SQL Window functions
CREATE TABLE employees (
emp_no INT PRIMARY KEY AUTO_INCREMENT,
department VARCHAR(20),
salary INT
);
INSERT INTO employees (department, salary) VALUES
('engineering', 80000),
('engineering', 69000),
('engineering', 70000),
('engineering', 103000),
('engineering', 67000),
('engineering', 89000),
('engineering', 91000),
('sales', 59000),
('sales', 70000),
('sales', 159000),
('sales', 72000),
('sales', 60000),
('sales', 61000),
('sales', 61000),
('customer service', 38000),
('customer service', 45000),
('customer service', 61000),
('customer service', 40000),
('customer service', 31000),
('customer service', 56000),
('customer service', 55000);밑에서 다루는 window function들은 전부 위의 table을 바탕으로 조회한 결과다.
-- Window Functions
-- https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
-- Explain)
-- Window functions perform aggregate operations on groups of rows,
-- but they produce a result FOR EACH ROW
SELECT department, AVG(salary) FROM employees GROUP BY department;
SELECT AVG(salary) FROM employees;Window function은 각 행에 대해서 집계를 해주는 함수다.
쉽게 말하면 집계 함수(aggregate function)을 묶지 않고, 각 행마다 적용하는 것이다.
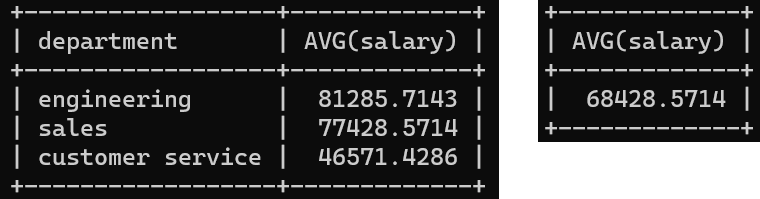
집계 함수를 예를 들어보면 위와 같은 결과를 보인다.
department를 기준을 GROUP BY를 하여 AVG를 구한 결과, 그리고 전체를 AVG한 결과다.
이런 식으로 '집계 함수(agg func)'는 특정 집단을 묶어서 결과를 뱉는다.
-- OVER
-- The OVER() clause constructs a window.
-- When it's empty, the window will include all records.
SELECT emp_no, department, salary, AVG(salary) OVER() FROM employees;
Window function 중 OVER() 함수를 사용하면, 각 행에 대해서 연산을 수행한다.
'window'가 붙은 이유는 각 묶음을 window라고 부르기 때문이다.
OVER() 괄호 안에 아무런 조건을 넣지 않으면, 모든 행을 범위로 계산한다.

가장 우측에 보이는 열은 AVG(salary) OVER()를 수행한 결과다.
OVER()에 아무런 조건을 넣지 않아, 모든 행을 범위로 평균을 구하고, 모든 행에 결과를 적용한다.
-- PARTITION BY
-- Inside of the OVER(), use PARTITION BY to form rows into groups of row
SELECT
emp_no,
department,
salary,
AVG(salary) OVER(PARTITION BY department) AS dept_avg
FROM employees;OVER() 내에 window 범위를 지정해주는 PARTITION BY 함수다.
PARTITION BY 'col_name' 형태로 적으면 col_name에 따라서 window로 묶어서 계산한다.
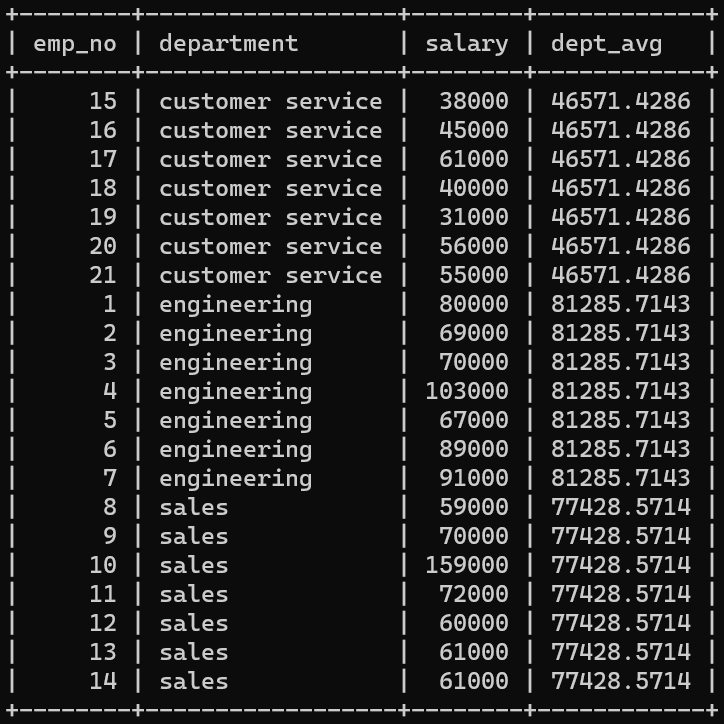
PARTITION BY department를 조건으로 넣어, 같은 department끼리 salary의 평균을 구한다.
customer sevice끼리, engineering끼리, sales끼리의 salary 평균을 구하여 각 행에 적용한다.
