옥냥이 불안전한 놀이터, AI 모델 선정하기
RTC-mariokart-8-AI/3_select_model.ipynb at main · miny-genie/RTC-mariokart-8-AI
RTC(RoofTopCat)'s Mariokat 8 deluxe(nintendo switch platform) predicting AI model - miny-genie/RTC-mariokart-8-AI
github.com
현재 작성하는 코드들은 위의 깃허브 링크에 커밋해두었다.
수정 및 개발을 진행하다보니 일부 코드가 달라진 점이 있을 수 있다.
1. 모델 선정
# "clf_lgbm": LGBMClassifier() > 성능 문제로 인한 제외
# "clf_svc": SVC(probability = True) > 성능 문제로 인한 제외
clf_model_dict = {
"clf_ridge": LogisticRegression(penalty='l2', solver='lbfgs'),
"clf_lasso": LogisticRegression(penalty='l1', solver='liblinear'),
"clf_logistic_regression": LogisticRegression(),
"clf_logistic_regression_": LogisticRegression(solver='liblinear'),
"clf_adaboost": AdaBoostClassifier(),
"clf_gradient_boosting": GradientBoostingClassifier(),
"clf_random_forest": RandomForestClassifier(),
"clf_xgb": XGBClassifier(use_label_encoder=False, eval_metric='logloss'),
"clf_catboost": CatBoostClassifier(verbose=0),
"clf_decision_tree": DecisionTreeClassifier(),
}테스트할 분류 모델들을 전부 모아놨다.
Regression의 Ridge와 Lasso에 해당하는 모델은 각각 LogisticRegression의 penalty 매개변수로 설정했다.
penalty를 l2로 설정하면 Ridge와 유사하게, penalty를 l1으로 설정하면 Lasso와 유사하게 사용할 수 있다.
LogisticRegression은 solver 매개변수를 사용하여 소규모 데이터셋에 적합한 liblinear 유무에 따라 2가지를 사용한다.
LGBMClassifier 모델과 SVC 모델은 테스트한 결과 모든 점수가 0에 가깝게 나왔다.
두 모델은 우선 주석 처리를 해놓았다. 추후 상황에 따라 모델 선정을 결정한다.
# "reg_lgbm": LGBMRegressor() > 성능 문제로 인한 제외
reg_model_dict = {
"reg_ridge": Ridge(),
"reg_lasso": Lasso(),
"reg_linear_regression": LinearRegression(),
"reg_adaboost": AdaBoostRegressor(),
"reg_gradient_boosting": GradientBoostingRegressor(),
"reg_random_forest": RandomForestRegressor(),
"reg_xgb": XGBRegressor(),
"reg_catboost": CatBoostRegressor(verbose=0),
"reg_decision_tree": DecisionTreeRegressor(),
"reg_svr": SVR(),
}테스트할 회귀 모델들을 전부 모아놨다.
분류처럼 회귀에서도 성능이 0에 가깝게 나온 모델은 우선 제외하고 계산했다.
2. 모델 학습
def fit_model(
model: BaseEstimator,
X: pd.DataFrame,
y: pd.Series,
test_size: float = 0.2,
random_state: int = 42
) -> tuple[BaseEstimator, pd.DataFrame, pd.Series, pd.DataFrame, pd.Series]:
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size = test_size,
random_state = random_state
)
model.fit(X_train, y_train)
return model, X_train, X_test, y_train, y_test모델과 종속 변수, 독립 변수를 매개변수로 입력한다.
그리고 학습한 모델, train과 test를 나눈 데이터셋들을 반환하는 fit_model() 함수 선언 후 사용한다.
이때 PEP, type hint에 유의하면서 함수를 작성한다.
def eval_clf_model(model: BaseEstimator, X: pd.DataFrame, y: pd.Series) -> tuple[float]:
y_pred = model.predict(X)
y_proba = model.predict_proba(X)[:, 1]
accuracy = accuracy_score(y, y_pred) # 정확도
precision = precision_score(y, y_pred) # 정밀도
recall = recall_score(y, y_pred) # 재현율
f1 = f1_score(y, y_pred) # F1 점수
roc_auc = roc_auc_score(y, y_proba) # ROC-AUC 점수
return accuracy, precision, recall, f1, roc_auc분류(classifier) 모델들을 평가하는 함수의 수도(pseudo) 코드다.
당연하게도 회귀(regression) 모델 점수 평가는 다르기 때문에 함수를 따로 작성해야 한다.
추가 주의사항으로 CatBoost 코드는 따로 작성해야 한다.
CatBoost는 기본적으로 카테고리형 데이터를 처리하도록 설계한 모델이다.
특히 타겟 변수의 데이터 타입을 기반으로 예측 결과의 타입을 결정한다.
즉 이진 분류에서 타겟 변수의 값이 문자열('True', 'False')이라면,
CatBoostClassifier의 predict() 메소드는, 예측 결과를 동일한 문자열 타입으로 반환한다.
그래서 문자열 처리에 대한 코드를 작성해주어야 한다.
def clf_cross_validation(
model: BaseEstimator,
X: pd.DataFrame,
y: pd.Series,
cv: int = 5
) -> tuple[list[float]]:
# No1 cv
cross_val_score()
# No2 cv
skfolds = StratifiedKFold(n_splits = 5, random_state = 42, shuffle = True)
cross_val_score(cv=skfolds)
# No3 cv
skfolds = StratifiedKFold(n_splits = 5, random_state = 42, shuffle = True)
skfolds.split(X, y)
eval_clf_model(model, X_val, y_cal)
return scores1, scores2, scores3cross validation으로 모델 점수를 평가한다.
이때 사용하는 cross validation은 총 3가지 방법으로 진행한다.
1. sklearn.model_selection 라이브러리에서 지원하는 cross_val_score() 함수로 계산한다.
2. cross_val_score() 함수에 StratifiedKFold로 나눈 데이터를 집어넣어 계산한다.
3. StratifiedKFold로 나눈 데이터로 sklearn.metrics 라이브러리에서 지원하는 함수로 직접 계산한다.
함수 이름이 clf_cross_validation()인 이유는 분류와 회귀의 점수 측정이 다르기 때문이다.
분류(clf, classifier)는 accuracy, precision, recall 같은 방법으로 점수를 측정하지만,
회귀(reg, regression)는 r2, mae, mse, rmse 같은 방법으로 점수를 측정한다.
역할이 다르다고 판단하여 두 함수를 쪼개두었다.

