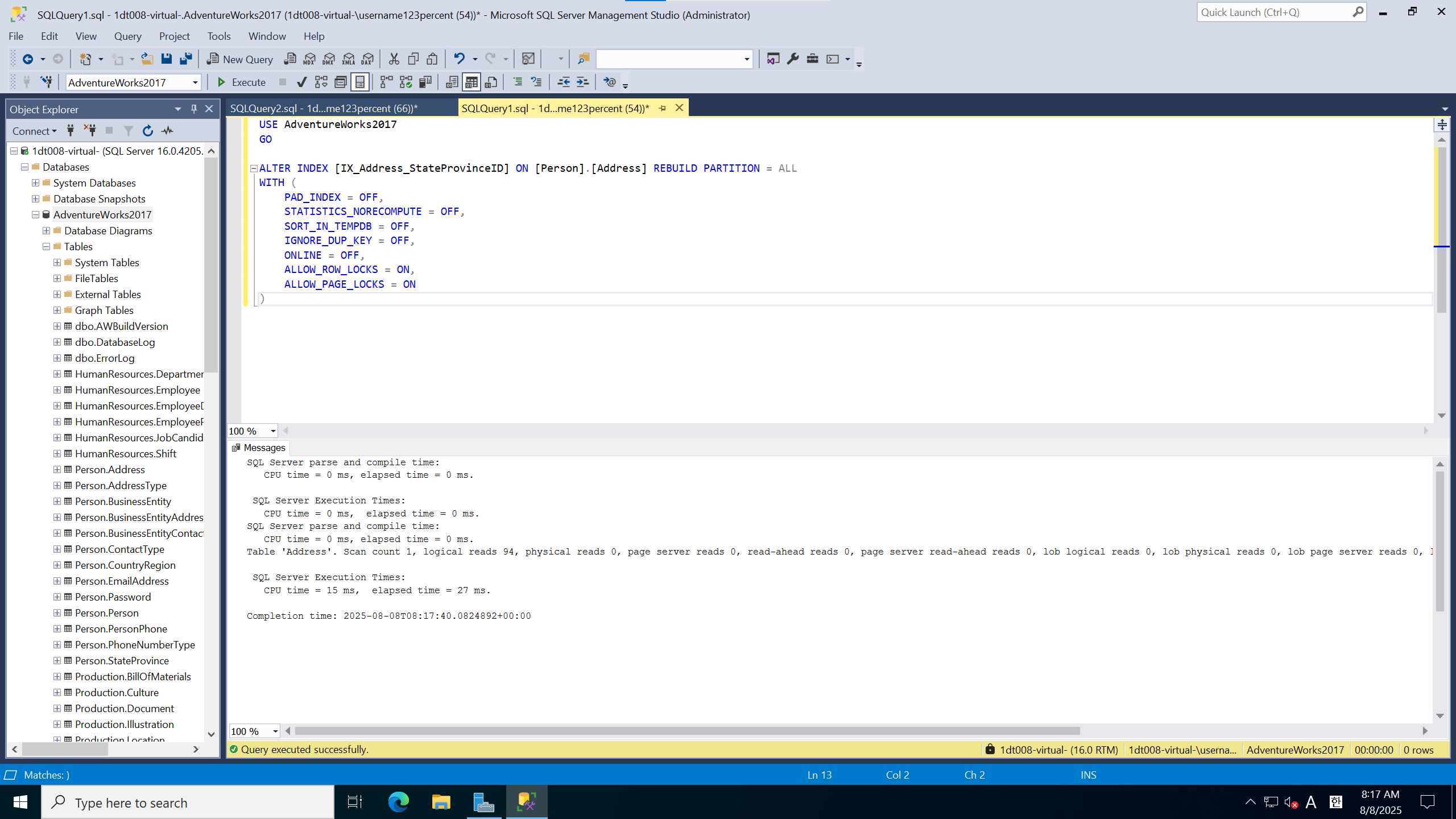
상단의 쿼리는 조각 모음 쿼리다.
하단은 조각난 상태의 index에서 쿼리 실행 결과다.
USE AdventureWorks2017
GO
ALTER INDEX [IX_Address_StateProvinceID] ON [Person].[Address] REBUILD PARTITION = ALL
WITH (
PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF,
ONLINE = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON
)조각 모음 쿼리는 위와 같다.
| With 옵션 | 의미 |
| PAD_INDEX = OFF | 리프(leaf) 페이지에 추가 여유 공간을 두지 않음 (기본값) |
| STATISTICS_NORECOMPUTE = OFF | 인덱스 통계를 자동으로 재계산하게 설정 |
| SORT_IN_TEMPDB = OFF | 정렬 작업을 tempdb가 아닌 사용자 DB에서 수행 |
| IGNORE_DUP_KEY = OFF | 중복 키 입력 시 에러 발생 (기본값) |
| ONLINE = OFF | 인덱스 재구성 중 테이블이 잠김, 사용자가 접근 불가 |
| ALLOW_ROW_LOCKS = ON | 인덱스에 행 수준 잠금 허용 |
| ALLOW_PAGE_LOCKS = ON | 인덱스에 페이지 수준 잠금 허용 |
IX_Address_StateProvinceID 인덱스를 전체 파티션 대상으로 재구성한다 (PARTITION = ALL)
REBUILD는 인덱스를 완전히 다시 생성하는 작업이다.
