SQL 기본 및 고급 쿼리문 6
실습
# psycopg2 사용 (Raw SQL)
cur.execute("""
INSERT INTO fms.chick_info (chick_no, breeds, gender)
VALUES ('A2310999', 'C1', 'M')
""")
conn.commit()
# SQLAlchemy 사용 (ORM)
new_chick = ChickInfo(chick_no="A2310999", breeds="C1", gender="M")
session.add(new_chick)
session.commit()ㅇㅇ
DB_HOST=localhost
DB_PORT=5432
DB_NAME=postgres
DB_USER=postgres
DB_PSWD=0.env 파일
def get_db_connection_by_psycopg2() -> connection:
# using load_dotenv
conn = psycopg2.connect(
host=os.getenv('DB_HOST'),
port=os.getenv('DB_PORT'),
dbname=os.getenv('DB_NAME'),
user=os.getenv('DB_USER'),
password=os.getenv('DB_PSWD'),
)
conn.autocommit = True
return conn호출 방법
Index

데이터베이스 테이블에서 데이터 검색 작업 속도를 향상시키기 위한 자료 구조
특징 1: 쿼리의 검색 속도를 향상시키기 위해 만든다.
특징 2: 테이블이 가진 일부 데이터를 찾기 쉬운 모양으로 정리하여 저장한 object다.
특징 3: 저장 공간을 차지한다.
Index의 장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상한다.
- 전반적인 시스템의 부하를 줄인다.
Index의 단점
- 인덱스 관리를 위해 DB의 약 10%에 해당하는 저장 공간이 필요하다.
- 인덱스 관리를 위해 추가 작업이 필요하다.
- 인덱스를 잘못 사용할 경우 오히려 성능이 저하될 수 있다.
Index를 사용하면 좋은 경우
- 규모가 큰 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 column
- JOIN, WHERE, ORDER BY에 자주 사용하는 column
- 데이터 중복도가 낮은 column
| 스캔 방법 | 설명 |
| Sequential Scan | 전체 테이블을 처음부터 끝까지 순차적으로 스캔해 데이터를 검색하는 방법으로 가장 간단하고 일반적이지만 테이블이 클 경우 속도가 매우 느리다. |
| Index Scan | Index를 이용해 테이블에서 데이터를 검색하는 방법으로 적은 수의 행을 검색할 때 효율적이다. |
| Bitmap Index Scan | Bitmap Heap Scan과 함께 동작하며 데이터 자체를 가져오지 않고, 잠재 행 위치의 bitmap을 구성한다. |
| Bitmap Heap Scan | Bitmap Index Scan으로부터 공급받은 bitmap을 읽어 저장된 페이지 번호 및 offset에 해당하는 데이터를 가져와 가시성(visibility), 적격성(qualificatino) 등을 확인하고 모든 검사 결과에 따라 행을 반환한다. 행의 수가 많고, 스캔을 통해 전체 테이블을 읽는 것을 피할 수 있는 쿼리에 사용한다. |
| Parallel Seq Scan | 순차 스캔 방법과 유사하지만 여러 작업자 프로세스를 사용해 테이블을 병렬로 스캔한다. 데이터를 검색하는 방법으로 순차 스캔보다 빠를 수 있다. |
| TID Scan | Tuple ID 목록을 사용하여 테이블에서 데이터를 검색하는 방법으로 TID는 테이블의 각 행의 고유 식별자다. |
테이블 데이터 스캔 방법

dd

dd
CREATE TABLE IF NOT EXISTS public.bank
(
client_no INTEGER NOT NULL,
age SMALLINT,
gender CHARACTER(1),
edu CHARACTER VARYING(13),
marital CHARACTER VARYING(8),
card_type CHARACTER VARYING(8),
CONSTRAINT bank_pkey PRIMARY KEY (client_no)
);ㅇㅇ
EXPLAIN SELECT * FROM public.bank b;ㅇㅇ

전체 데이터를 조회할 때에는 굳이 다른 index를 사용할 필요가 없다.
따라서 이때는 Sequential Scan을 선택한 것을 볼 수 있다.
cost는 init_cost와 total_cost의 값을 가지는데, 첫 값을 가져오는데 0.00이 필요하고, 전체 값을 가져오는데 176.00이 필요하다.
이때는 단위가 없어 추상적인 개요만을 알 수 있다.
width는 한 행을 수행함에 있어서 대략 29 byte를 차지한다라는 계산이다.
EXPLAIN ANALYZE SELECT * FROM public.bank b;ㅇㅇ