LogisticRegression 모델을 clf_cross_validation로 평가한 점수를 시각화하면 이런 느낌이다.
점수의 최저점과 최고점을 보기 쉽게, 정렬한 뒤 그래프로 그렸다.
확실히 같은 cross_validation이라 하더라도, 계산 방식에 따라 미세한 점수 차이를 보인다.

종류에 따라서 시각화한 LogisticRegression 모델 점수이다.
상단의 꺾은선그래프는 한 fold의 전체 평균이라면,
바로 위의 히스토그램은 scoring method별 평균 점수에 해당한다.
cvs와 sfk는 각각 cross_val_score의 약어, stratifiedkfold의 약어로써 사용했고,
mix는 stratifiedkfold를 cross_val_score에 혼합하여 적용했다는 의미로 사용했다.

보기 좋게 scoring method끼리 묶어서, cross_validation 방법에 따라서 색상을 달리 해보았다.
전반적으로 StratifiedKFold로 나눈 데이터를 cross_val_score에 넣은 게 점수가 높다.
확실히 데이터의 불균형이 높아 accuracy와 roc_auc는 비교적 높게 나온다.
그에 비해 양성을 정확히 예측해야 하는 precision과 recall은 비교적 낮게 나온다.
물론 이 모델이 LogisticRegression이라는 것과 불균형에 대한 어떠한 전처리도 하지 않았다는 걸 감안해야 한다.
3. 분류(clf) 모델 점수 평가 및 시각화

각 모델별로 15개의 점수를 확인하여 데이터프레임을 작성했다.
위에서부터 5개씩 cvs, mix, skf 점수순이고, scoring method는 accuracy, precision, recall, f1, roc_auc 순이다.