조각화 제거를 하고, 통계도 기본적으로 다시 계산한다. (STATISTICS_NORECOMPUTE = OFF)
SET STATISTICS IO, TIME ON
GO
USE AdventureWorks2017
GO
SELECT
DISTINCT (StateProvinceID),
count(StateProvinceID) AS CustomerCount
FROM person.Address
GROUP BY StateProvinceID
ORDER BY count(StateProvinceID) DESC;
GO선택 사항으로 쿼리 실행 시간을 보여주는 쿼리 (하단에 해당하는 쿼리)
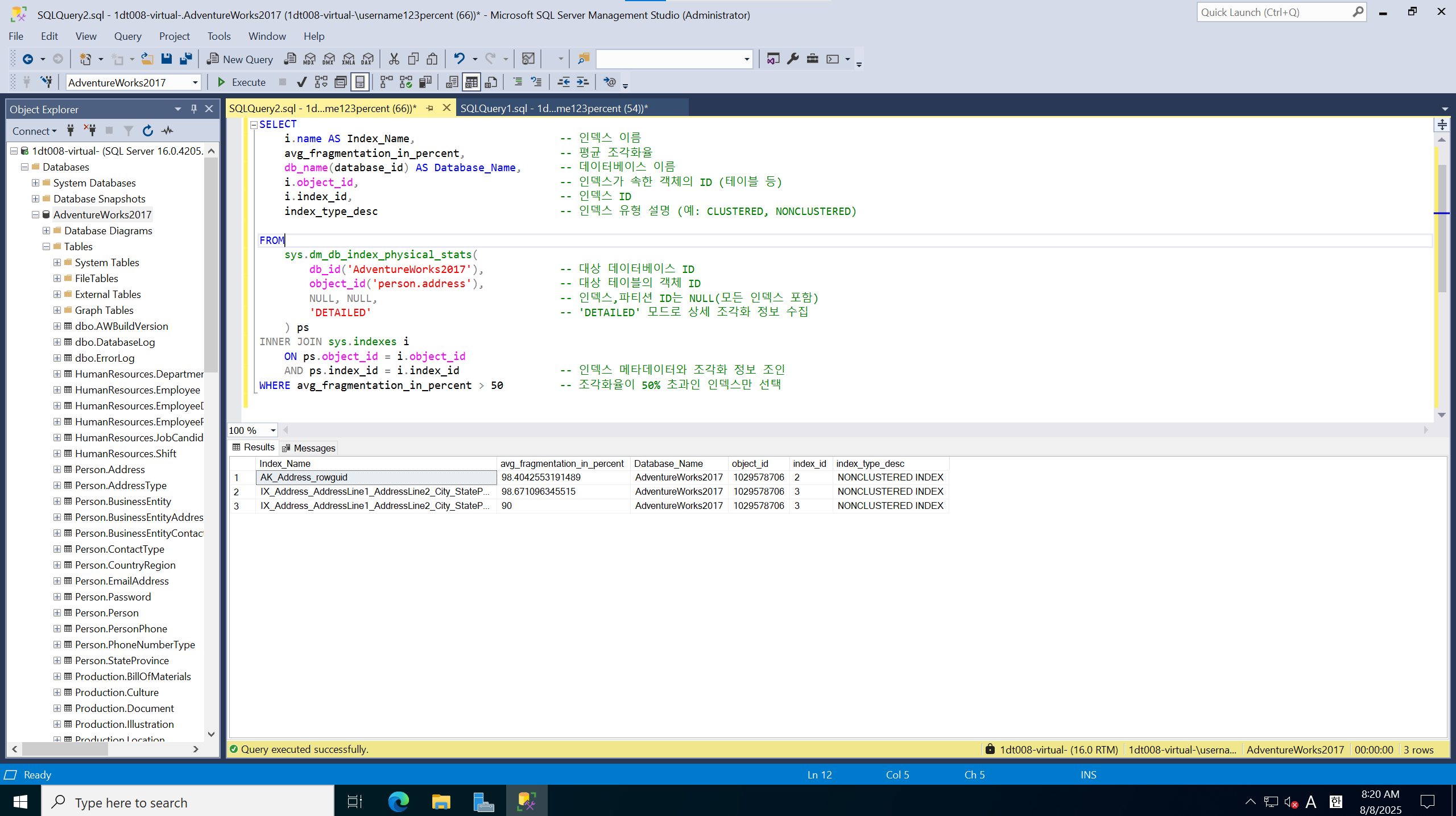
조각 모음을 하고 다시 결과 확인

