23. NLP Trends - ELECTRA
ELECTRA

기존 BERT는 MLM(Masked Language Model)을 주 구조로 학습하는 인공지능 모델이다.
ELECTRA는 Efficiently Learning an Encoder that Classifies Token Replacements Accurately의 약자로,
효율적인 학습 방법을 Encoder에서 적용한 모델이다.
MLM에서 예측한 단어가 올바른지 아닌지(original/replaced) 확인하는 구조를 추가한 모델이 ELECTRA다.
[MASK]를 예측하는 구조를 Generator라고 부르고, 예측 올바름을 판단하는 구조를 Discriminator라고 부른다.
물론 Generator는 BERT에서 사용하는 것보다는 작은 규모를 사용하고,
단순히 입력 변형용 및 학습으로만 사용해서 최종 모델은 Discriminator만을 사용한다.
Generator와 Discriminator의 관계를 살펴보면 경쟁하는 것처럼 보이기도 한다.
Generator가 단어를 잘 예측할수록 Discriminator는 구별하기 어려워지고,
Discriminator가 잘 구별할수록 Generator는 더 진짜 같은 단어를 예측하려고 한다.
이렇게 두 모델이나 네트워크가 서로 경쟁하는 구조를 Adversarial training이라고 한다.
대표적으로 이미지 생성의 GAN(Generative Adversarial Network)이 이러하다.

ELECTRA 논문에서 Replaced token detection pre-training vs masked language model pre-training라는 이름으로
기존에 존재하는 Generator 기반의 모델들과 Discriminator를 추가한 모델의 성능을 비교한 표다.
다른 모델보다 계산량에 비해서 GLUE score가 더 좋은 것을 확인할 수 있다.
Light Weight Models
기존의 모델을 개선한다는 것은 성능을 올리는 것에 국한하지 않는다.
메모리를 줄인다든가 학습 시간을 줄인다든가 구조를 간략하게 한다든가 등이 있다.
그 중에서도 모델을 경량화하는 것에 초점을 맞추고 진행한 연구가 다수 있다.
그렇게 나온 대표적인 경량 모델이 DistillBERT와 TinyBERT가 있다.
두 모델은 모두 Knowledge Distillation(지식 증류)라는 기법을 사용했다.
이는 BERT가 사전 학습(pretraining)하면서 배운 지식을 압축해서 학습하는 과정이다.
이를 위해 Teacher 모델과 Student 모델이라는 개념을 도입했다.

DistillBERT는 2019년 Hugging Face가 NeurIPS에 발표한 모델이다.
DistillBERT의 Teacher 모델은 BERT-large처럼 정확도는 높지만 큰 모델을 가져다가 학습을 진행하고
Student 모델은 teacher 모델보다 작은 규모의 모델을두고, teacher의 지식만을 학습하는 과정을 거친다.
정확하게는 Teacher의 softmax 확률 분포를 ground truth로 학습한다.
이러면 BERT-large의 최종 출력을 흉내내는 모양새를 띈다.

TinyBERT는 2020년 Huawei가 Findings of EMNLP에 발표한 모델이다.
DistillBERT에서 student가 teacher의 softmax 확률 분포만을 학습했다면,
TinyBERT에서는 teacher의 softmax 확률 분포, 가중치 행렬(W^Q, W^k, W^V, W^O), hidden state vector 등
중간 결과물을 싹 다 학습한다는 차이점이 존재한다.
즉 최종 출력만 흉내내는 게 아니라, layer별로 정렬해서 학습한다.
1. Hidden state distillation으로 각 층의 hidden state를 학습하고(손실함수는 MSE),
2. Attention distillation으로 각 층의 Self Attention Matrix를 학습하고(손실함수는 MSE나 KL Divergence),
3. Prediction layer distillation으로 최종 출력의 값을 학습한다.
조금 더 상세하게 teacher의 과정을 학습하는 TinyBERT는 이 과정을 2개로 나눠서 학습한다.
하나는 General Distillation(혹은 Pretraining Distillation)이라고, 본래 BERT를 학습하는 과정으로 1번과 2번을 수행하며
다른 하나는 Task Specific Distillation이라고, 특정 task의 fine tuning을 학습하는 과정으로 1, 2, 3번을 모두 수행한다.
Knowledge Graph

Knowledge Graph(지식 그래프)란, 사물(개체)들 사이 관계를 그래프 구조로 표현한 지식 데이터베이스다.
BERT는 맥락, 단어 간 유사도 판별에는 뛰어나나, 주어진 데이터 외 정보 활용에는 좋지 못하다.
그래서 외부 정보와 그 관계를 지닌 KG를 학습하여, 상식을 추가해주는 형태의 연구가 이루어지고 있다.
언어 모델에 KG를 통합한 대표적인 사례로 ERNIE와 KagNet이 있다.

ERNIE(Enhanced Language Representation with Informative Entitites)
그래프의 노드를 embedding한 entity embedding vector와 기존의 token embedding vector를 연결해서 사용
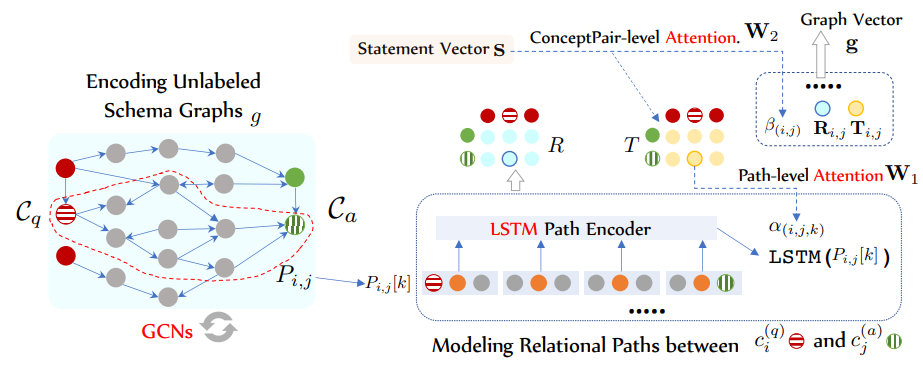
KagNet(Knowledge Aware Graph Networks for Commonsense Reasoning)
각각의 질문과 정답 후보 쌍을 외부 지식 그래프에서 서브 그래프 형태로 탐색하는 모델