csv 파일 만들기
혹시 모를 상황을 대비하여 사관님께 허락을 받았다...!
사실 일일이 실제 상황에서 데이터 수집을 하는 소요 기간이 반 이상 먹고 들어간다고 생각한다.
힘들게 데이터를 수집해주셨을 텐데... 흔쾌히 저렇게 얘기해주셔서 감사합니다!
이제 데이터를 가공할 시간이다.
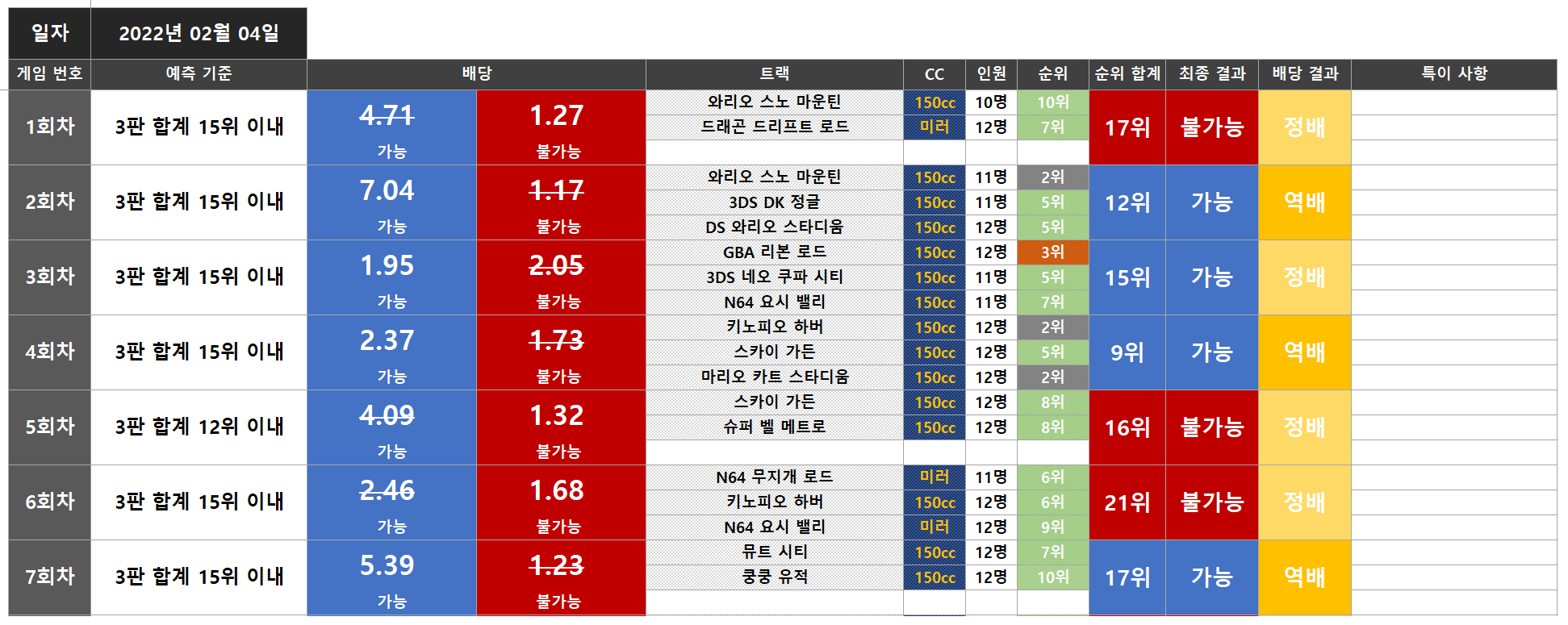
위 데이터에 팬카페 사관님이 기록해주신 데이터(이하 사관 데이터) 중 일부이다.
사관님도 유튜브를 보고 기록했기 때문에 결측치나 이상치가 있을 수 있다고 적어놓으셨다.
그래서 데이터를 수기로 직접 옮기며 이중으로 확인하고 있다.
유튜브도 보면서 모든 데이터에 대해 확인하는 것은 사실상 어렵기 때문에, 뭔가 이상하다고 느끼는 부분만 확인한다.