SELECT
emp_no,
department,
salary,
AVG(salary) OVER(PARTITION BY department) AS dept_avg,
AVG(salary) OVER() AS company_avg
FROM employees;
SELECT
emp_no,
department,
salary,
MIN(salary) OVER(PARTITION BY department) AS dept_min,
MAX(salary) OVER(PARTITION BY department) AS dept_max
FROM employees;
SELECT
emp_no,
department,
salary,
AVG(salary) OVER(PARTITION BY department) AS dept_avg,
COUNT(department) OVER(PARTITION BY department) AS team
FROM employees;AVG(), MIN(), MAX(), COUNT() 같은 집계 함수를, OVER(), PARTITION BY로 작성한 예제 구문들이다.
첫 번째 구문은 department를 window로 salary 평균을 구하고, 전체 salary의 평균을 구한다.
두 번째 구문은 department를 window로 가장 작은 salary와 가장 큰 salary를 구한다.
세 번째 구문은 department를 window로 salary 평균을 구하고, department를 window로 개수를 구한다.
-- ORDER BY
-- Use ORDER BY inside of the OVER() clause to re-order rows within each window.
SELECT
emp_no,
department,
salary,
SUM(salary) OVER(PARTITION BY department ORDER BY salary) AS rolling_dept_salary,
SUM(salary) OVER(PARTITION BY department) AS total_dept_salary
FROM employees;ORDER BY는 window를 정렬한다. DESC와 ASC 모두 가능하다.

SUM(salary) OVER(PARTITION BY department ORDER BY salary) AS rolling_dept_salary 구문이다.
자세히보면 SUM(salary) 부분이 특이하게 동작한다.
ORDER BY에 의해 정렬한 다음, 각 행이 늘어날 때마다 추가적으로 더해주는 모습이다.
첫 번째 행은 31000, 두 번째 행은 69000, 세 번째 행은 109000처럼 말이다.
-- Only window functions
-- https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
-- RANK()
SELECT
emp_no,
department,
salary,
RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_rank,
RANK() OVER(ORDER BY salary DESC) AS overall_salary_rank
FROM employees
ORDER BY department;ORDER BY()는 굳이 window function이 아니더라도, 사용할 수 있는 함수다.
RANK()는 오직 window function으로만 사용할 수 있는 함수 중 하나이다.
이런 함수들은 https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html에서 확인할 수 있다.
RANK()는 해당 값이 몇 위인지 알려준다. 이때 동순위가 있으면 다음 순위는 그만큼 건너뛴다.

왼쪽에서부터 4번째 열은 RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_rank다.
department끼리 window로 묶어서 salary를 기준으로 순위를 매겼다.
이때 sales의 순위를 보면, 1 2 3 4 4 6 7순으로 붙은 것을 확인할 수 있다.
-- ROW_NUMBER()
SELECT
emp_no,
department,
salary,
ROW_NUMBER() OVER(PARTITION BY department ORDER BY salary DESC) as 'row_number',
RANK() OVER(PARTITION BY department ORDER BY salary DESC) as dept_salary_rank,
RANK() OVER(ORDER BY salary DESC) as overall_salary_rank
FROM employees
ORDER BY department;ROW_NUMBER() 또한 오직 window function으로만 동작한다.
함수명 그대로 몇 번째 행인지 알려준다.