scoring method별 clf 모델 점수 평가 그래프다.
전반적으로 상단에 분포한 직선이 좋은 성능을 발휘하는 모델이다.
당장 보기에 GradientBoosting, RandomForest, CatBoost, DecisionTree가 좋아보인다.
아무래도 트리 기반의 모델들이, 현재 데이터에서 좋은 성능을 보여주는 것 같다.
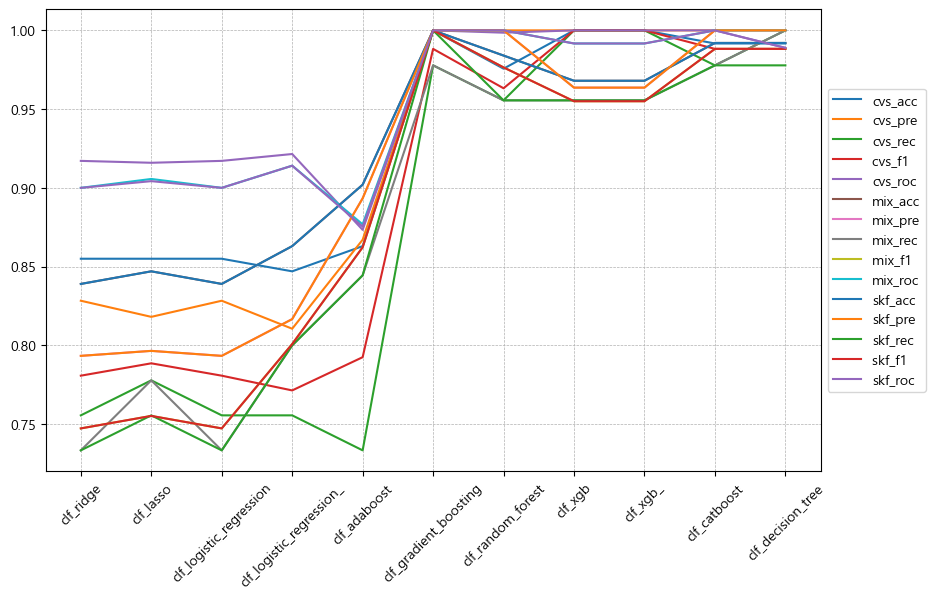
clf 모델별 scoring method 점수 평가 그래프다.
세로 grid를 기준으로 상단에 몰려있는 모델이 좋은 성능을 발휘하는 모델이다.
GradientBoosting, CatBoost, DecisionTree가 비교적 상단에 몰려있다.
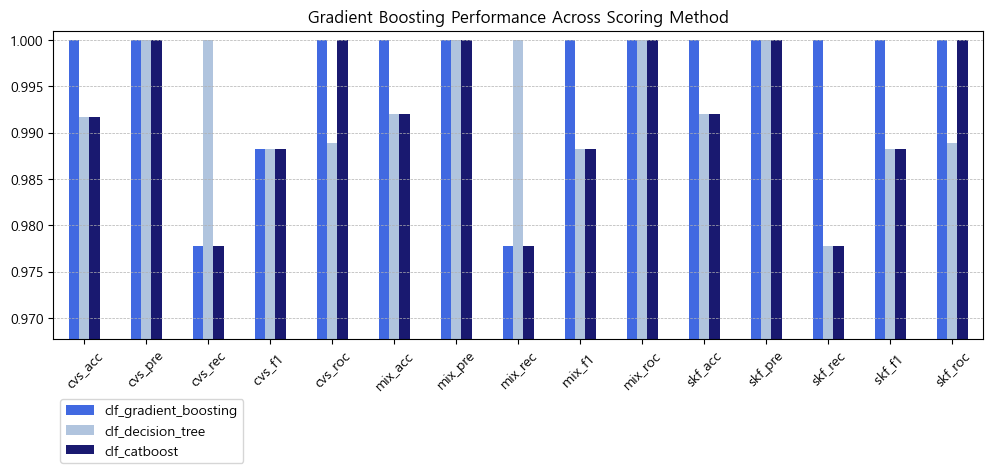
성능이 좋게 나온 모델들 점수만을 뽑아서 그래프를 그려보았다.
상위권 모델 중에서도 GradientBoosting이 압도적인 예측 성능을 보인다.
DecisionTree와 CatBoost는 비등비등한 성적을 보인다.
recall 점수는 DecistionTree가 더 높지만, roc_auc 점수는 CatBoost가 더 높다.
4. 회귀(reg) 모델 점수 평가 및 시각화
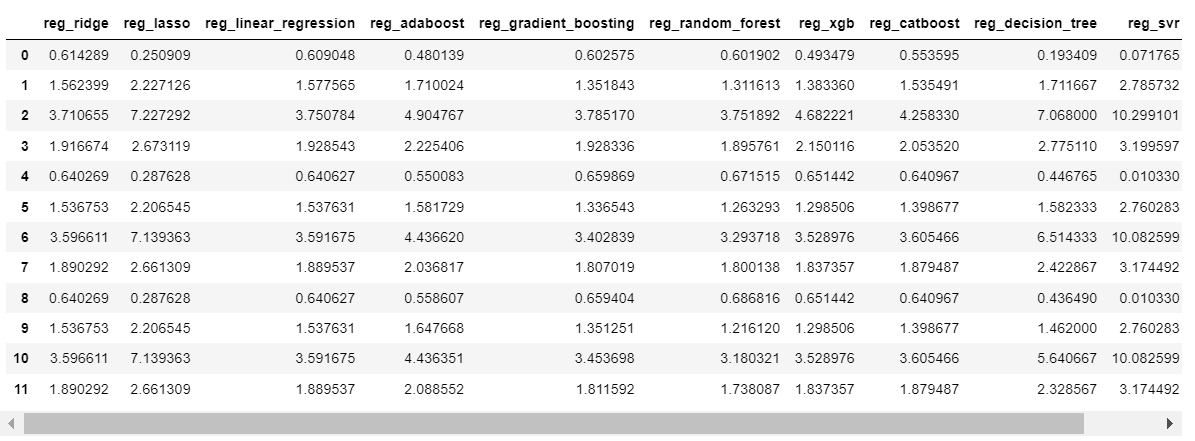
마찬가지로 회귀(regression) 모델에 대한 점수 생성하여 데이터 프레임으로 만들었다.
위에서부터 4개씩 cvs, mix, skf 점수순이고, scoring method는 r2, mae, mse, rmse 순이다.