수기로 데이터를 정리하는 것은 사실 고집이다.
데이터를 다뤄보니 얼마나 깨끗한지(clean)가 왜 중요한지 알게 되었다.
그래서 오류가 나지 않게끔 직접 수작업으로 옮기는 중이다.
(종종 알바 공고에서 '데이터 노가다 아르바이트'가 있는 이유를 이해했다...)
또한 엑셀 데이터를 불러와서 파이썬 코드로 RPA를 만들까도 고민했다.
하지만 예외가 있으면 문제가 발생하고, 예외 코드를 또 작성하고 하면 시간이 분명 오래 걸릴 것이다.
차라리 그걸 만들 시간에 직접 옮기는 게 더 빠르다고 판단했다.
하나하나 데이터를 보면서 '도메인 지식'이라는 것을 체감할 수도 있지 않을까? 하는 생각도 있다.
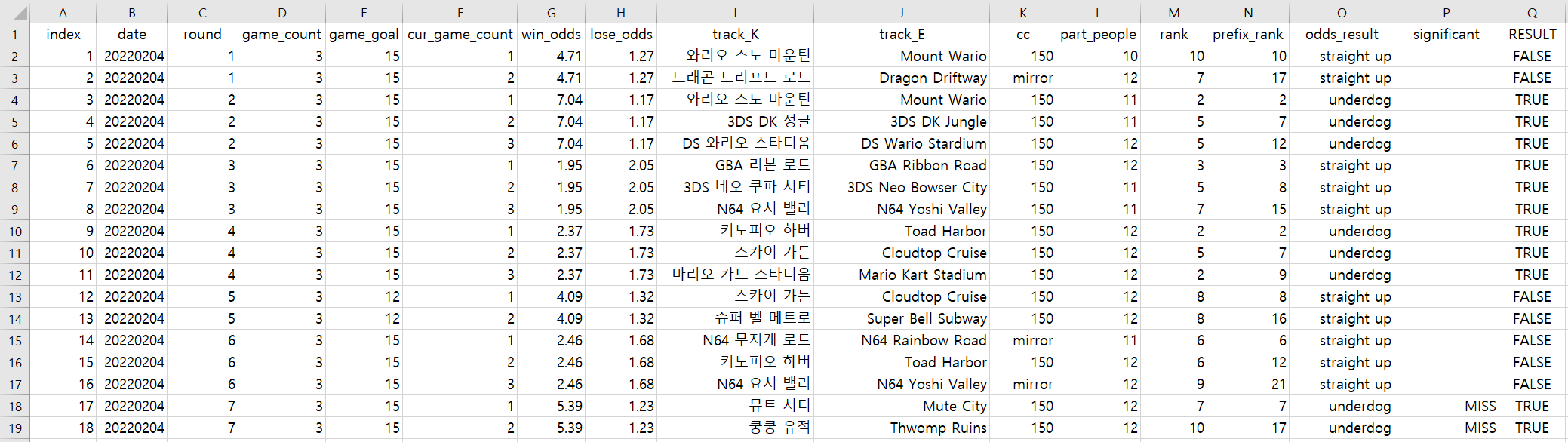
csv 파일의 대략적인 느낌은 위와 같다.
사관 데이터에 있는 정보를 최대한 자세하고, 모든 정보를 다 옮겨놓고 싶었다.
필요없다면 drop column을 하면 그만이지만, 그때 가서 필요한 정보가 생긴다면 골치가 아파진다.
또한 독립으로 존재하면 의미가 없을지 몰라도, 다른 column과 조합하면 의미가 생길 수도 있으니 말이다.
예를 들어서 round 컬럼을 살펴보자.
밑에서 설명하겠지만 round 컬럼은 '몇 번째 게임인지 나타내는 데이터'이다.
첫 판이라면 손이 덜 풀려서 질 수도 있고, 게임을 오래 하면 승률이 올라갈 수도 있다.
역으로 게임을 오래 하면 피로가 쌓여 승률이 오히려 내려갈 수도 있다.
현재 시점에서는 모르기에 csv 파일에 넣을 필요가 있다고 판단했다.