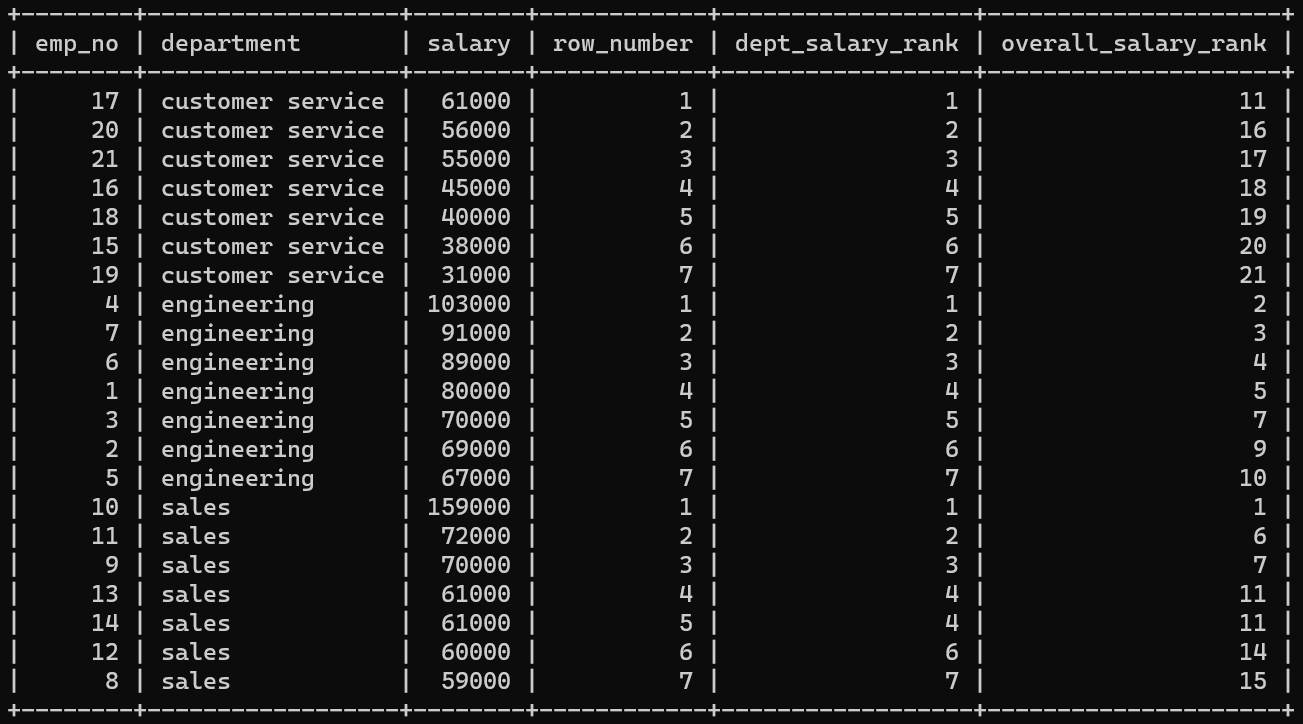
row_number로 이름이 붙은 열을 보면, department를 window로 묶어 위에서부터 행을 적은 것을 볼 수 있다.
-- DENSE_RANK()
SELECT
salary,
ROW_NUMBER() OVER s AS 'row-number',
RANK() OVER s AS 'rank',
DENSE_RANK() OVER s AS 'dense_rank'
FROM employees
WINDOW s AS (ORDER BY salary);DESNE_RANK()는 RANK()처럼 순위를 반환해주지만, 동순위가 있어도 다음 순위는 그대로 이어서 알려준다.
참고로 window function은 위와 같은 형태로도 작성할 수 있다.

ROW_NUMBER(), RANK(), DENSE_RANK()를 비교하기 위해 작성한 코드 예제다.
ROW_NUMBER()는 행 자체 번호를 반환한다.
RANK()는 순위를 반환하되, 동순위가 있다면 다음 순위를 그만큼 건너뛰고 반환한다.
DENSE_RANK()는 순위를 반환하되, 동순위가 있어도 다음을 바로 이어서 반환한다.
-- NTILE()
SELECT
emp_no,
department,
salary,
NTILE(4) OVER(ORDER BY salary DESC) AS salary_quantile
FROM employees;
SELECT
emp_no,
department,
salary,
NTILE(4) OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_quantile
FROM employees;NTILE()은 전체를 N개로 나누고 어떤 분위에 속하는지 확인하는 함수다.
N이 4라면 상위 25%, 상위 50%, 상위 75%, 상위 100%로 나누어, 어디에 속하는지 알려준다는 말이다.
또 다른 예로 N을 100으로 설정하면 백분율을 알 수 있다.

왼쪽은 첫 번째 구문으로, 전체를 NTILE(4)한 다음 salary를 기준으로 DESC 정렬을 한 결과다.
오른쪽은 두 번째 구문으로, department로 window를 나누고 NTILE(4)를 한 결과다.
-- FIRST_VALUE() LAST_VALUE(), Nth_VALUE()
SELECT
emp_no,
department,
salary,
FIRST_VALUE(emp_no) OVER(PARTITION BY department ORDER BY salary DESC) AS highest_dept_salary,
LAST_VALUE(emp_no) OVER(PARTITION BY department ORDER BY salary DESC) AS lowest_dept_salary,
Nth_VALUE(emp_no, 2) OVER(PARTITION BY department ORDER BY salary DESC) AS '2th_dept_salary'
FROM employees;FIRST_VALUE()는 특정 window에서 첫 번째 나온 값이 무엇인지 알려준다.
LAST_VALUE()는 특정 window에서 마지막에 나온 값이 무엇인지 알려준다.