scoring method별 reg 모델 점수 평가 그래프다.
r2는 높을수록 좋고, mae, mse, rmse는 오차이기에 낮을수록 좋다.
하단에 꽤 많은 모델이 몰려있지만, LinearRegression, GradientBoosting, RandomForest가 성능이 좋다.

reg 모델별 scoring method 점수 평가 그래프다.
clf처럼 무언가 도드라지는 특징을 얻을 수 있을까해서 한번 그려보았다.
하지만 4가지의 scoring method가 같은 방향성을 지닌 게 아니기에 한 눈에 알아보기는 어렵다.
그나마 전반적으로 낮은 곳에 몰려있는 GradientBoosting, RandomForest가 눈에 띈다.

r2는 높으며 mae, mse, rmse가 낮은 모델 2개를 선정했다.
두 개의 그래프에서 공통적으로 보이는 RandomForest와 GradientBoosting 점수를 비교했다.
성능 면에서는 RandomForest가 미세하게 좋지만,
분류(classifier)와의 일관성을 생각했을 때 GradientBoosting도 괜찮아 보인다.

성능이 가장 좋았던 2개의 모델에 실제로 값을 예측해보았다.
hyphen(-)을 기준으로 왼쪽이 모델 예측값, 오른쪽이 실제 결괏값이다.
왼쪽 모델 예측값 중 왼쪽이 RandomForest 예측값, 오른쪽이 GradientBoosting 예측값이다.
예측과 실제 결괏값이 상당히 유사함을 알 수 있다. 이정도면 쓸만하다.
참고로 실제 결괏값으로는 train_test_split으로 나눈 test 셋을 사용하지 않았다.
2024년 2월 27일 마리오카트 유튜브본의 데이터를 새롭게 수집하여 예측에 사용했다.
불안전한 놀이터 결과는 없었지만, 순전히 등수를 예측함에 있어서는 더 좋으리라고 생각했다.
5. 추후 방향 및 유의점

- 함수들의 type hint 제대로 작성하기
- 그래프로 시각화하기
- track_E 숫자, 정도의 차이를 학습하지 않는 방법 모색
- 성능 평가 점수말고, feature_importance도 반드시 확인하기 > 불균형 정도
- K-fold에서 K 값 조절하기
- 시각화: K에 따라서, 점수에 따라서 > 꺾은선그래프
- 시각화: 각 모델별 평균치 > 산점도
- GridSearchCV로 모델 선정 후 하이퍼 파라미터 튜닝하기
- C(강도) 범위 최솟값, 최댓값 판단하기
- 각 파라미터 가중치 산출하기