ㅇㅇ
EXPLAIN ANALYZE SELECT * FROM public.bank b WHERE client_no BETWEEN 450 AND 800;ㅇㅇ

이때는 자동으로 Index Scan으로 접근했음을 볼 수 있다.
특히 Index Scan을 함에 있어서 bank의 pkey를 사용했다는 로그도 같이 나온다.
동시에 rows에서 351개의 행을 가져왔음을 보여준다.
Execution은 전체 시간
EXPLAIN ANALYZE SELECT * FROM public.bank b
WHERE gender = 'F' AND "age" BETWEEN 50 AND 60;ㅇㅇ

ㅇㅇ
CREATE INDEX IF NOT EXISTS bank_index_gender_age ON public.bank ("gender", "age");위와 같은 구문으로 새로운 index를 생성할 수 있다.

ㅇㅇ
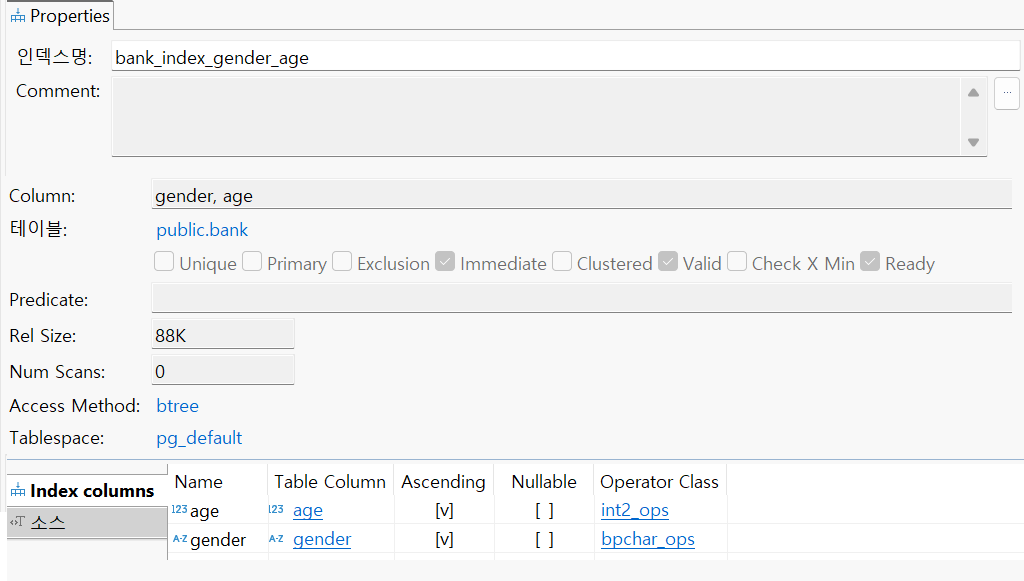
세부 사항 Properties를 보면 위와 같다.
EXPLAIN ANALYZE SELECT * FROM public.bank b
WHERE gender = 'F' AND "age" BETWEEN 50 AND 60;ㅇㅇ

결과적으로 최적의 성능을 알아서 찾아준다.
이때 주의할 점은 gender, age 순으로 index를 걸었다면, WHERE를 gender, age 순으로 색인해야 제대로 사용한다.
EXPLAIN (ANALYZE, FORMAT JSON)
SELECT * FROM public.bank b
WHERE gender = 'F' AND "age" BETWEEN 50 AND 60;FORMAT JSON이라는 옵션을 추가하면 실행 결과를 JSON으로 반환해준다.
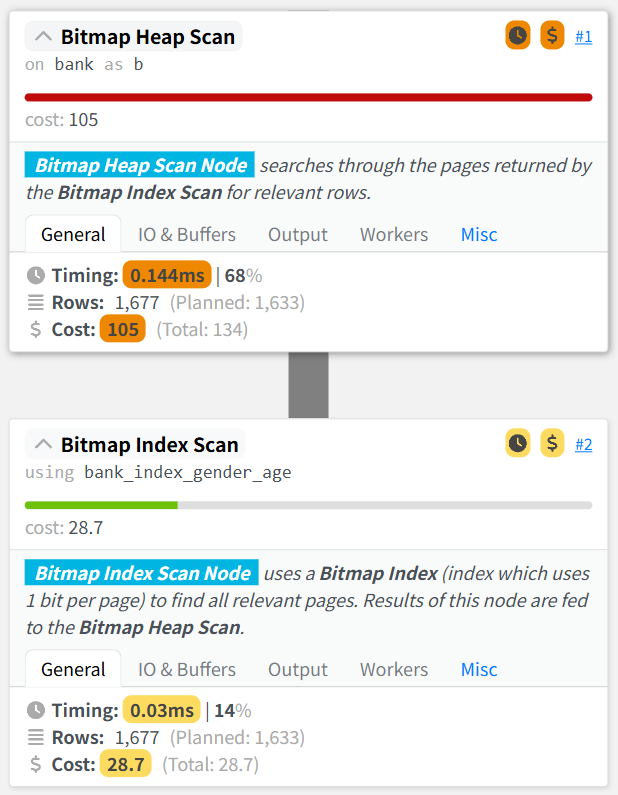
이렇게 얻은 JSON을 시각화하여 볼 수 있는 사이트가 있다.
EXPLAIN ANALYZE
SELECT *
FROM fms.prod_result pr
JOIN fms.ship_result sr
ON pr.chick_no = sr.chick_no;ㅇㅇ