Nth_VALUE()는 특정 window에서 N번째로 나온 값이 무엇인지 알려준다.

department를 기준으로 window를 나누고, salary의 FIRST_VALUE(), LAST_VALUE(), 2th_VALUE()를 확인한다.
FIRST_VALUE()는 가장 처음에 나온 값을 반환하기에, 숫자가 고정인 것을 알 수 있다.
LAST_VALUE()는 가장 마지막에 나온 값을 반환하기에, 새로운 행을 window에 포함할수록 바뀌는 것을 알 수 있다.
2th_VALUE()는 2번째 값을 반환하기에, 가장 첫 행에서는 NULL을 반환하는 것을 알 수 있다.
-- LAG(bef), LEAD(aft)
SELECT
emp_no,
department,
salary,
salary - LEAD(salary) OVER(ORDER BY salary DESC) AS salary_diff_by_aft,
LAG(salary) OVER(ORDER BY salary DESC) AS bef_salary
FROM employees;
SELECT
emp_no,
department,
salary,
salary - LAG(salary) OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_diff_bef,
salary - LEAD(salary) OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_diff_aft
FROM employees;
SELECT
emp_no,
department,
salary,
LAG(salary, 2) OVER(ORDER BY salary DESC) AS bef_salary
FROM employees;LAG() 함수는 바로 직전의 값이 무엇이었는지 알려준다.
LEAD() 함수는 바로 직후의 값이 무엇일지 알려준다.
LAG(), LEAD() 함수 모두 2번째 매개변수로 N을 넘겨주면, N번째 앞 혹은 뒤의 값을 알려준다.
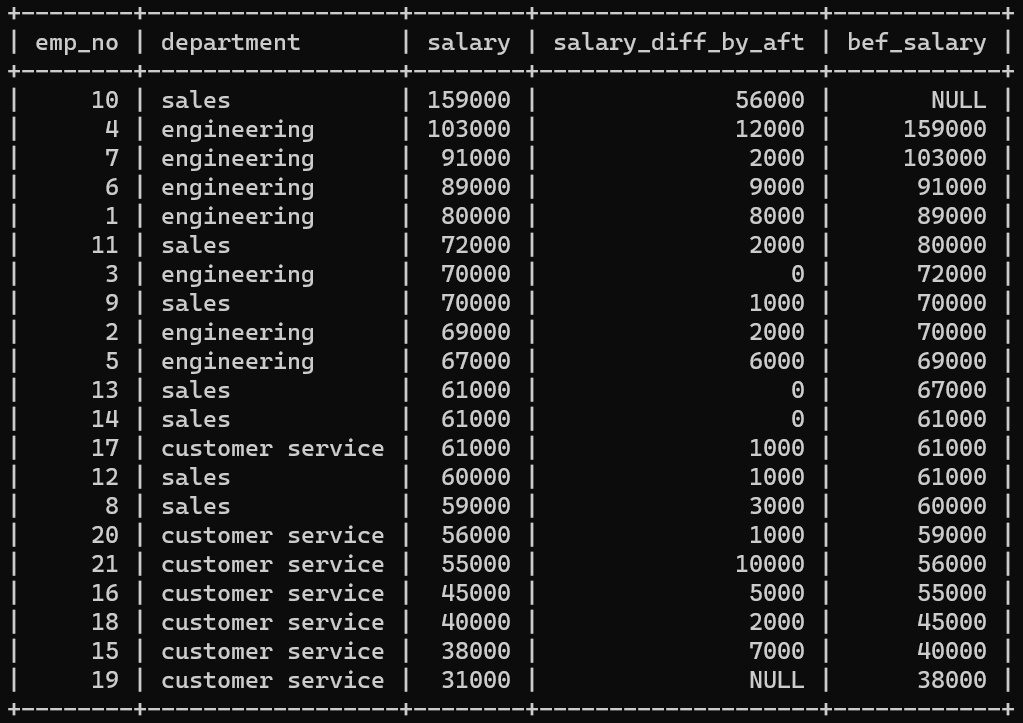
위의 결과는 3개의 구문 중 첫 번째 구문을 실행한 결과다.
왼쪽에서부터 4번째 행은 salary - LEAD(salary) OVER(ORDER BY salary DESC) AS salary_diff_by_aft 구문이다.
salary를 기준으로 DESC 한 다음, 전체를 window로 보고, 현재 값에서 바로 다음 값을 뺸 값을 보여준다.
가장 오른쪽 끝 행은 LAG(salary) OVER(ORDER BY salary DESC) AS bef_salary 구문이다.
salary를 기준으로 DESC 한 다음, 전체를 window로 보고 바로 이전 값을 보여준다.
이처럼 정렬 기준을 여러 번 선언할 수 있다. 이때는 가장 마지막에 선언한 것을 기준으로 정렬한다.