필요 없으면? 위에서 말한대로 drop하면 그만이다.
| index | 데이터를 구분하기 위한 인덱스, 데이터프레임화하면 자동으로 인덱스가 생기지만 혹시 몰라 추가 |
| date | 옥냥이가 '언제 마리오카트를 했는지' 알 수 있는 날짜 |
| round | 사관 데이터의 1회차 2회차에 해당한다. 몇 번째 게임인지 나타내는 데이터 |
| game_count | N판 합계 R등 이내에서, N판 부분을 나타내는 데이터 |
| game_goal | N판 합계 R등 이내에서, R등 부분을 나타내는 데이터 |
| cur_game_count | N판을 진행한다면 현재 몇 번째 판인지 나타내는 데이터, 1번째 판인지 2번째 판인지 등 |
| win_odds | 성공(승리) 배당률 |
| lose_odds | 실패(패배) 배당률 |
| track_K | 주행한 마리오 카트 맵(경기장), 한글 데이터 |
| track_E | 주행한 마리오 카트 맵(경기장), 영문 데이터 |
| cc | 실제로는 배기량을 나타내는 단어이지만, 마리오 카트에서는 난이도를 표현 |
| part_people | 해당 경기에 참가한 인원 수 |
| rank | 해당 경기에서 기록한 등수 |
| prefix_rank | 한 round에서 rank의 누적 합 |
| odds_result | 경기(배당) 결과, straight up(SU)은 정배를 의미하고 underdog(UD)는 역배를 의미 |
| significant | 특이사항, 옥냥이의 정산 실수라든가 경기 무효라든가 |
| RESULT | 불안전한 놀이터(토토)의 결과, N판 합계 R등을 충족했다면 TRUE 아니라면 FALSE |
각 컬럼에 대한 설명은 위와 같다.
track_K, track_E, siginificant 등 csv 파일을 만들 때 눈여겨 볼(?) 컬럼들이 몇 개 있다.
track의 이름은 반드시 필요하다고 생각했다.
실제로 옥냥이는 빅 블루를 진짜 못한다. 그래서 빅 블루가 선택되면 종종 괴성을 지른다.
하지만 인공지능 학습에 있어서는 영문 데이터가 수월하다.
동시에 맵은 '어떠한 고정 값'이기 때문에 Categorical data로 인코딩 할 수 있다.
그래서 mario_kart_8_course라는 시트를 따로 만들어 맵 이름을 저장했다.

(왼쪽의 엑셀 컬럼을 보면 알겠지만, 11번째 행부터 89번째 행까지는 숨기기를 해서 사진을 캡처했다.)
(별 의미는 없고 그냥 97개의 전체 맵 시작과 끝을 한 사진에 담고 싶어서 중간 부분은 숨겨놨다.)
이렇게 경기장(맵)에 대한 데이터만 따로 빼둔다면 오탈자를 찾기 쉬울 거라고 생각했다.
왜냐하면 한글로 경기장 이름을 작성하면 vlookip 함수로 영문 경기장 이름을 가져온다.
즉 영문 경기장 이름이 안 뜨면, 내가 쓴 한글 경기장이나 mario_kart_8_course의 데이터 중 하나는 오타가 있다는 거다.
동시에 시간 단축 효과도 있다.
본래라면 '마리오 스노 마운틴'이라고 쓰고 옆 칸에 'Mount Mario'라고 또 써야 한다.
하지만 함수로 데이터를 입력하면 '마리오 스노 마운틴' 한 번만 입력하면 된다.
| vlookup_column | 엑셀 vlookup 함수를 사용하여 데이터를 찾기 위해 앞으로 빼낸 컬럼(열) |
| idx | 인덱스 |
| grand_prix_K | 그랑프리 구분, 한글 데이터 |
| grand_prix_E | 그랑프리 구분, 영문 데이터 |
| cup_K | 컵 구분, 한글 데이터 |
| cup_E | 컵 구분, 영문 데이터 |
| track_name_K | 경기장 이름, 한글 데이터 |
| track_name_E | 경기장 이름, 영문 데이터 |
| significant | 특이사항, 위키와 nintendo 공식 사이트의 이름이 다른 점을 기록하는 칸 |
각 컬럼에 대한 설명은 위와 같다.