ㅇㅇ
Azure Database for PostgreSQL

저번 Wordpress 실습 때와 같이 리소스 그룹을 하나 만들어준다.
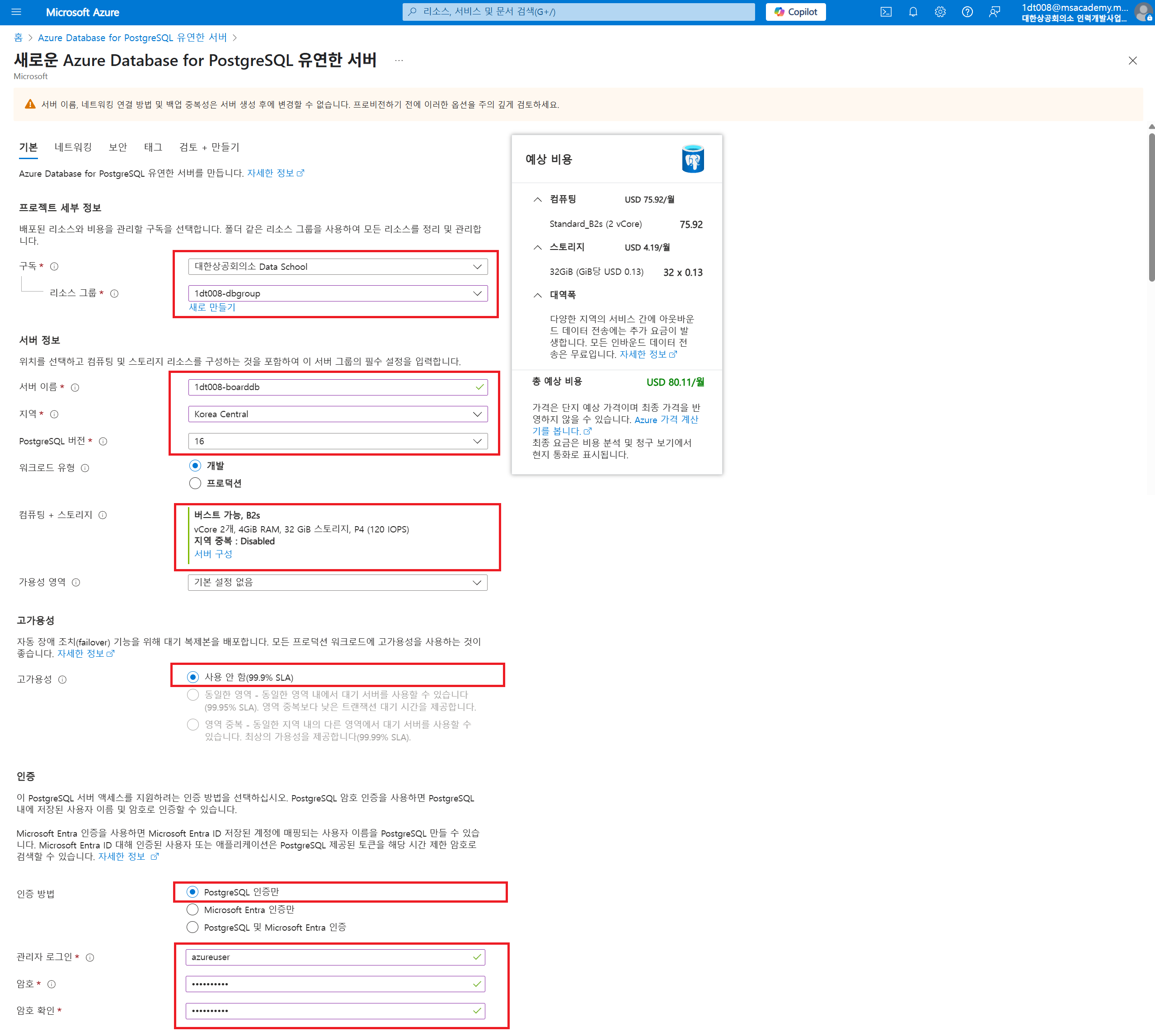
dd