설정한 컬럼에 대해서 index 파편화 해결
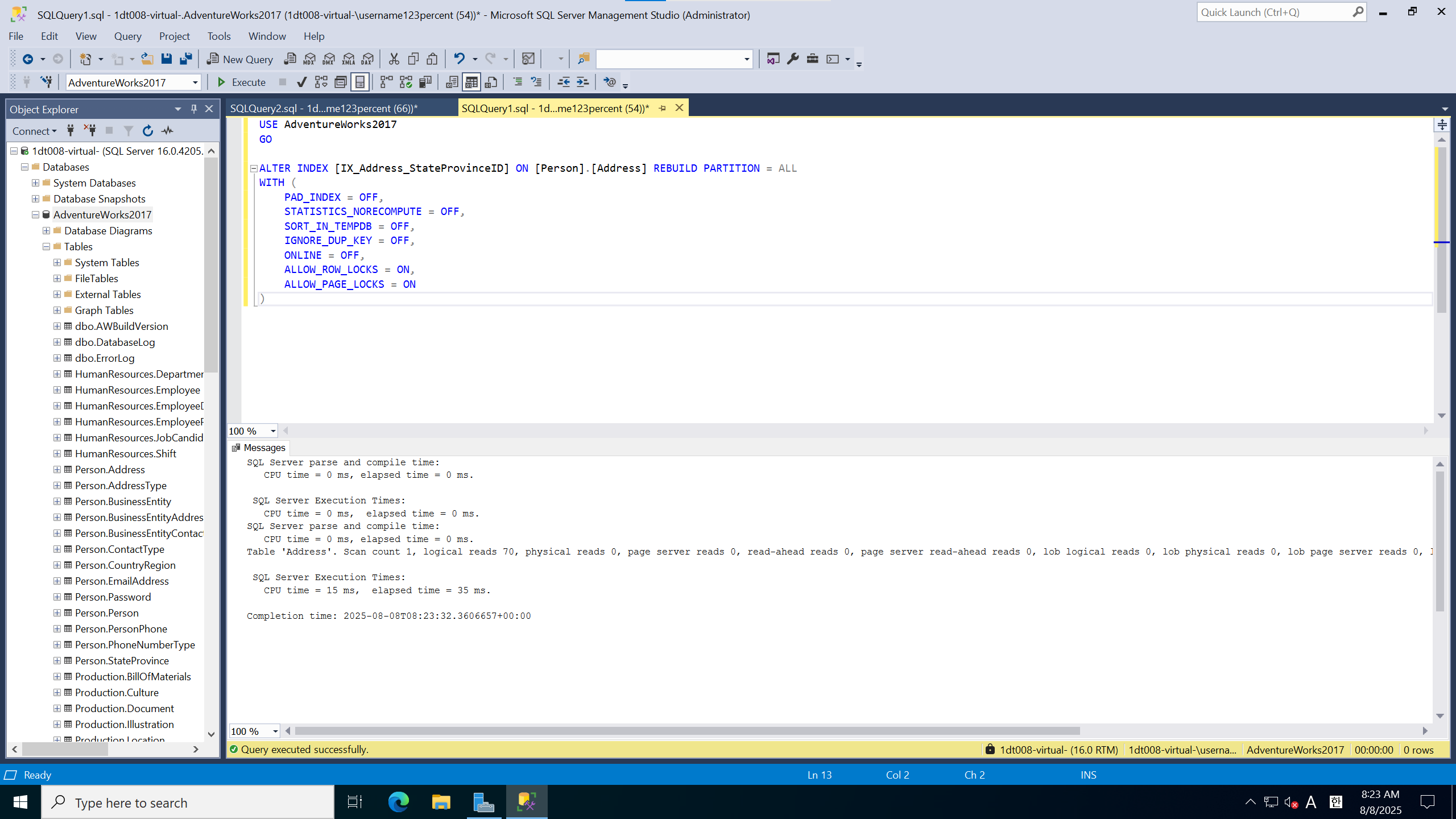
다시 실행 시간 확인

94 페이지 로드에서 70 페이지 로드로 감축
'공부 > Microsoft Data School 1기' 카테고리의 다른 글
| AzureSQLServer 운영 및 관리 7 (1) | 2025.08.12 |
|---|---|
| AzureSQLServer 운영 및 관리 6 (1) | 2025.08.11 |
| AzureSQLServer 운영 및 관리 4 (1) | 2025.08.07 |
| AzureSQLServer 운영 및 관리 3 (4) | 2025.08.06 |
| AzureSQLServer 운영 및 관리 2 (0) | 2025.08.05 |