나중에 어떻게 사용할지 모르기 때문에, 경기장에 대한 정보도 최대한 자세하게 저장하고 싶었다.
그래서 한글과 영문 이름을 전부 기록해 두었고, 언제 추가된 건지(컵 구분)도 기록했다.
significant 컬럼에는 크게 중요하지 않지만 혹시 모를 특이사항을 적어두었다.
예를 들어서 '뻐끔 신전'은 nintendo 공식에서는 'Piranha Plant Cove'라고 쓰여있다.
하지만 위키와 한국 닌텐도 홈페이지에는 'Tour Piranha Plant Cove'라고 쓰여있다.
한 가지로 통일만 하면 되기에 큰 문제는 없지만, 그래도 이 차이점을 남겨두고 싶었다.
또한 위키에는 GC로 적힌 게 공식 홈페이지에는 GCN으로,
위키에 SFC로 적힌 게 공식 홈페이지에는 SNES로 적혀있다는 점을 확인했다.
이런 특이사항을 적은 컬럼이 significant다.

사관 데이터를 csv로 제작하다보니 문제가 발생했다.
옥냥이가 성공/실패로 이진 분류를 한 게 아니라, 등수 예측하기로 놀이터를 연 것이다.

해당 경우의 win_odds, lose_odds는 위처럼 기록해두었다.
또한 odds_result, significant, RESULT는 우선 비워두었다.
significant에 특정 순위 정확하게 예측하기란 의미로 ACC를 기록해두고, 나중에 행을 drop할까 고민 중이다.
내가 만들고 싶은 예측기는 가능/불가능 이진 분류기지, 단판 특정 순위 예측이 아니다.
동시에 단판 예측 기록기도 만들어둘까? 라는 생각이 든다.
어쨋든 이건 어떻게 처리할지 조금 더 고민해봐야 겠다.

사관 데이터를 전부 입력했다. 490 * 17 크기의 csv 파일을 만들었다.
그중에서 발생한 예외 데이터들은 다음과 같다.
1. MISS: 옥냥이가 정산을 실수한 경우
2. ACC: 성공/실패 여부를 배팅하는 것이 아닌, 정확한 등수를 배팅하는 경우
3. CANCEL: 약관을 어겨 불안전한 놀이터를 재개장한 경우
4. game_count - under n: 성공/실패 여부는 맞지만, 합계가 아닌 N판 이내 R등 가능인 경우
5. NOT OPEN: 옥냥이가 놀이터를 개장하지 않은 경우
6. NaN: 다시보기 혹은 유튜브에 올라오지 않은 영상인데, 사관님께서 생방송 도중 놓쳐 결측치가 된 경우
사관 데이터를 보다가 문득, 모든 기록을 적었다기에는 적다는 생각이 들었다.
내 야심한 밤 숙면을 책임져줬던 그 영상들이 고작 이정도 데이터로 끝날리가 없다고 느꼈기 때문이다.
그래서 올냥이에 들어가서 직접 사관님의 데이터와 누락된 부분을 비교해보았다.
최초의 사관 데이터 날짜 이전(2021년 영상들 기준)으로
6월 - 9일, 11일, 16일, 17일, 22일, 23일
7월 - 8일, 12일, 13일, 19일, 27일, 28일, 30일
8월 - 2일, 3일, 9일, 23일
9월 - 2일, 6일, 23일
10월 - 8일
12월 - 17일, 30일,
추가로 2022년 4월 12일의 영상이 없었고,
마지막 사관 데이터 날짜 (2023년 8월 22일) 이후로는
2023년 8월 21일, 9월 21일, 10월 23일, 12월 5일, 12월 22일
2024년 2월 27일의 영상들이 없었다.
이를 보면 2022년부터 사관님께서 영상을 기록하신 것을 알 수 있다.
2022년부터 2024년까지의 데이터는 그래도 그렇게 많지는 않은데...
2021년의 데이터는 너무 방대해서 추가하기까지 시간이 너무 오래 걸릴 듯하다.
누락된 몇몇의 데이터들을 어디까지 추가할지는 고민해봐야 겠다.