dd
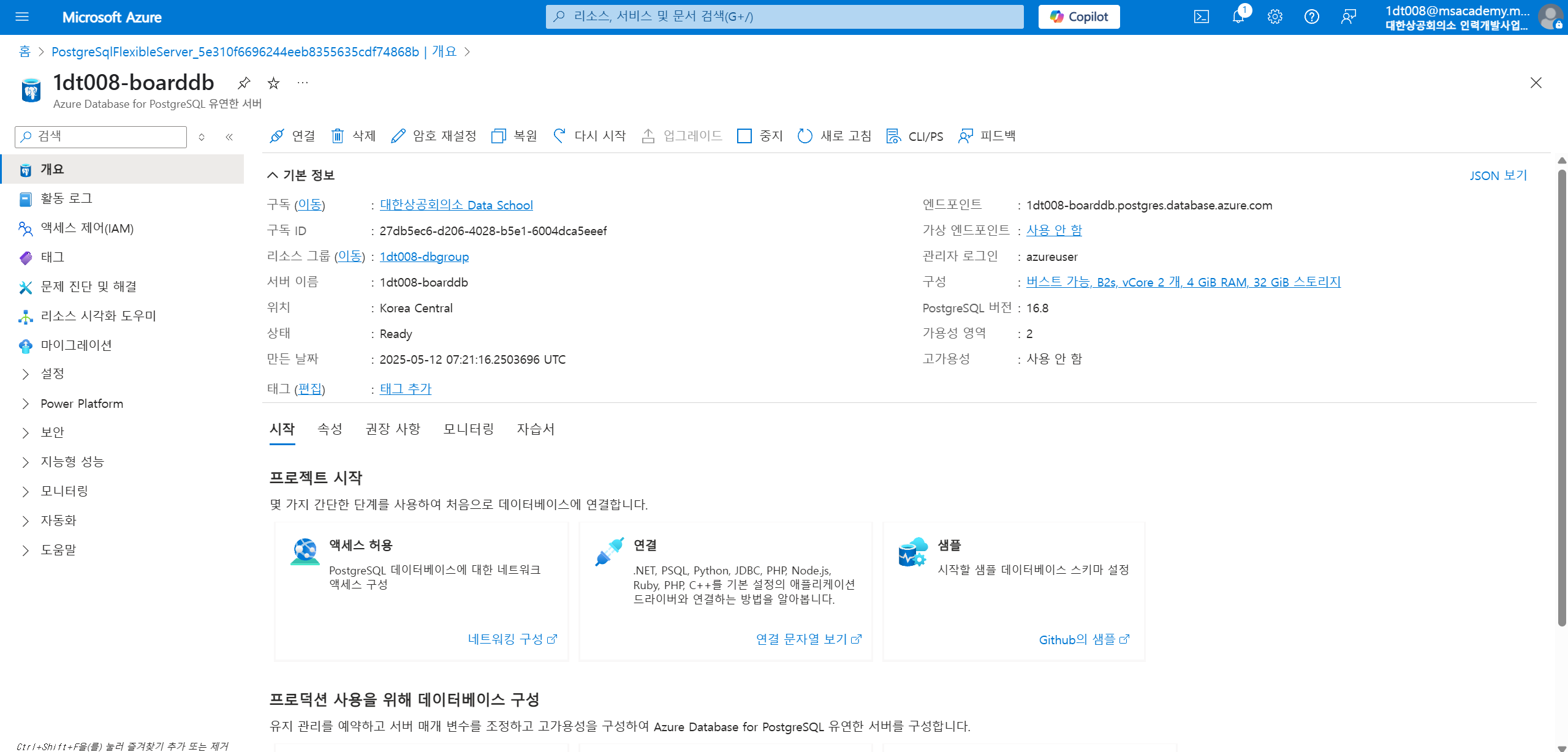
ㅇㅇ

dd

이때 한글이 깨지는 것은 터미널에서 한글 폰트가 없어 깨지는 것이라 파일에는 문제가 없다.
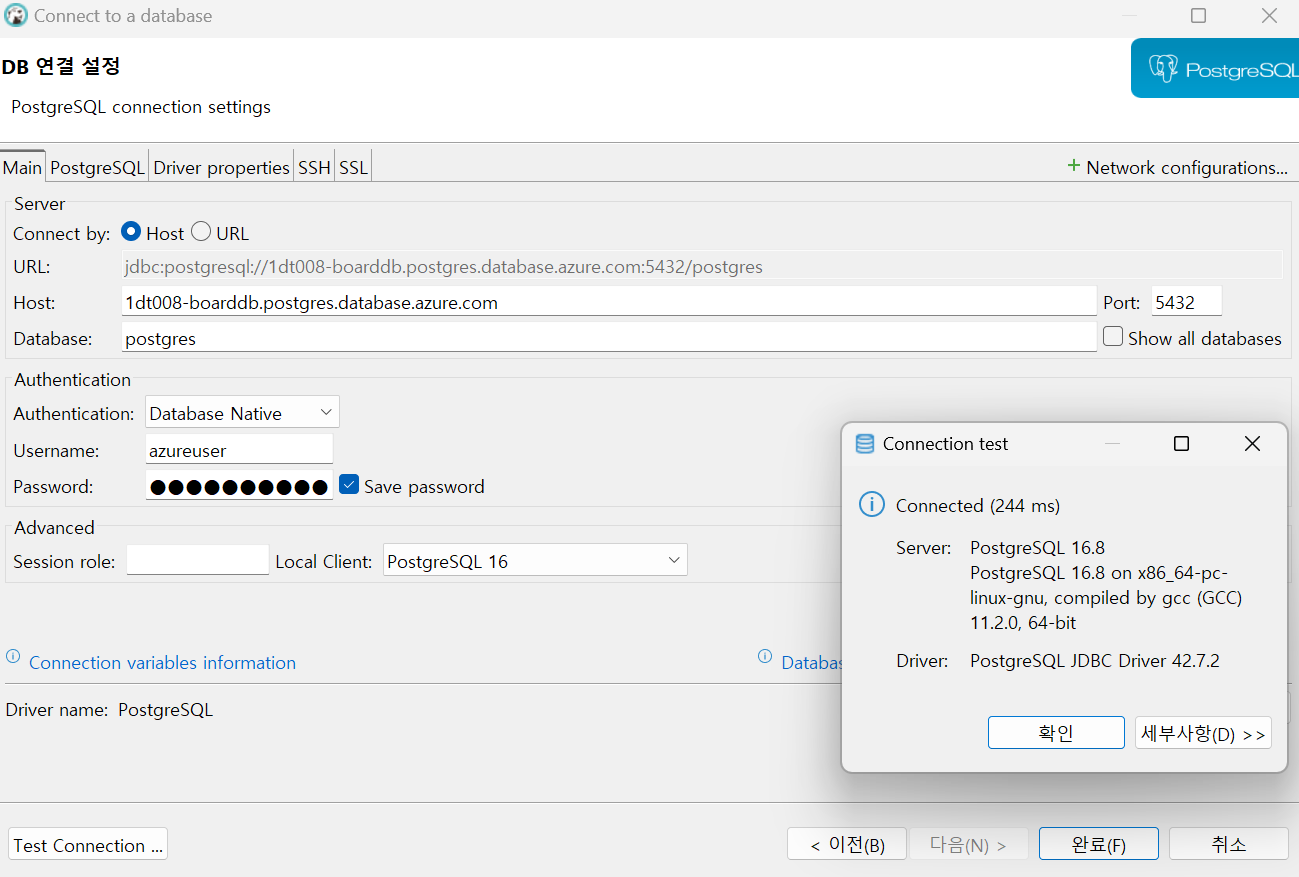
이렇게 백업한 postgresql 데이터를 새롭게 연결한다.